
文章目录
一、AlertManager 介绍
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。

在Prometheus中一条告警规则主要由以下几部分组成:
告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
1.1 Alertmanager特性
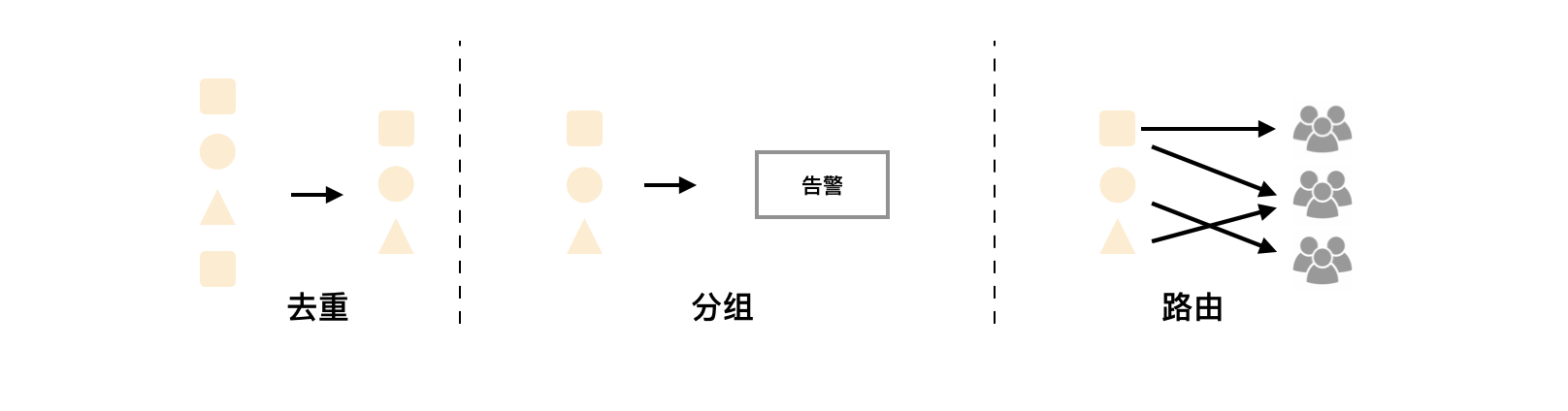
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性:
-
分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。 -
抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。 -
静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
首先我们要保证node_exporter已经添加到监控中,才可以继续下面的步骤
基于下面文章进行搭建

二、企业微信告警设置
创建企业微信公众号可以参考下面的文章

三、AlertManager 安装
部署Alertmanager目前包含二进制包、容器以及源码方式安装,官方推荐使用docker容器运行,这里默认我就安装docker容器运行
AlertManager配置文件编写
mkdir /etc/prometheus/alertmanager
vim /etc/prometheus/alertmanager/config.yml
global:
resolve_timeout: 5m
http_config:
follow_redirects: true
smtp_hello: localhost
smtp_require_tls: true
pagerduty_url: 'https://events.pagerduty.com/v2/enqueue'
opsgenie_api_url: 'https://api.opsgenie.com/'
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/ '
wechat_api_corp_id: wwcxxxxxxxx #企业id
victorops_api_url: 'https://alert.victorops.com/integrations/generic/20131114/alert/'
route:
receiver: abcdocker #对应下面receivers中的name
continue: false
group_wait: 30s
group_interval: 3m
repeat_interval: 3m
receivers:
- name: abcdocker
wechat_configs:
- send_resolved: true
http_config:
follow_redirects: true
api_secret: f2xxxxx # 申请企业微信应用后生成的密码
corp_id: wwc1xxx
message: '{{ template "wechat.default.message" . }}'
api_url: https://qyapi.weixin.qq.com/cgi-bin/
to_user: CongYuHong #发送到某一用户也可以 @all 就是群组全员发送
to_party: '{{ template "wechat.default.to_party" . }}'
to_tag: '{{ template "wechat.default.to_tag" . }}'
agent_id: "1000004" #申请企业微信应用id
message_type: text
templates:
- /etc/alertmanager/template/*.tmpl #告警模板路径参数详解
resolve_timeout #该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved
follow_redirects: true #配置抓取请求是否遵循HTTP 3xx重定向。
route:
receiver: abcdocker #对应下面receivers中的name
continue: false #如果route中设置continue的值为false,那么告警在匹配到第一个子节点之后就直接停止。如果continue为true,报警则会继续> 进行后续子节点的匹配。如果当前告警匹配不到任何的子节点,那该告警将会基于当前路由节点的接收器配置方式进行处理
group_wait: 30s #通过group_wait参数设置等待时间,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送
group_interval: 3m #group_interval配置,则用于定义相同的Group之间发送告警通知的时间间隔
repeat_interval: 3m #如果警报已经成功发送通知, 如果想设置发送告警通知之前要等待时间,则可以通过repeat_interval参数进行设置。receivers:
- name: abcdocker #对应上面receivers中的name
wechat_configs: #wechat 微信模板
- send_resolved: true #恢复告警
http_config:
follow_redirects: true #配置抓取请求是否遵循HTTP 3xx重定向
templates:- /etc/alertmanager/template/*.tmpl #告警模板路径
编写发送企业微信告警模板
mkdir /etc/prometheus/alertmanager/template -p
vim /etc/prometheus/alertmanager/template/WeChat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********告警通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********恢复通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
恢复时间: {{ $alert.EndsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- end }}docker运行alertmanager,这里我挂载写的是目录,因为告警格式也需要挂载下
docker run -d -p 9103:9093 --name alertmanager
-v /etc/prometheus/alertmanager:/etc/alertmanager
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime
docker.io/prom/alertmanager:latest
--config.file=/etc/alertmanager/config.yml
#由于时区问题,我们将alertmanager时区挂载为上海安装完alertmanager可以直接访问 IP:9013
点击Status可以看到alertmanager状态和配置文件
四 、告警规则设置
创建我们创建目录 (最好和prometheus配置文件在一个目录)
mkdir /etc/prometheus/rules #创建高级规则目录接下来我们添加Node exporter告警规则
[root@prometheus rules]# vim /etc/prometheus/rules/node_exporter.yaml
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up == 0
for: 1m
labels:
status: 很是严重
annotations:
summary: "{{$labels.instance}}:服务器宕机"
description: "{{$labels.instance}}:服务器延时超过5分钟"
- alert: CPU使用状况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: 通常告警
annotations:
summary: "{{$labels.mountpoint}} CPU使用率太高!"
description: "{{$labels.mountpoint }} CPU使用大于60%(目前使用:{{$value}}%)"
- alert: 内存使用
expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 内存使用率太高!"
description: "{{$labels.mountpoint }} 内存使用大于80%(目前使用:{{$value}}%)"
- alert: IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率太高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽太高!"
description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: 网络
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽太高!"
description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED太高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率太高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"后续如果我们还需要添加别的告警,我们可以直接在
/etc/prometheus/rules目录下单独创建一个yaml设置告警即可
五、Prometheus 集成 AlertManager

我们需要重新修改Prometheus容器,将/etc/prometheus整个挂载到prometheus容器上去
docker run -d -p 9090:9090
--restart=always
--name prometheus
-v /data/prometheus:/data/prometheus
-v /etc/prometheus:/etc/prometheus/
registry.cn-beijing.aliyuncs.com/abcdocker/prometheus:v2.18.1
--config.file=/etc/prometheus/prometheus.yml
--storage.tsdb.path=/data/prometheus
--web.enable-admin-api
--web.enable-lifecycle
--storage.tsdb.retention.time=30d接下来是prometheus配置文件的修改
vim /etc/prometheus/prometheus.yml
rule_files:
- 'rules/*.yaml'
#添加告警规则路径,我这里使用了docker 挂载并且prometheus.yaml和rules是同一个目录,所以直接写相对路由,也可以写成绝对路径Prometheus 配置文件添加alertmanager地址
alerting:
alertmanagers:
- static_configs:
- targets: ['10.0.24.13:9103'] #alertmanager地址+端口号完整配置文件如下
global:
scrape_interval: 60s
evaluation_interval: 20s
scrape_timeout: 15s
rule_files:
- 'rules/*.yaml'
scrape_configs:
- job_name: abcdocker_node
scrape_interval: 3s
static_configs:
- targets: ['11111:9090']
labels:
instance: prometheus-server
- targets: ['11111.frps.cn']
labels:
instance: 博客服务器
- targets: ['1.1.1.61:9100']
labels:
instance: ukx服务器
- targets: ['1.1.1.1:9100']
labels:
instance: 海外下载站
- targets: ['82.157.142.150:9100']
labels:
instance: frp服务器
alerting:
alertmanagers:
- static_configs:
- targets: ['10.0.24.13:9103']修改完配置文件,重启prometheus,我们就可以在Alert中看到监控项了
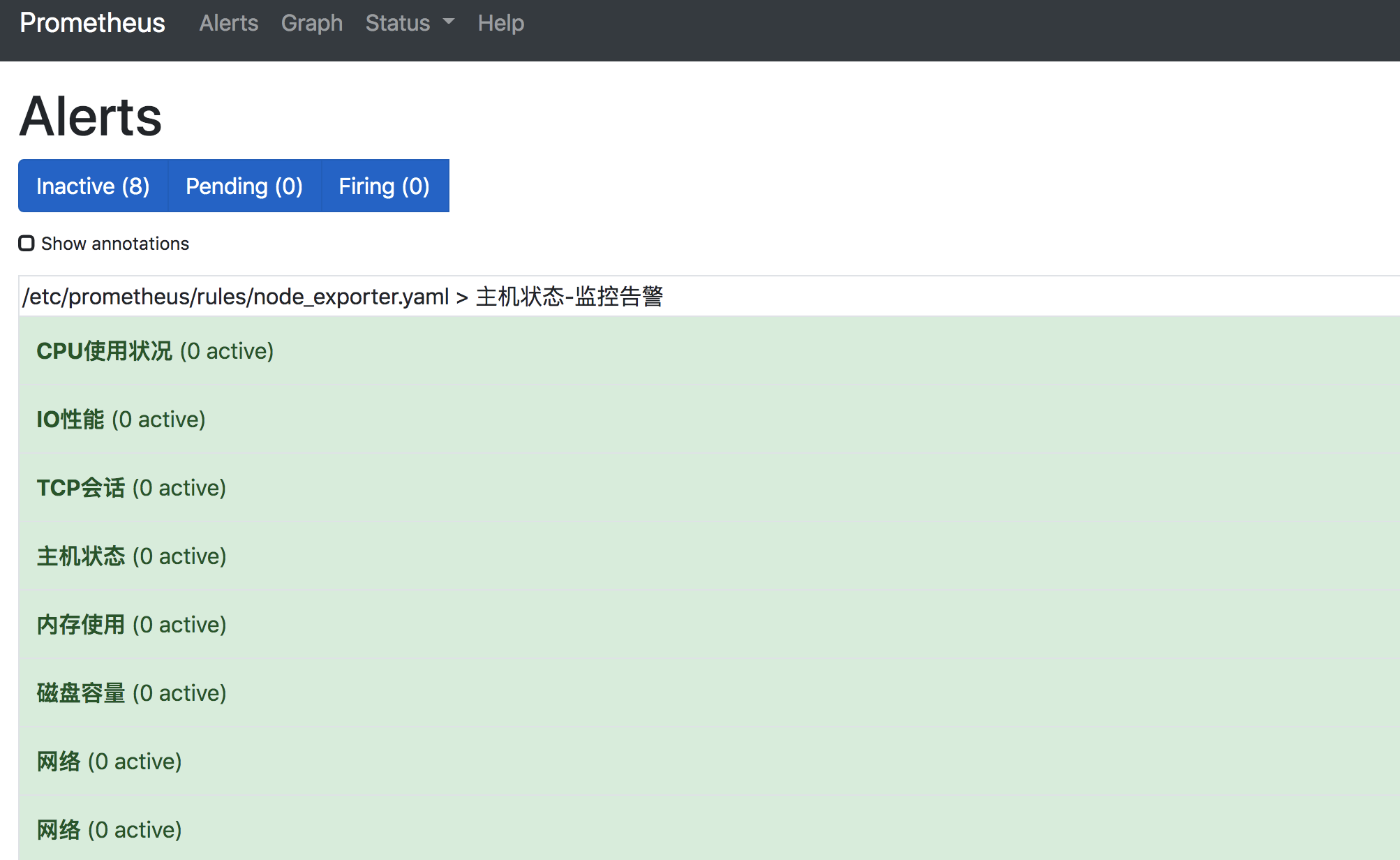
并且也可以看到Rules告警模板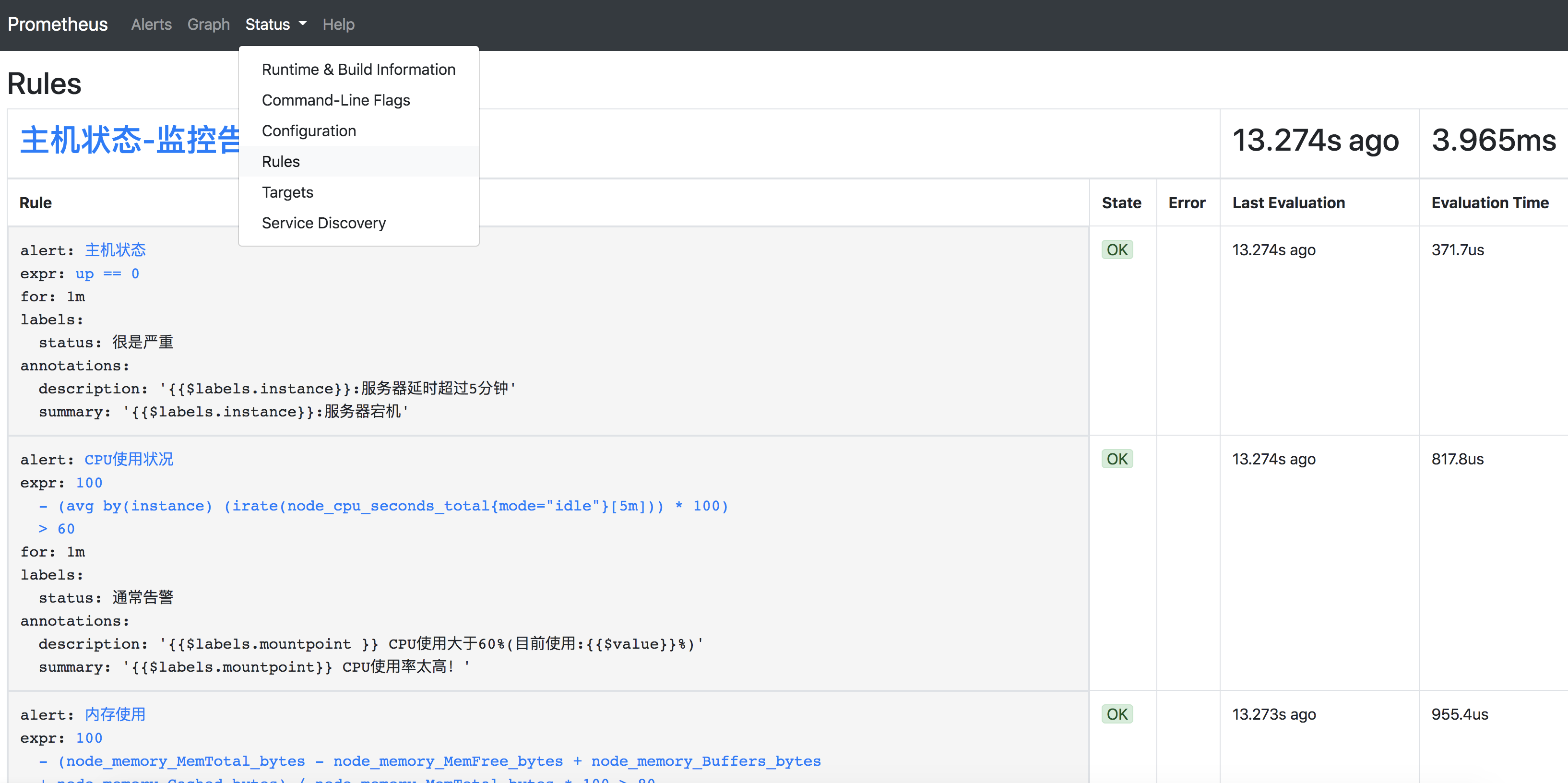
六、应用测试
出发告警,我这边停止node_exporter进行测试
最先失败的为prometheus中targets
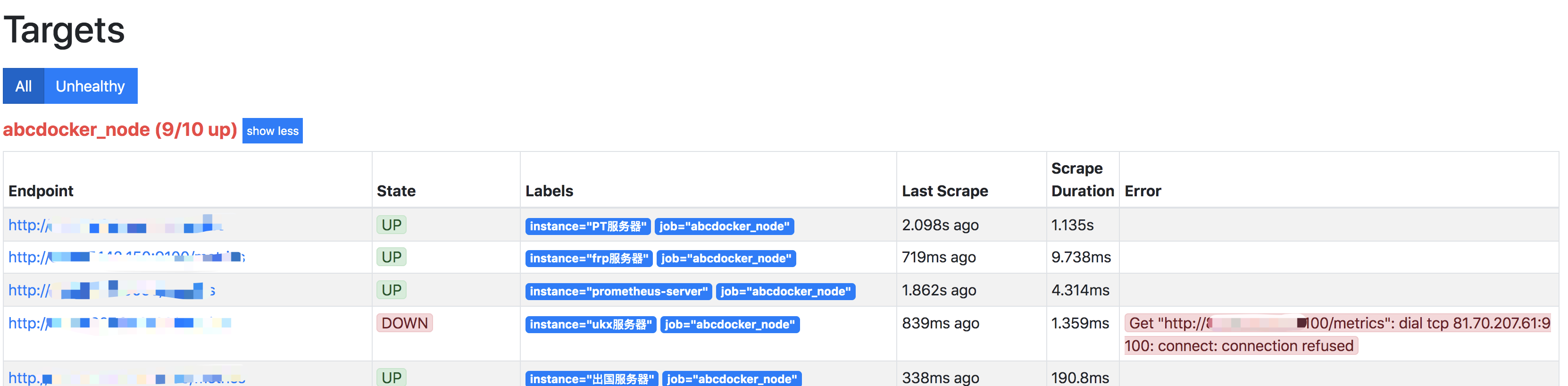
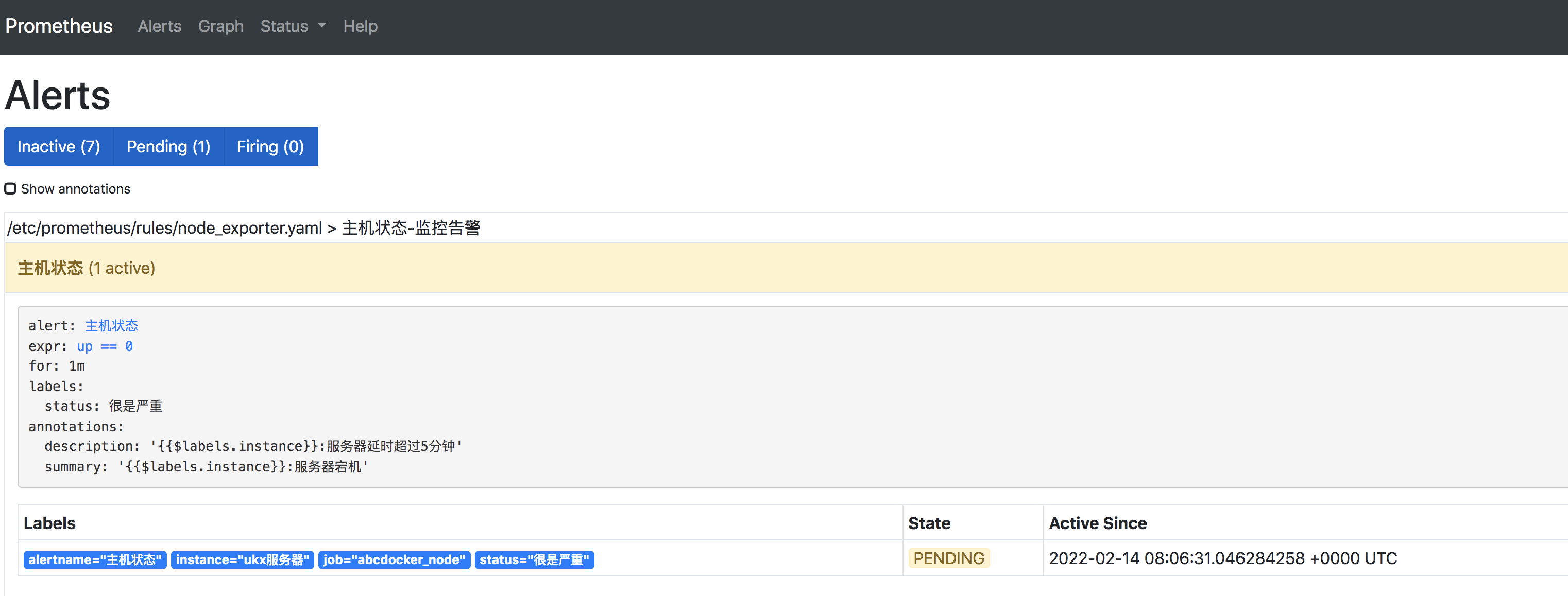
Rules马上进行告警等待状态
数秒过后,进行失败告警状态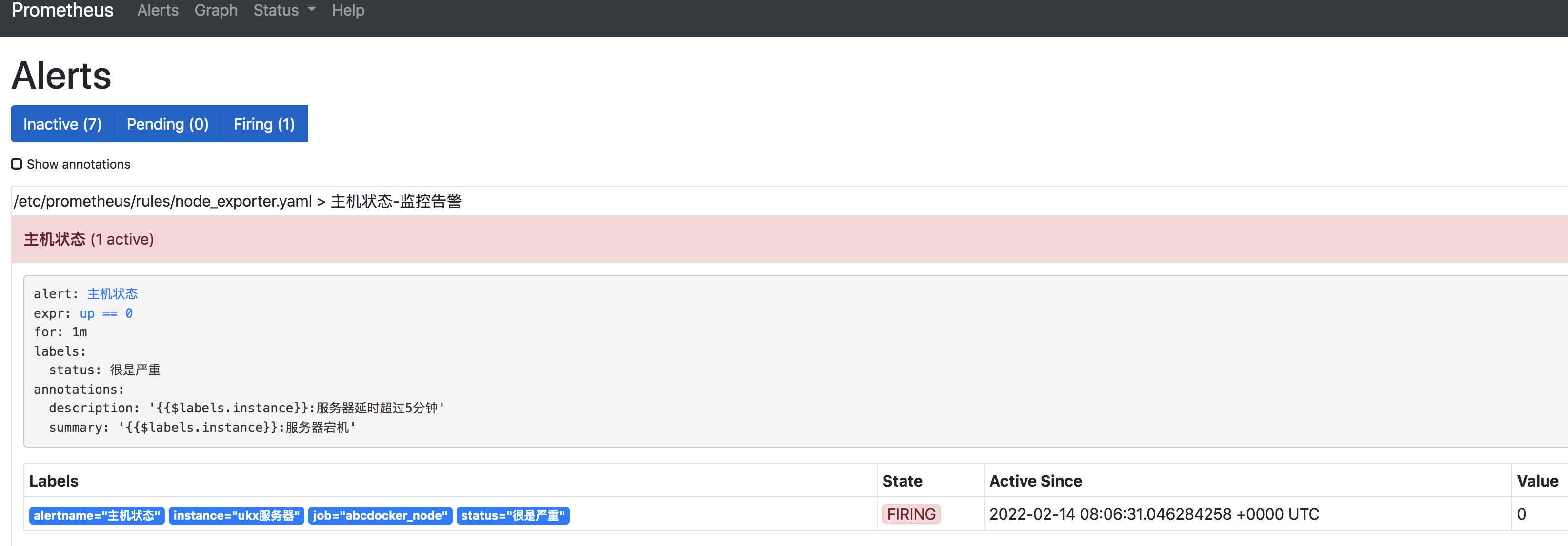
alertmanager开始进行告警状态
接下来触发器按照告警模板发送微信提醒,当故障告警恢复时也会发送邮件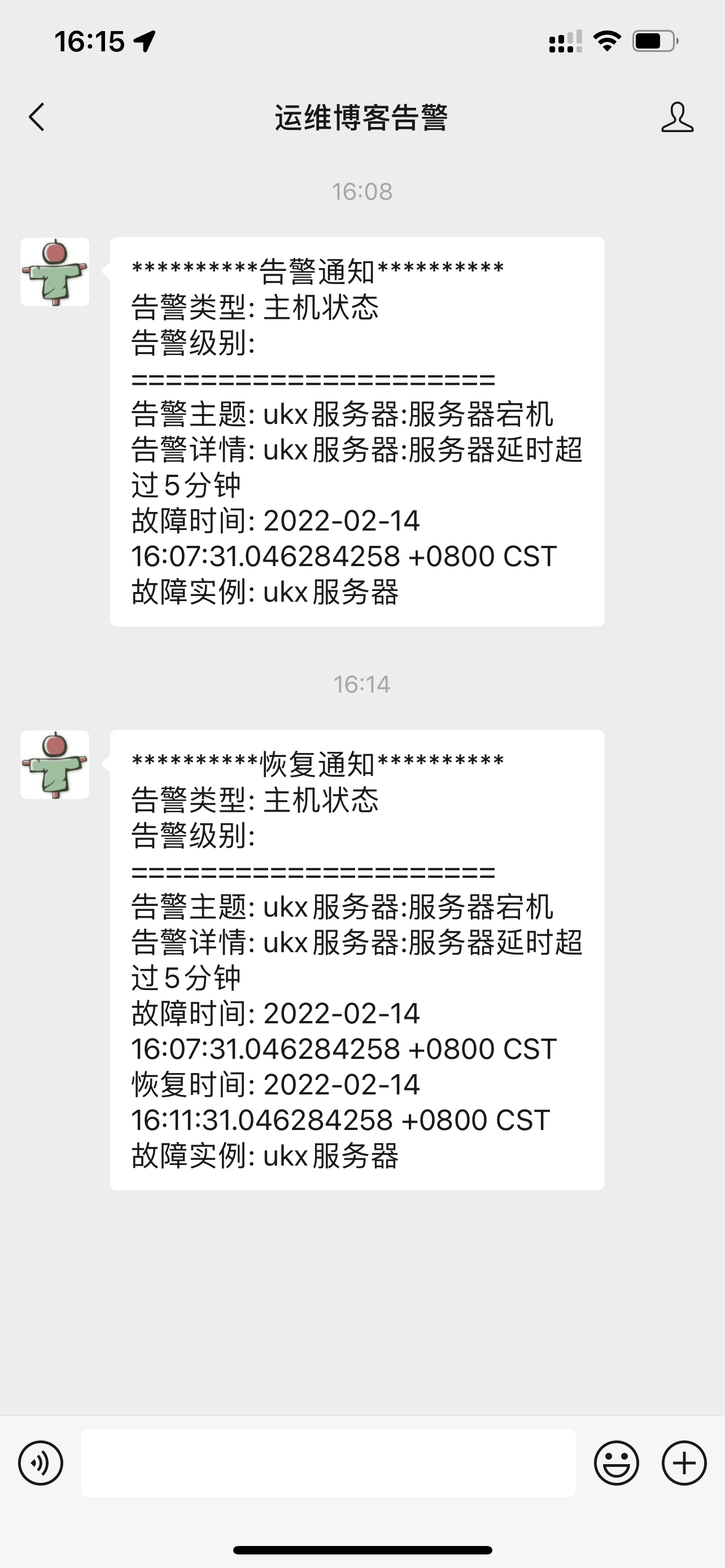


[…] AlertManager 微信告警配置 […]
[…] […]
[…] alertmanager搭建可以看下面的文章 https://i4t.com/5260.html […]
[…] alertmanager安装可以看下面文章,我这直接提供规则 https://i4t.com/5260.html […]