
Prometheus AlertManager 钉钉报警
Prometheus
之前介绍过使用email报警,prometheus alertmanager是支持钉钉以及企业微信报警的,这里暂时使用钉钉告警
由于本人不会Python脚本,这里所使用的Python脚本目录之前可以将告警输出,没有进行优化
我这里使用Secret 来保存钉钉的TOKEN
Secret是用来保存小片敏感数据的k8s资源,例如密码,token,或者秘钥。这类数据当然也可以存放在Pod或者镜像中,但是放在Secret中是为了更方便的控制如何使用数据,并减少暴露的风险。
首先先获取钉钉群组token
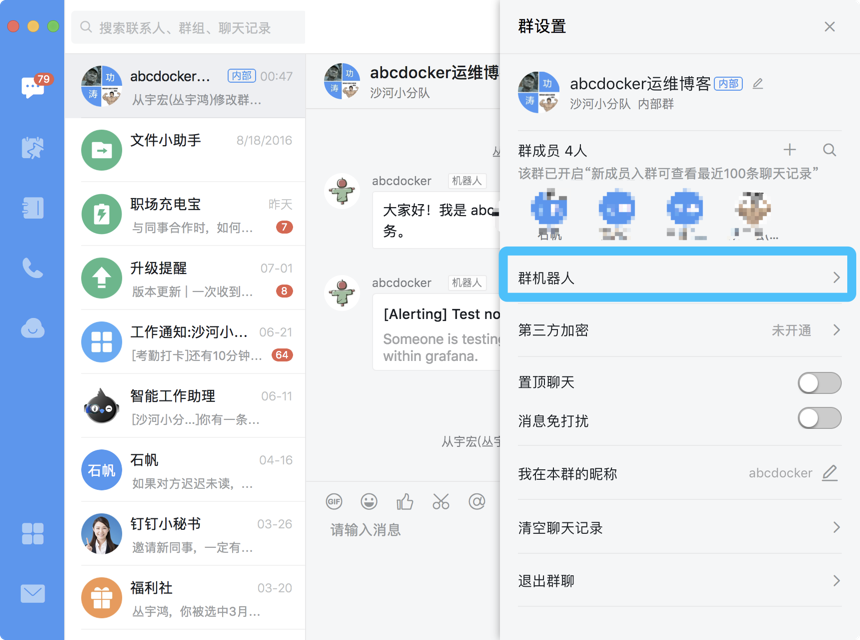
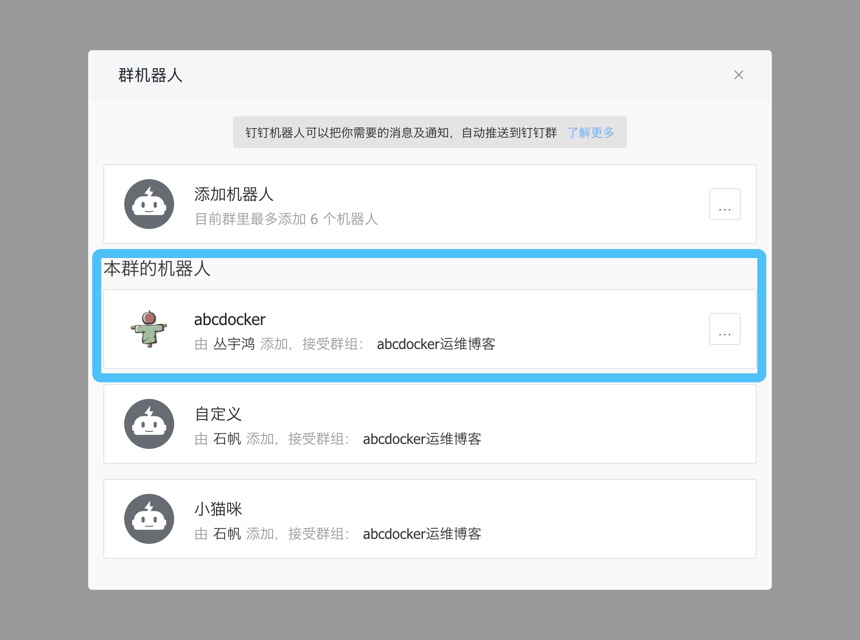
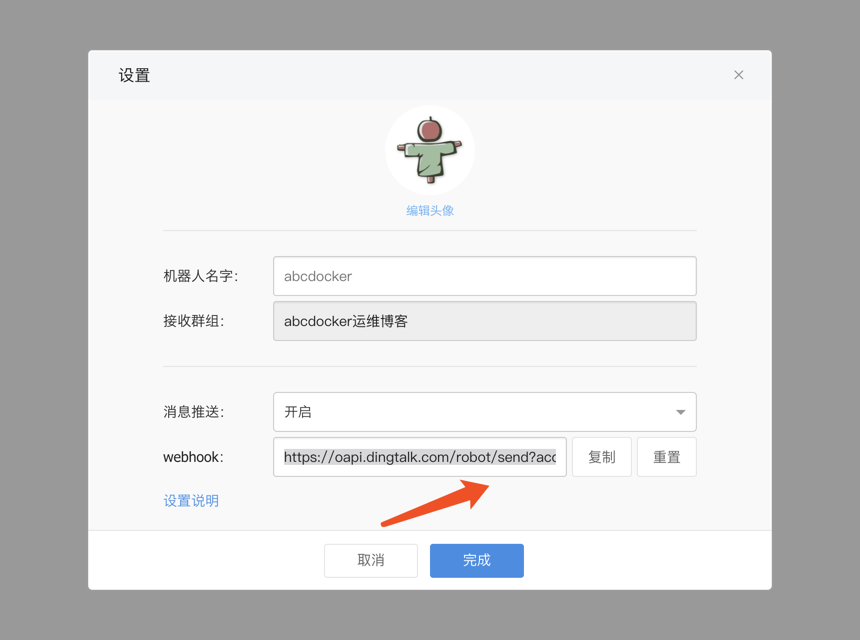
在access_token=后面的就是我们需要的token,我们需要保存
https://oapi.dingtalk.com/robot/send?access_token=cde1b4fxxxxxxxxxxxxxx
接下来我们到k8s中,创建Secret
kubectl create secret generic abcdocker-dingding -n kube-system --from-literal=token=替换成钉钉群聊的机器人TOKEN #创建完毕后,我们可以查看一下 [root@abcdocker prometheus]# kubectl get secret -n kube-system |grep abcdocker abcdocker-dingding Opaque 1 17s
创建完Secret之后,我们创建Deployment和Service
cat > abcdocker-dingding-hook.yaml <<EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: abcdocker-dingding-hook
namespace: kube-system
spec:
template:
metadata:
labels:
app: abcdocker-dingding-hook
spec:
containers:
- name: abcdocker-dingding-hook
image: registry.cn-beijing.aliyuncs.com/abcdocker/prometheus:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5000
name: http
env:
- name: ROBOT_TOKEN
valueFrom:
secretKeyRef:
name: abcdocker-dingding
key: token
resources:
requests:
cpu: 50m
memory: 100Mi
limits:
cpu: 50m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: abcdocker-dingding-hook
namespace: kube-system
spec:
selector:
app: abcdocker-dingding-hook
ports:
- name: hook
port: 5000
targetPort: http
EOF
这里要说一下,需要先创建Secret然后在通过deployment的yaml文件挂在上去
[root@abcdocker prometheus]# kubectl create -f abcdocker-dingding-hook.yaml deployment.extensions/abcdocker-dingding-hook created service/abcdocker-dingding-hook created 接下来我们检查一下pod是否正常启动 [root@abcdockerprometheus]# kubectl get pod -n kube-system |grep abc abcdocker-dingding-hook-5b7696cd4f-6fdlw 1/1 Running 0 25s 我们可以通过日志查看webhook状态 [root@abcdocker prometheus]# kubectl get pod -n kube-system |grep abcdocker abcdocker-dingding-hook-5b7696cd4f-6fdlw 1/1 Running 0 17m [root@abcdocker prometheus]# kubectl logs -n kube-system abcdocker-dingding-hook-5b7696cd4f-6fdlw abcdocker-dingding-hook * Serving Flask app "app" (lazy loading) * Environment: production WARNING: Do not use the development server in a production environment. Use a production WSGI server instead. * Debug mode: off * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
现在我们钉钉报警已经配置完毕了,但是还需要配置触发器。因为光有环境没啥用
#首先在alertmanager上配置一个路由接收器
- receiver: webhook
match:
cpu: node
...
- name: 'webhook'
webhook_configs:
- url: 'http://abcdocker-dingding-hook:5000'
send_resolved: true
以上是添加的参数,下面文件是我prometheus-alertmanager完整配置
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-system
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'new_oldboy@163.com'
smtp_auth_username: 'new_oldboy@163.com'
smtp_auth_password: 'cyh521'
smtp_hello: '163.com'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
group_wait: 10s
match:
team: node
- receiver: webhook
match:
cpu: node
receivers:
- name: 'default'
email_configs:
- to: '604419314@qq.com'
send_resolved: true
- name: 'email'
email_configs:
- to: '604419314@qq.com'
send_resolved: true
- name: 'webhook'
webhook_configs:
- url: 'http://abcdocker-dingding-hook:5000'
send_resolved: true
除了alertmanager配置文件需要修改,我们的prometheus.configmap也需要,监控指标是在prometheus.configmap上定义
#添加如下配置
- alert: NodeMemoryUsage
expr: sum(sum by (container_name)( rate(container_cpu_usage_seconds_total{image!=""}[1m] ) )) / count(node_cpu_seconds_total{mode="system"}) * 100 > 2
for: 1m
labels:
cpu: node
annotations:
summary: "{{$labels.instance}}: High NodeCpu usage detected"
description: "{{$labels.instance}}: NodeCpu usage is above 2% (current value is: {{ $value }}"
完整配置如下
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
rule_files:
- /etc/prometheus/rules.yml
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'redis'
static_configs:
- targets: ['redis.abcdocker.svc.cluster.local:9121']
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
rules.yml: |
groups:
- name: test-rule
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 50
for: 1m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 50% (current value is: {{ $value }}"
- alert: NodeMemoryUsage
expr: sum(sum by (container_name)( rate(container_cpu_usage_seconds_total{image!=""}[1m] ) )) / count(node_cpu_seconds_total{mode="system"}) * 100 > 2
for: 1m
labels:
cpu: node
annotations:
summary: "{{$labels.instance}}: High NodeCpu usage detected"
description: "{{$labels.instance}}: NodeCpu usage is above 2% (current value is: {{ $value }}"
接下来我们来更新2个configmap文件,alertmanager和prometheus都支持热更新
kubectl delete -f prometheus-alert-conf.yaml kubectl create -f prometheus-alert-conf.yaml kubectl delete -f prometheus.configmap.yaml kubectl create -f prometheus.configmap.yaml 配置完毕更新完毕后,我们直接reload [root@abcdocker prometheus]# kubectl get svc -n kube-system |grep prometheus prometheus NodePort 10.96.163.206 9090:32567/TCP,9093:31212/TCP 2d8h #通过查看svc的IP及端口进行reload curl -X POST "http://10.96.163.206:9093/-/reload" curl -X POST "http://10.96.163.206:9090/-/reload" #这里需要注意的是多reload几次
没有报错后,我们打开prometheus的alerts,下面可以看到有nodeCpuusage
目前是属于等待状态
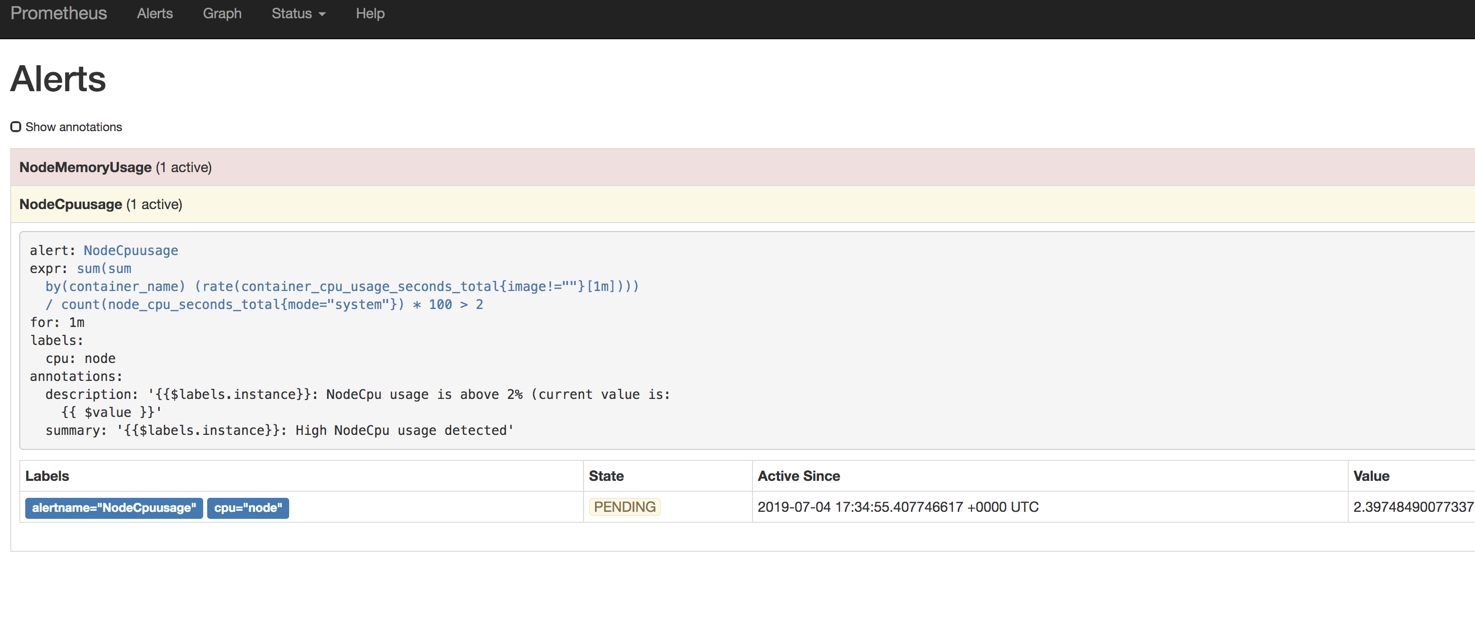
因为可能我的cpu还没有达到2%,所以没有触发报警
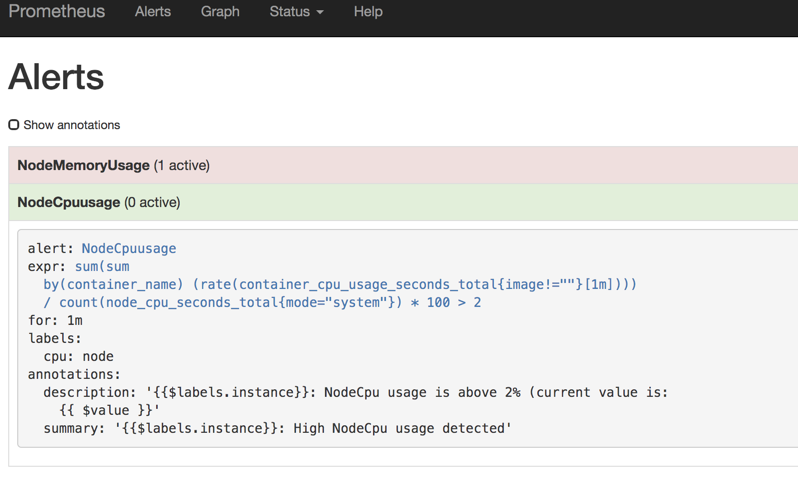
接下来我使用grafana搜索1年前的数据,这样cpu负载就会上升
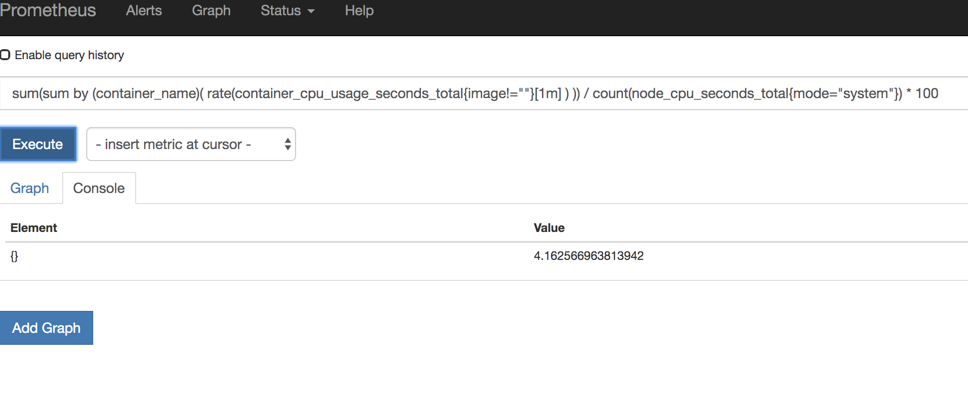
这里已经触发prometheus alermanager报警
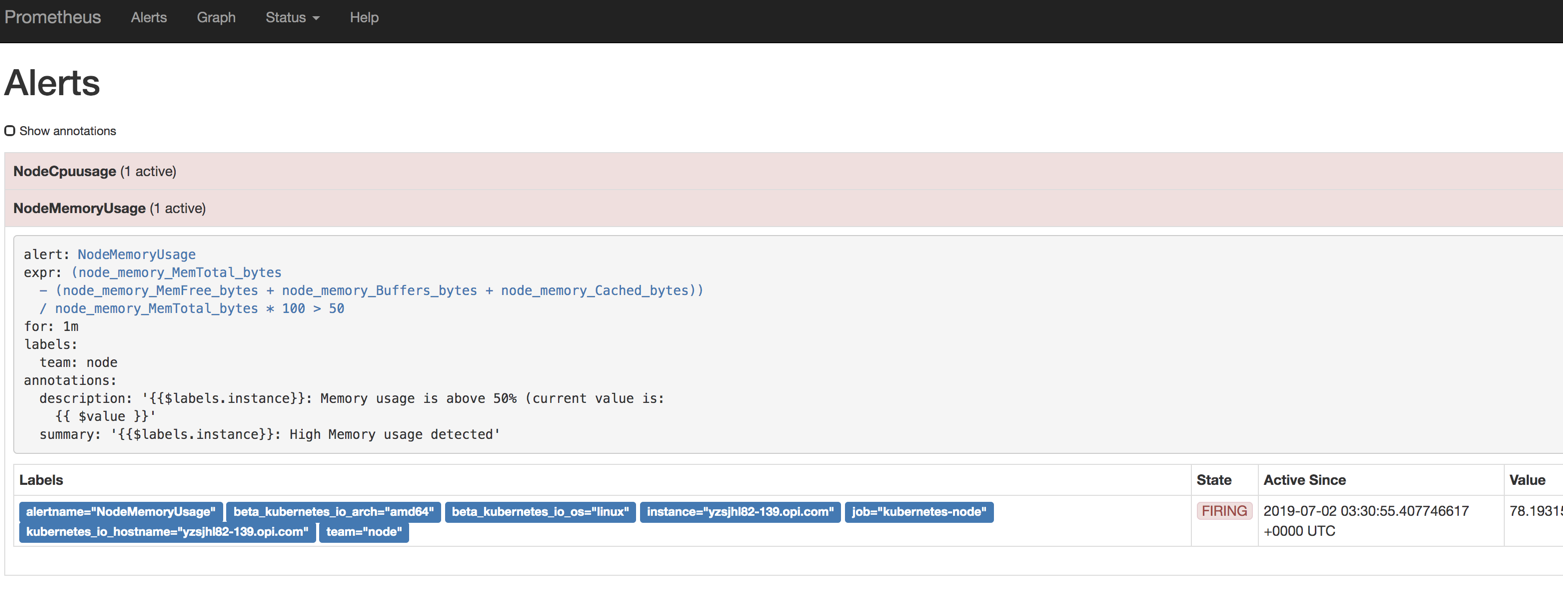
这里我们可以看到报警结果

我们可以通过查看dingding-hook的pod状态
[root@abcdocker prometheus]# kubectl get pod -n kube-system |grep abc abcdocker-dingding-hook-5b7696cd4f-6fdlw 1/1 Running 0 44m [root@abcdocker prometheus]# kubectl logs -f -n kube-system abcdocker-dingding-hook-5b7696cd4f-6fdlw * Serving Flask app "app" (lazy loading) * Environment: production WARNING: Do not use the development server in a production environment. Use a production WSGI server instead. * Debug mode: off * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) 10.244.0.0 - - [04/Jul/2019 17:45:01] "POST / HTTP/1.1" 200 - #这里已经显示Pod Post成功了
由于我们pod中是用一个非常简单的文本形式直接转发的,所以这里报警信息不够友好,没关系,有了这个示例我们完全就可以根据自己的需要来定制消息模板了,可以参考钉钉自定义机器人文档:https://open-doc.dingtalk.com/microapp/serverapi2/qf2nxq


“abcdocker/prometheus:v1″的Dockerfile能贴一下吗?
告警都触发了, 但是钉钉没有收到。
只看到“notify dingtalk error: 310000”, 没有其他信息了。
notify dingtalk error: 310000
请问您是怎么解决的,我也是同样的报错