
Prometheus监控Kubernetes 集群节点及应用
Prometheus
2019年06月18日
对于Kubernetes的集群监控一般我们需要考虑一下几方面
- Kubernetes节点的监控;比如节点的cpu、load、fdisk、memory等指标
- 内部系统组件的状态;比如kube-scheduler、kube-controller-manager、kubedns/coredns等组件的运行状态
- 编排级的metrics;比如Deployment的状态、资源请求、调度和API延迟等数据指标
监控方案
Kubernetes集群的监控方案主要有以下几种方案
- Heapster:Herapster是一个集群范围的监控和数据聚合工具,以Pod的形式运行在集群中
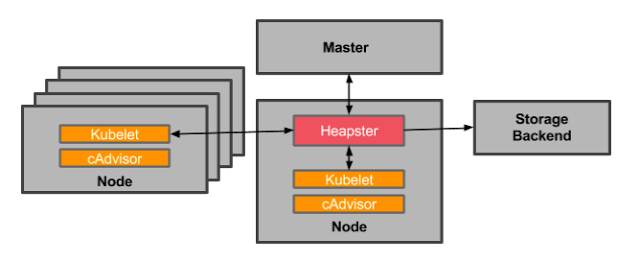
Kubelet/cAdvisor之外,我们还可以向Heapster添加其他指标源数据,比如kube-state-metrics
Heapster已经被废弃,使用metrics-server代替
- cAvisor:cAdvisor是Google开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持Docker容器,Kubernetes中,我们不需要单独去安装,cAdvisor作为kubelet内置的一部分程序可以直接使用
- Kube-state-metrics:通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储
- metrics-server:metrics-server也是一个集群范围内的资源数据局和工具,是Heapster的代替品,同样的,metrics-server也只是显示数据,并不提供数据存储服务。
不过kube-state-metrics和metrics-server之前还有很大不同的,二者主要区别如下
1.kube-state-metrics主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等 2.metrics-service主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标
监控集群节点
首先需要我们监控集群的节点,要监控节点其实我们已经有很多非常成熟的方案了,比如Nagios、Zabbix,甚至可以我们自己收集数据,这里我们通过prometheus来采集节点的监控指标,可以通过node_exporter获取,node_exporter就是抓取用于采集服务器节点的各种运行指标,目前node_exporter几乎支持所有常见的监控点,比如cpu、distats、loadavg、meminfo、netstat等,详细的监控列表可以参考github repo
这里使用DeamonSet控制器来部署该服务,这样每一个节点都会运行一个Pod,如果我们从集群中删除或添加节点后,也会进行自动扩展
cat >>prometheus-node-exporter.yaml<<EOF
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-system
labels:
name: node-exporter
spec:
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
EOF
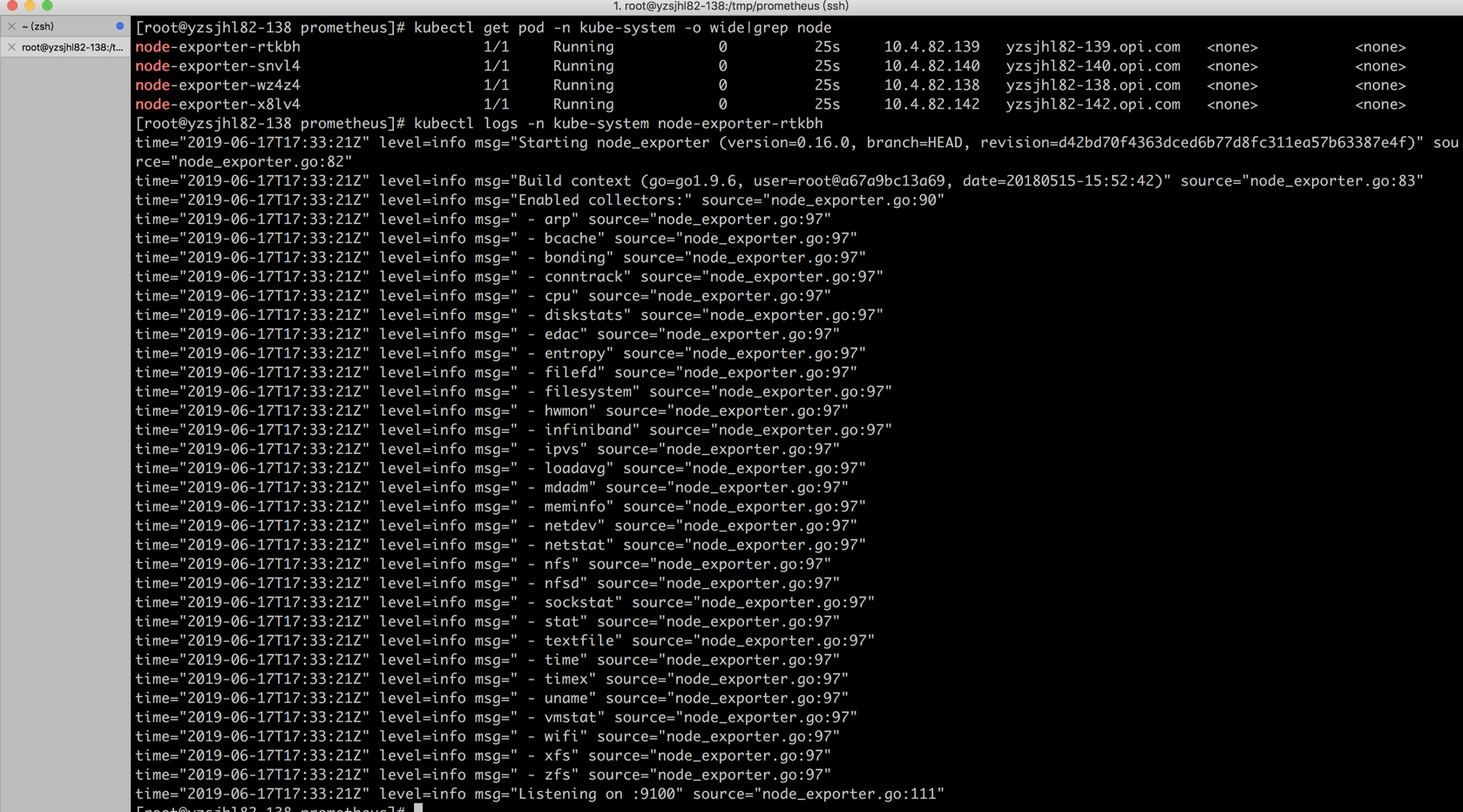
创建node-exporter并检查pod
[root@abcdocker prometheus]# kubectl create -f prometheus-node-exporter.yaml daemonset.extensions/node-exporter created [root@abcdocker prometheus]# kubectl get pod -n kube-system -o wide|grep node node-exporter-rtkbh 1/1 Running 0 25s 10.4.82.139 abcdocker82-139.opi.com node-exporter-snvl4 1/1 Running 0 25s 10.4.82.140 abcdocker82-140.opi.com node-exporter-wz4z4 1/1 Running 0 25s 10.4.82.138 abcdocker82-138.opi.com node-exporter-x8lv4 1/1 Running 0 25s 10.4.82.142 abcdockerl82-142.opi.com #这里我们可以看到,我们有4个节点,在所有的节点上都启动了一个对应Pod进行获取数据
node-exporter.yaml文件说明
由于我们要获取的数据是主机的监控指标数据,而我们的node-exporter是运行在容器中的,所以我们在Pod中需要配置一些Pod的安全策略
hostPID:true hostIPC:true hostNetwork:true #这三个配置主要用于主机的PID namespace、IPC namespace以及主机网络,这里需要注意的是namespace是用于容器隔离的关键技术,这里的namespace和集群中的namespace是两个完全不同的概念
另外我们还需要将主机/dev、/proc、/sys这些目录挂在到容器中,这些因为我们采集的很多节点数据都是通过这些文件来获取系统信息
比如我们在执行top命令可以查看当前cpu使用情况,数据就来源于/proc/stat,使用free命令可以查看当前内存使用情况,其数据来源是/proc/meminfo文件
另外如果是使用kubeadm搭建的,同时需要监控master节点的,则需要添加下方的相应容忍
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule
node-exporter容器相关启动参数
args:
- --path.procfs #配置挂载宿主机(node节点)的路径
- /host/proc
- --path.sysfs #配置挂载宿主机(node节点)的路径
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
在我们的yaml文件中加入了hostNetwork:true会直接将我们的宿主机的9100端口映射出来,从而不需要创建service 在我们的宿主机上就会有一个9100的端口
容器的9100--->映射到宿主机9100
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort: 9100
上面我们检查了Pod的运行状态都是正常的,接下来我们要查看一下Pod日志,以及node-exporter中的metrics
使用命令kubectl logs -n 命名空间 node-exporter中Pod名称检查Pod日志是否有额外报错
#接下来,我们在任意集群节点curl 9100/metrics
curl 127.0.0.1:9100/metrics
...
node_xfs_block_mapping_extent_list_insertions_total{device="vda2"} 0
node_xfs_block_mapping_extent_list_insertions_total{device="vda3"} 285586
# HELP node_xfs_block_mapping_extent_list_lookups_total Number of extent list lookups for a filesystem.
# TYPE node_xfs_block_mapping_extent_list_lookups_total counter
node_xfs_block_mapping_extent_list_lookups_total{device="vda2"} 27
node_xfs_block_mapping_extent_list_lookups_total{device="vda3"} 5.3729641e+07
# HELP node_xfs_block_mapping_reads_total Number of block map for read operations for a filesystem.
# TYPE node_xfs_block_mapping_reads_total counter
...
#只要metrics可以获取到数据说明node-exporter没有问题
服务发现
我们这里三个节点都运行了node-exporter程序,如果我们通过一个Server来将数据收集在一起,用静态的方式配置到prometheus就会显示一条数据,我们得自己在指标中过滤每个节点的数据,配置比较麻烦。 这里就采用服务发现
在Kubernetes下,Prometheus通过Kubernetes API基础,目前主要支持5种服务发现,分别是node、Server、Pod、Endpoints、Ingress
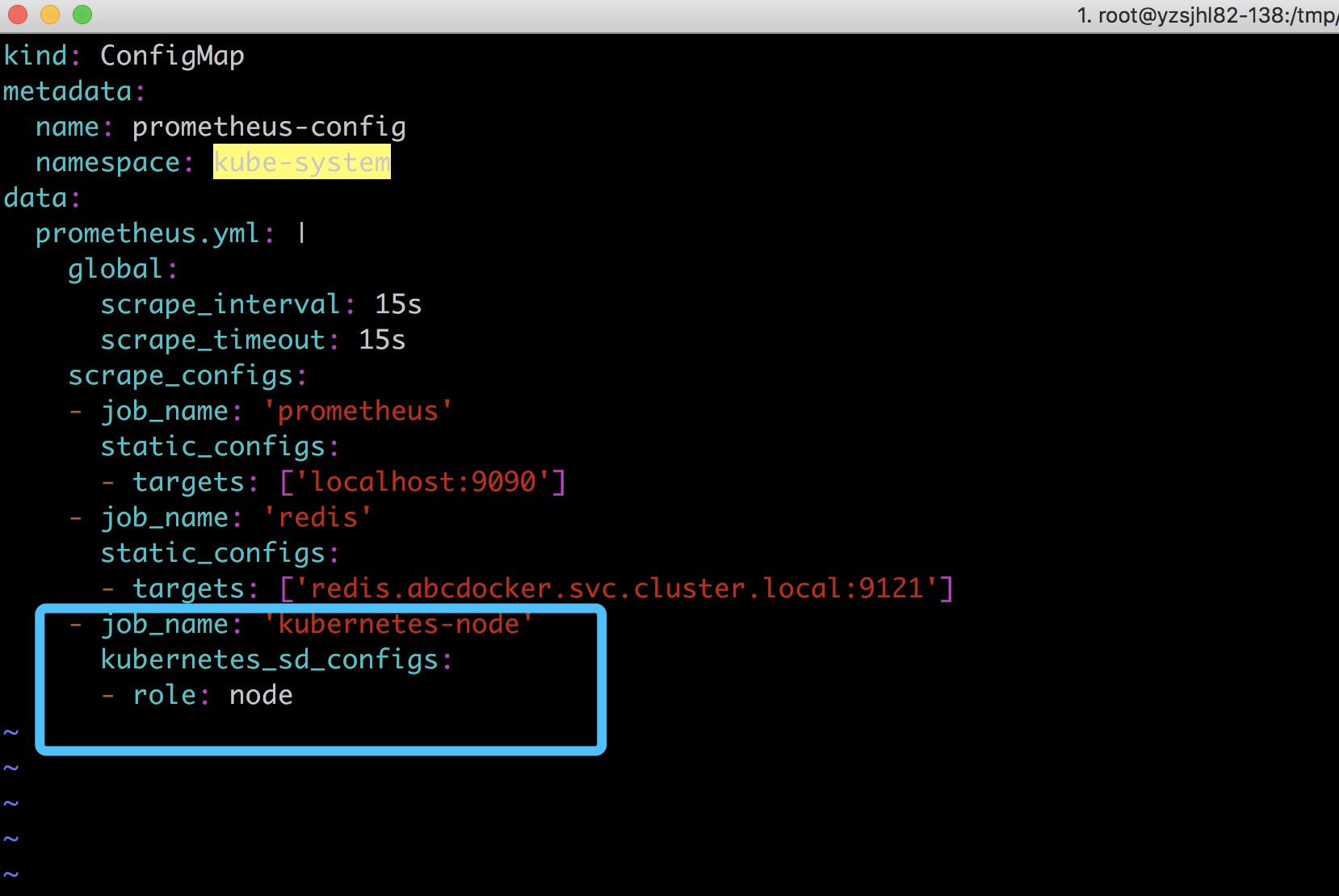
需要我们在Prometheus配置文件中,添加如下三行
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
#通过制定Kubernetes_sd_config的模式为node,prometheus就会自动从Kubernetes中发现所有的node节点并作为当前job监控的目标实例,发现的节点/metrics接口是默认的kubelet的HTTP接口
接下来我们更新配置文件
[root@abcdocker prometheus]# kubectl delete -f prometheus.configmap.yaml configmap "prometheus-config" deleted [root@abcdocker prometheus]# kubectl create -f prometheus.configmap.yaml configmap/prometheus-config created [root@abcdocker prometheus]# kubectl get svc -n kube-system |grep prometheus prometheus NodePort 10.101.143.162 9090:32331/TCP 21h #热更新刷新配置(可能稍微需要等待一小会) [root@abcdocker prometheus]# curl -X POST http://10.101.143.162:9090/-/reload
接着访问我们的地址
这个端口要和service对上
现在我们可以看到已经获取到我们的Node节点的IP,但是由于metrics监听的端口是10250而并不是我们设置的9100,所以提示我们节点属于Down的状态
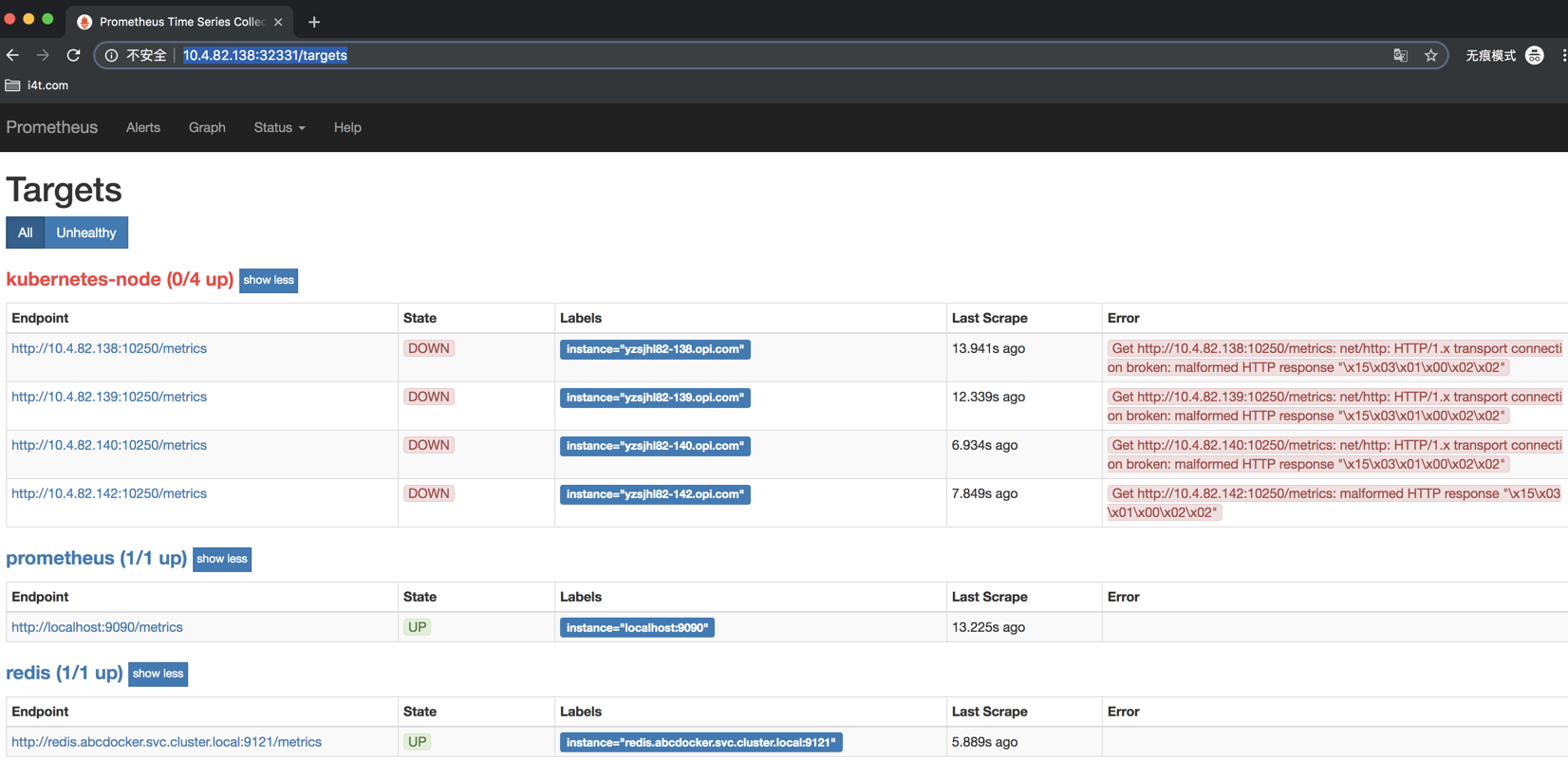
这里我们就需要使用Prometheus提供的relabel_configs中的replace能力了,relabel可以在Prometheus采集数据之前,通过Target实例的Metadata信息,动态重新写入Label的值。除此之外,我们还能根据Target实例的Metadata信息选择是否采集或者忽略该Target实例。这里使用__address__标签替换10250端口为9100
这里使用正则进行替换端口
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
接下来我们更新一下配置
curl的时候可以多更新几次,顺便等待一会
[root@abcdocker prometheus]# kubectl delete -f prometheus.configmap.yaml configmap "prometheus-config" deleted [root@abcdocker prometheus]# kubectl create -f prometheus.configmap.yaml configmap/prometheus-config created [root@abcdocker prometheus]# curl -X POST http://10.101.143.162:9090/-/reload
目前属于在收集的状态,我们等待一会即可
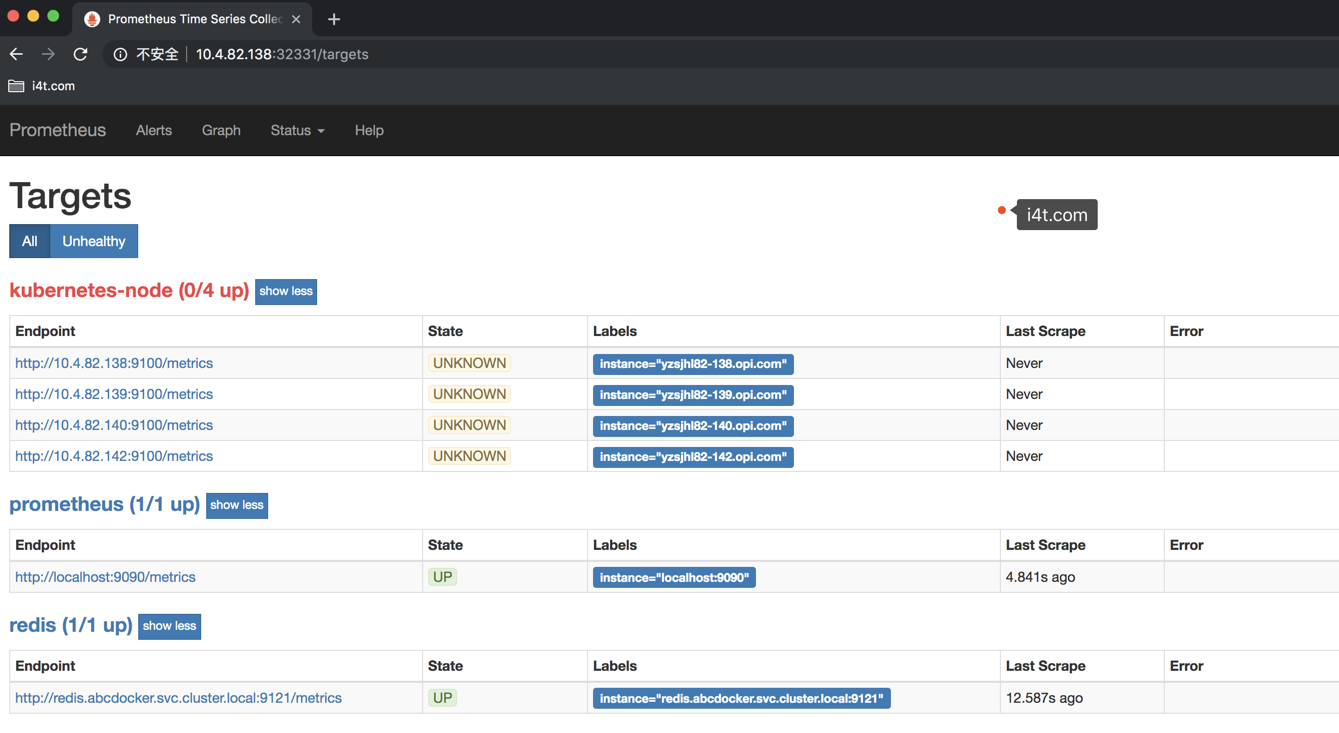
现在在状态就正常了
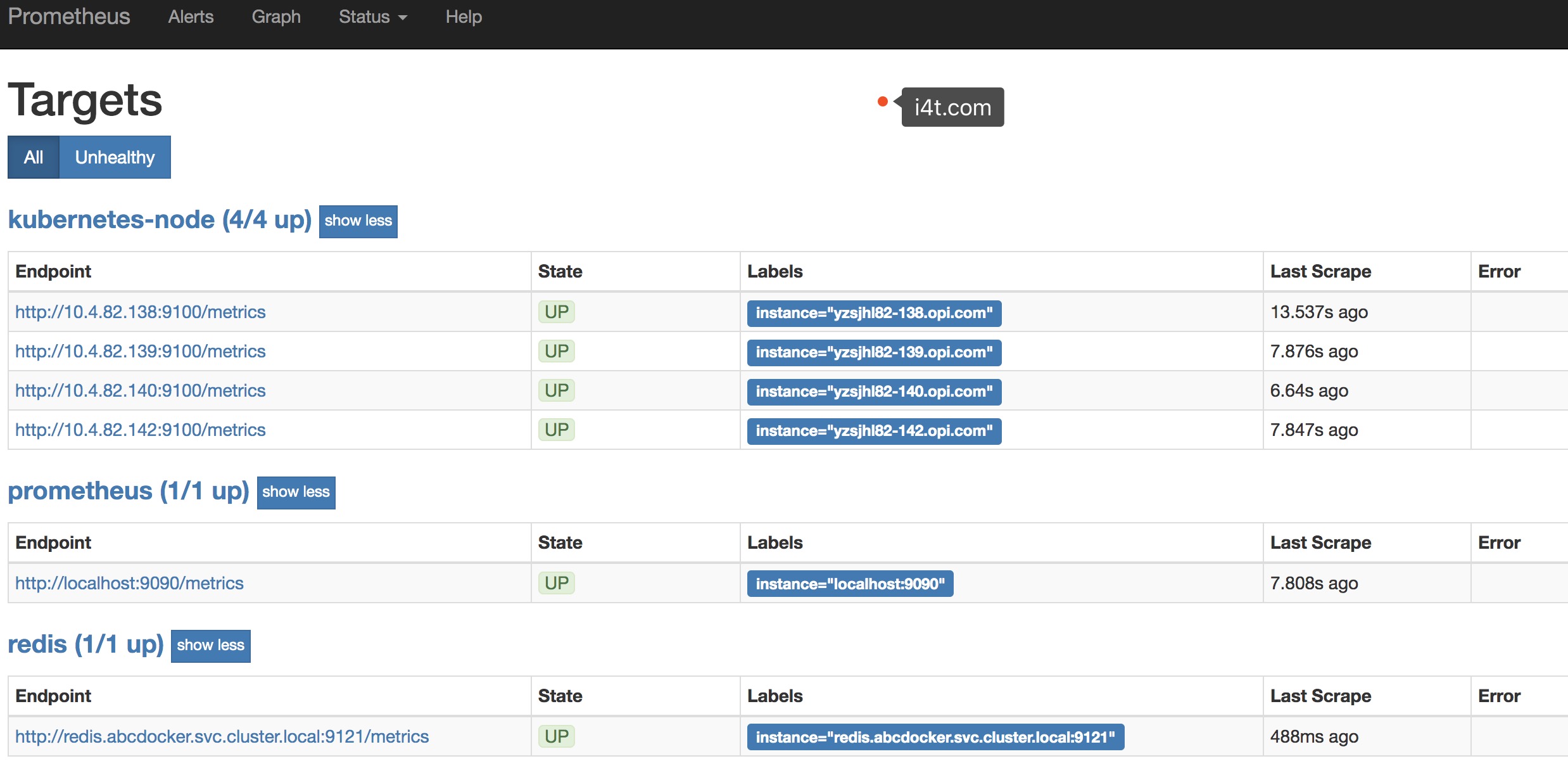
目前状态已经正常,但是还有一个问题就是我们的采集数据只显示了IP地址,对于我们监控分组分类不是很方便,这里可以通过labelmap这个属性来将Kubernetes的Label标签添加为Prometheus的指标标签
此处为可选配置
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
添加了一个action为labelmap,正则表达式是__meta_kubernetes_node(.+)的配置,这里的意思就是表达式中匹配的数据也添加到指标数据的Label标签中去。
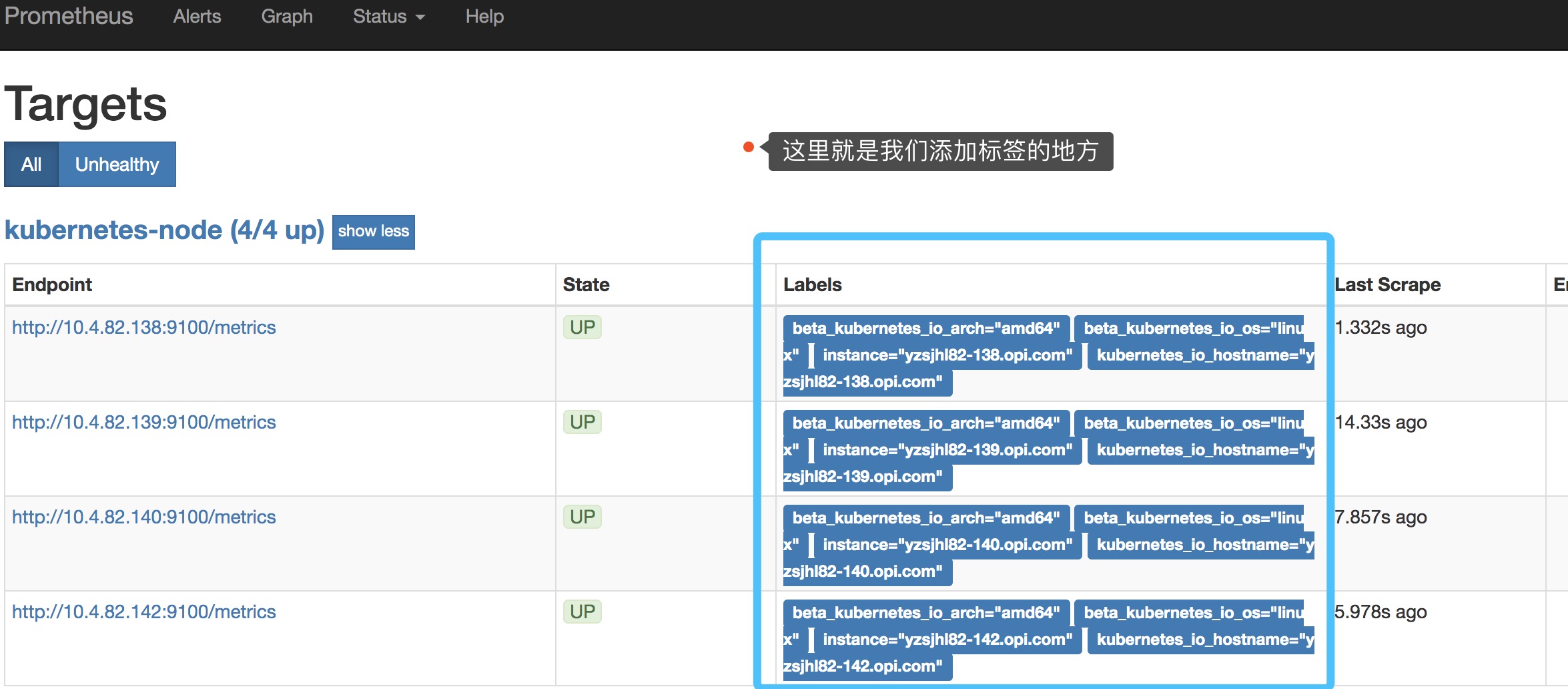
实际上就是获取我们的标签
kubectl get nodes --show-labels

对于Kubernetes_sd_configs下面可用的元标签如下
- __meta_kubernetes_node_name: 节点对象的名称
- _meta_kubernetes_node_label: 节点对象中的每个标签
- _meta_kubernetes_node_annotation: 来自节点对象的每个注释
_meta_kubernetes_node_address: 每个节点地址类型的第一个地址(如果存在) 关于kubernetes_sd_configs更多信息可以查看官方文档: kubernetes_sd_config
#prometheus configmap 监控完整配置如下,有需要可以直接拷贝
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
我们还可以去Graph里面看一下数据
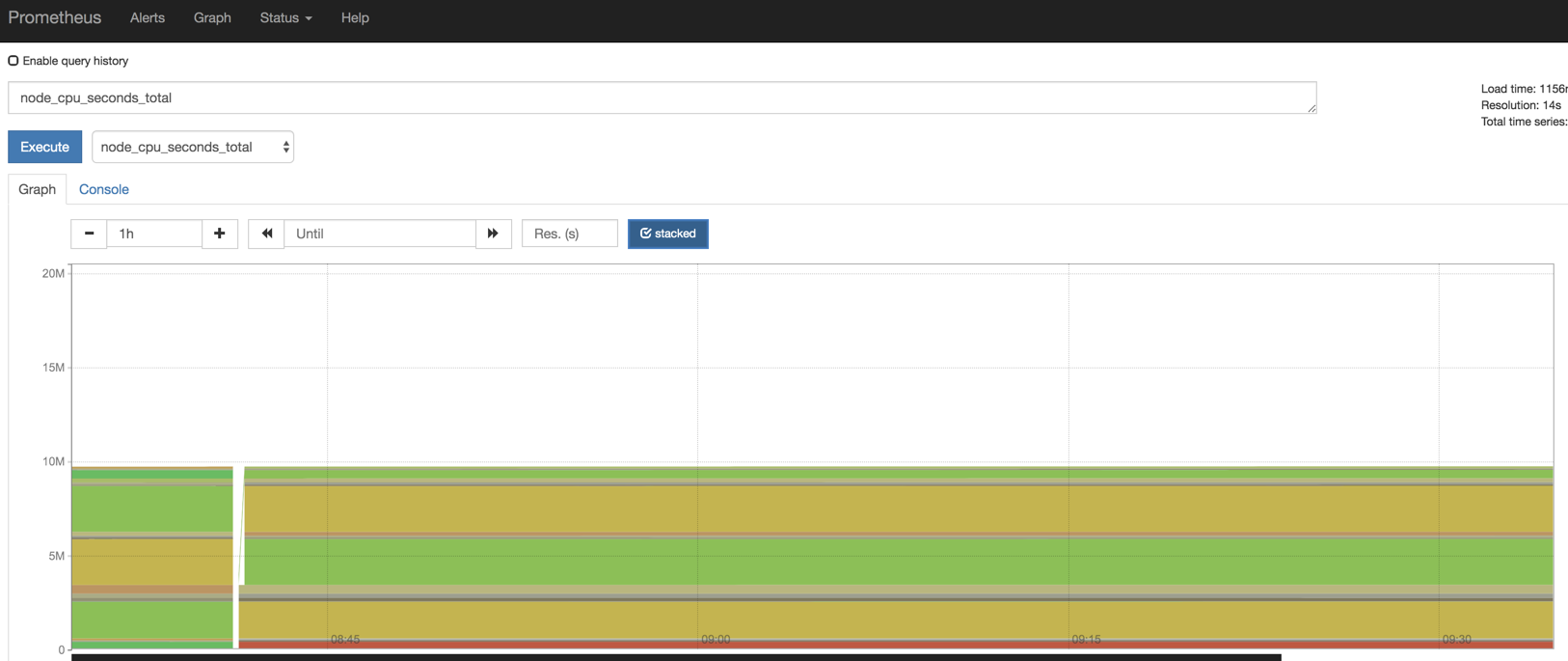
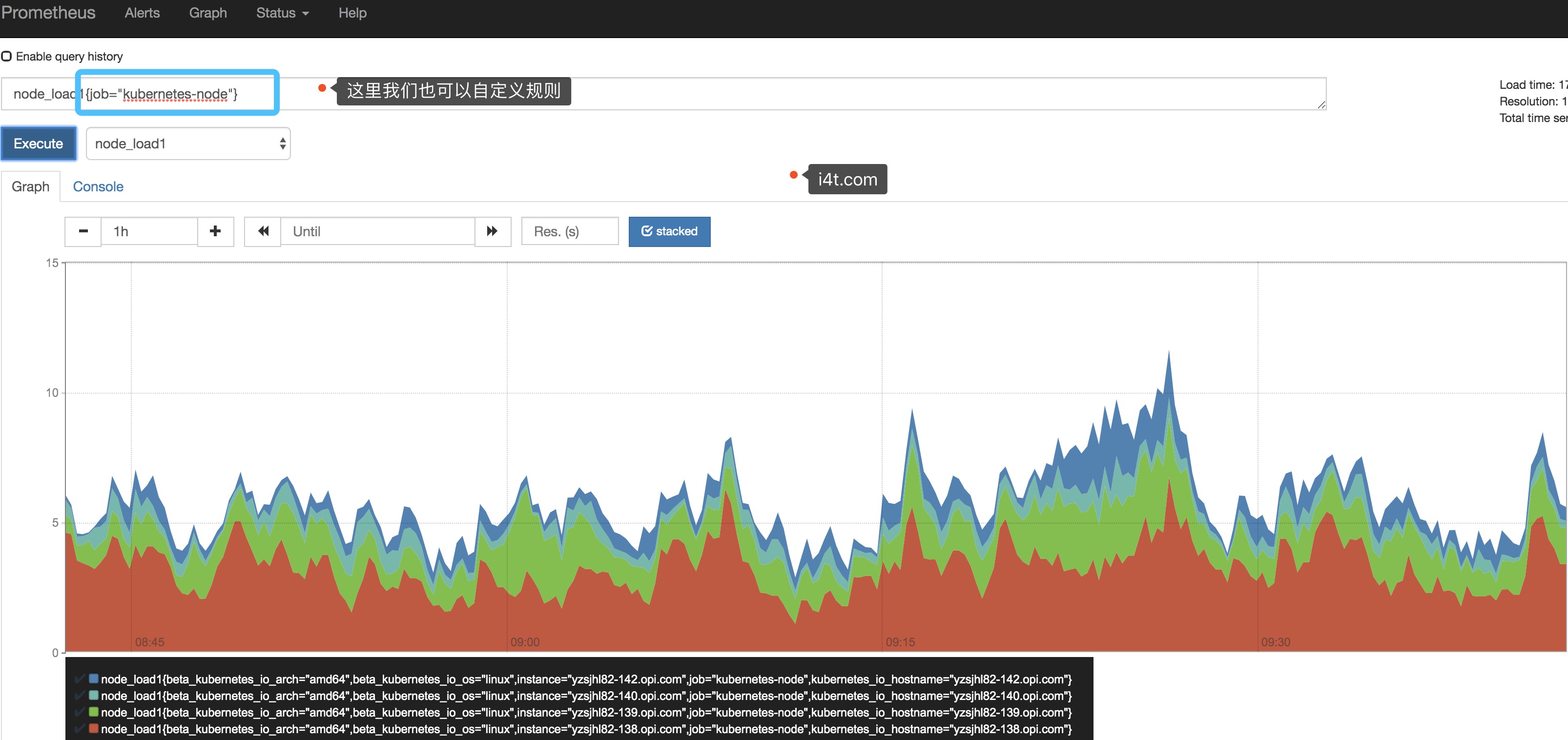
一、容器监控
cAdvisor是一个容器资源监控工具,包括容器的内存,CPU,网络IO,资源IO等资源,同时提供了一个Web页面用于查看容器的实时运行状态。
cAvisor已经内置在了kubelet组件之中,所以我们不需要单独去安装,cAdvisor的数据路径为/api/v1/nodes//proxy/metrics
action 使用labelkeep或者labeldrop则可以对Target标签进行过滤,仅保留符合过滤条件的标签
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
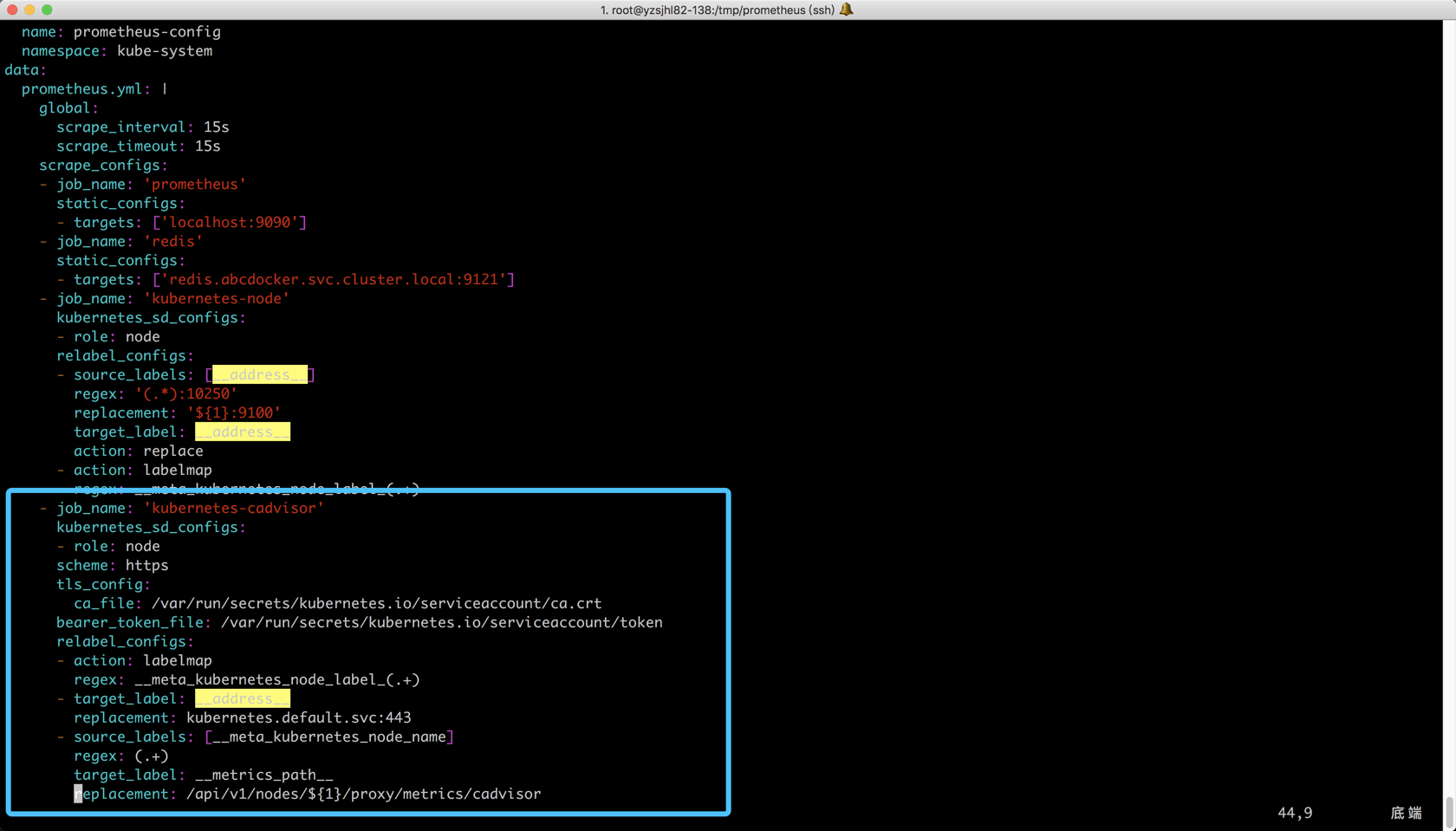
这里稍微说一下tls_config配置的证书地址是每个Pod连接apiserver所使用的地址,基本上写死了。并且我们在配置文件添加了一个labelmap标签。在最下面使用了一个正则替换了cAdvisor的一个metrics地址
证书是我们Pod启动的时候kubelet给pod注入的一个证书,所有的pod启动的时候都会有一个ca证书注入进来
如要想要访问apiserver的信息,还需要配置一个token_file
修改完成之后,我们需要configmap并且使用curl进行热更新(过程比较慢,需要等待会)
kubectl delete -f prometheus.configmap.yaml kubectl create -f prometheus.configmap.yaml curl -X POST http://10.101.143.162:9090/-/reload #curl可以多刷几次
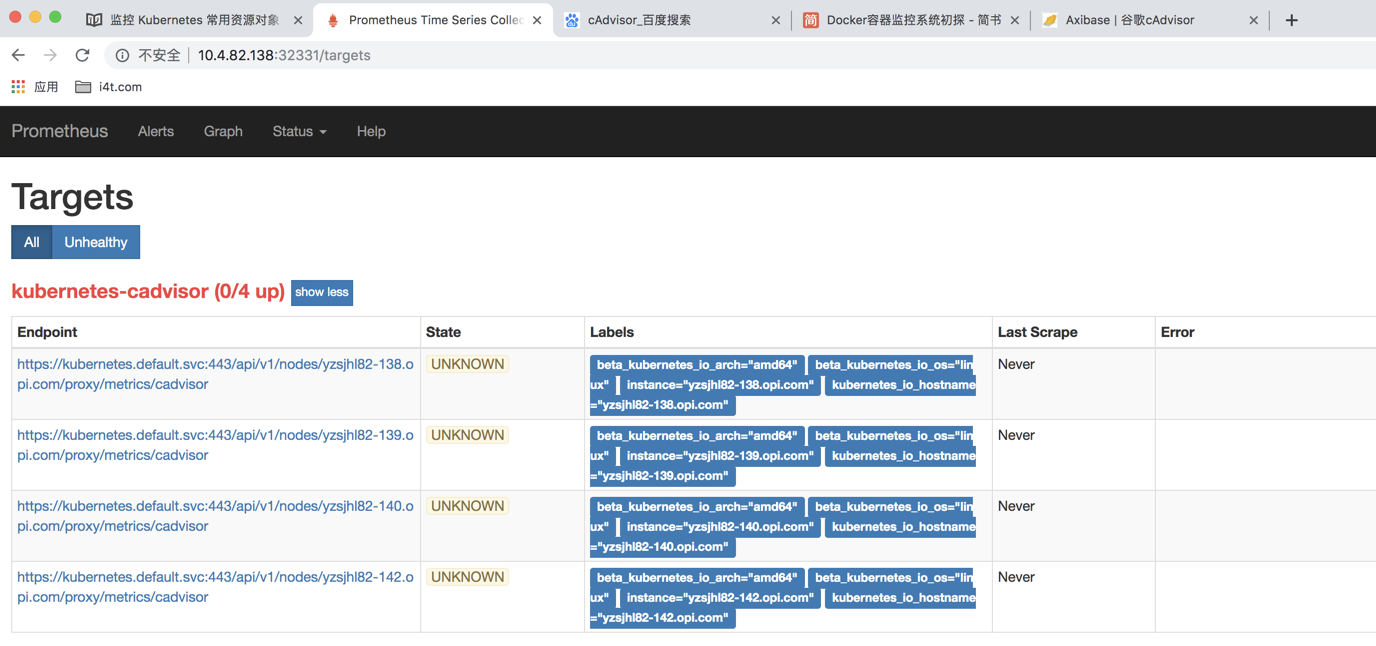
等待大约60秒
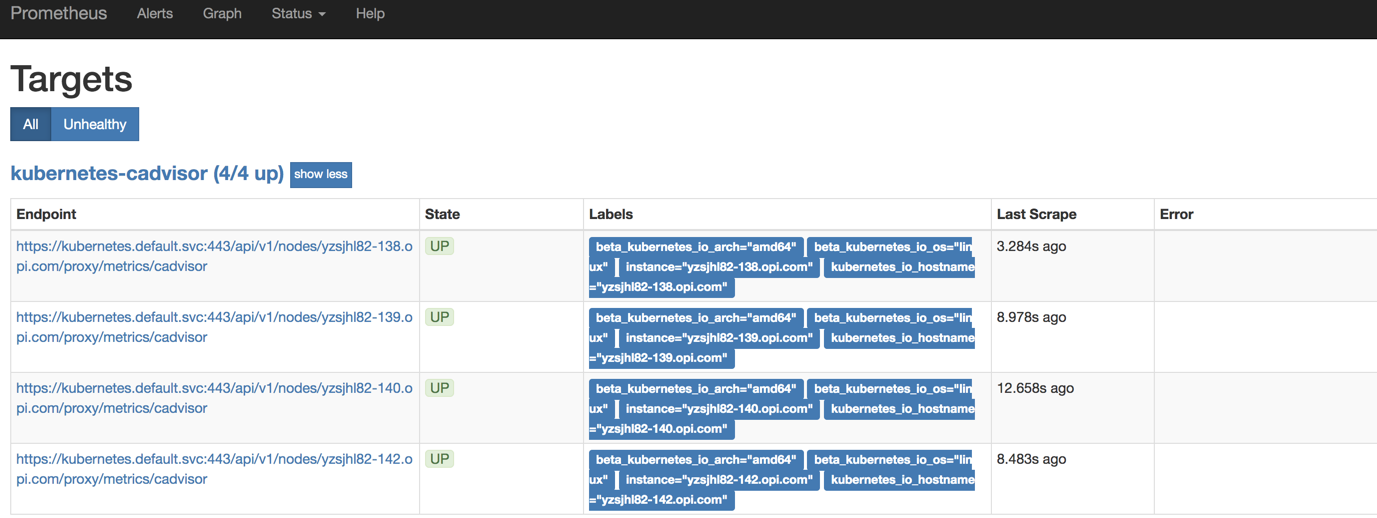
现在我们可以到Graph路径下面查询容器的相关数据
这里演示查询集群中所有Pod的CPU使用情况,查询指标
container_cpu_usage_seconds_total并且查询1分钟之内的数据
这里演示一下使用函数rate和不使用函数的一个过滤功能
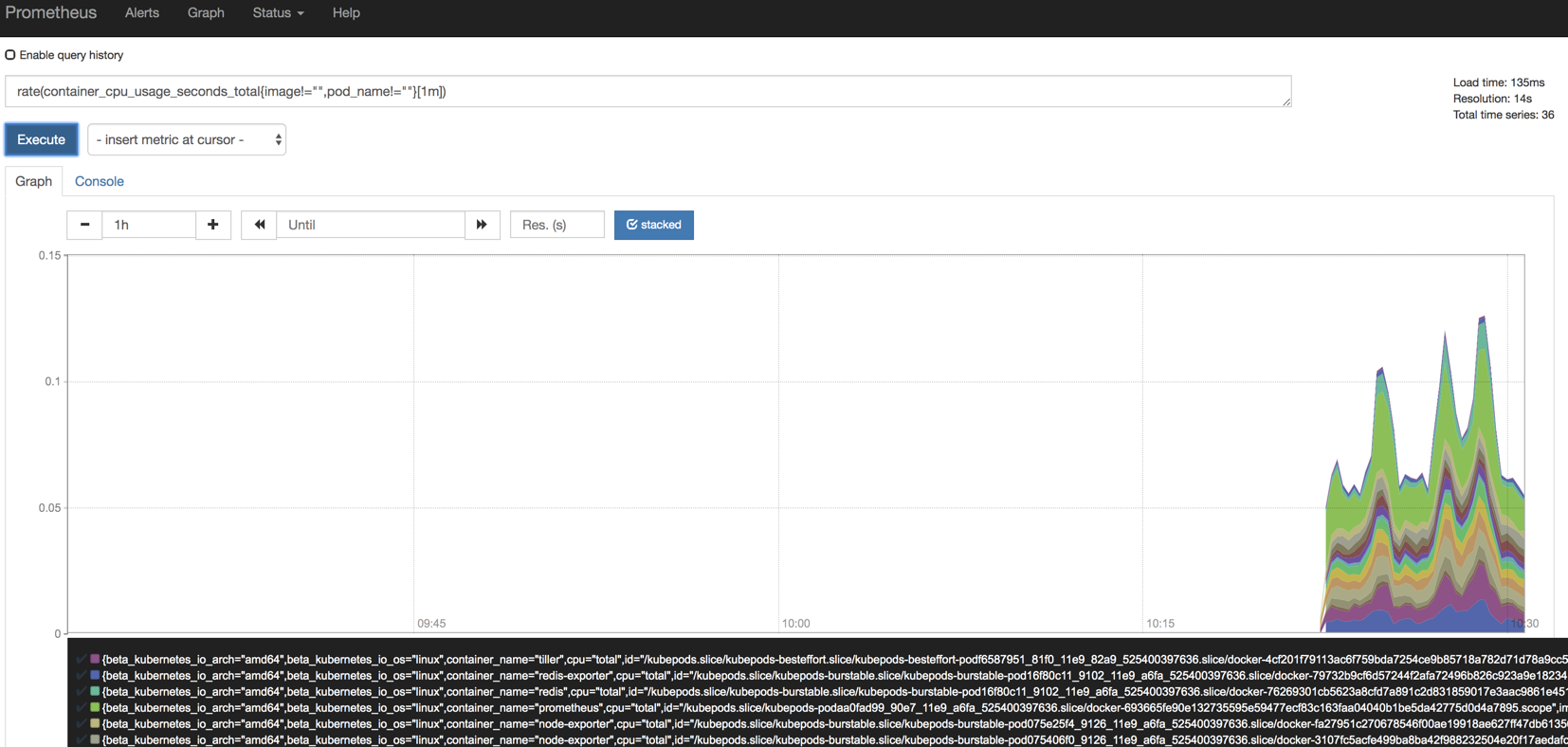
container_cpu_usage_seconds_total{image!="",pod_name!=""}
rate(container_cpu_usage_seconds_total{image!="",pod_name!=""}[1m])
执行下方命令,过滤1分钟内的数据
rate(container_cpu_usage_seconds_total{image!="",pod_name!=""}[1m])
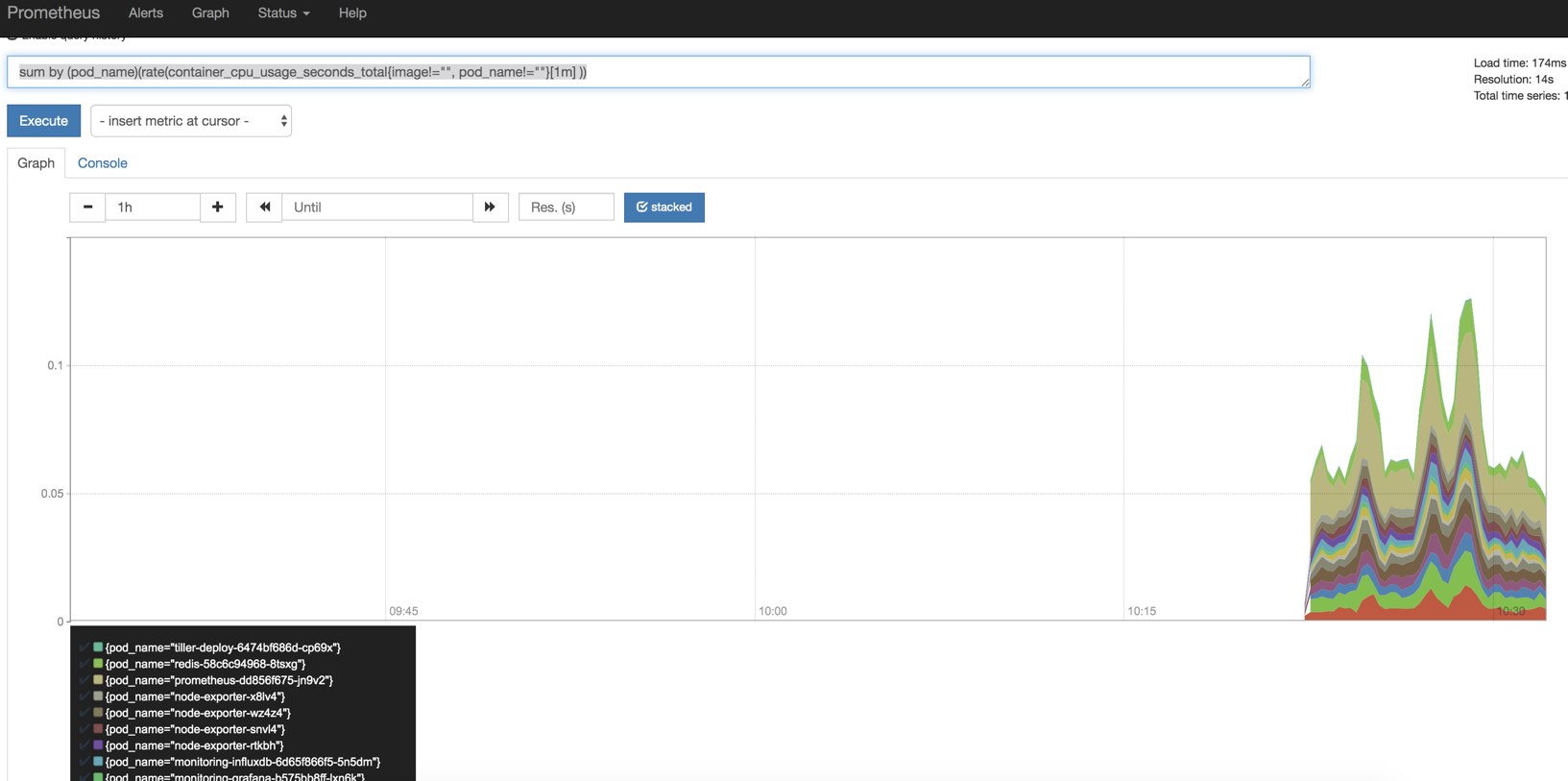
还可以使用sum函数,pod在1分钟内的使用率,同时将pod名称打印出来
sum by (pod_name)(rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ))
二、Api-Service 监控
apiserver作为Kubernetes最核心的组件,它的监控也是非常有必要的,对于apiserver的监控,我们可以直接通过kubernetes的service来获取
[root@abcdocker prometheus]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 443/TCP 33d
上面的service是我们集群的apiserver内部的service的地址,要自动发现service类型的服务,需要使用role为Endpoints的kubernetes_sd_configs (自动发现),我们只需要在configmap里面在添加Endpoints类型的服务发现
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
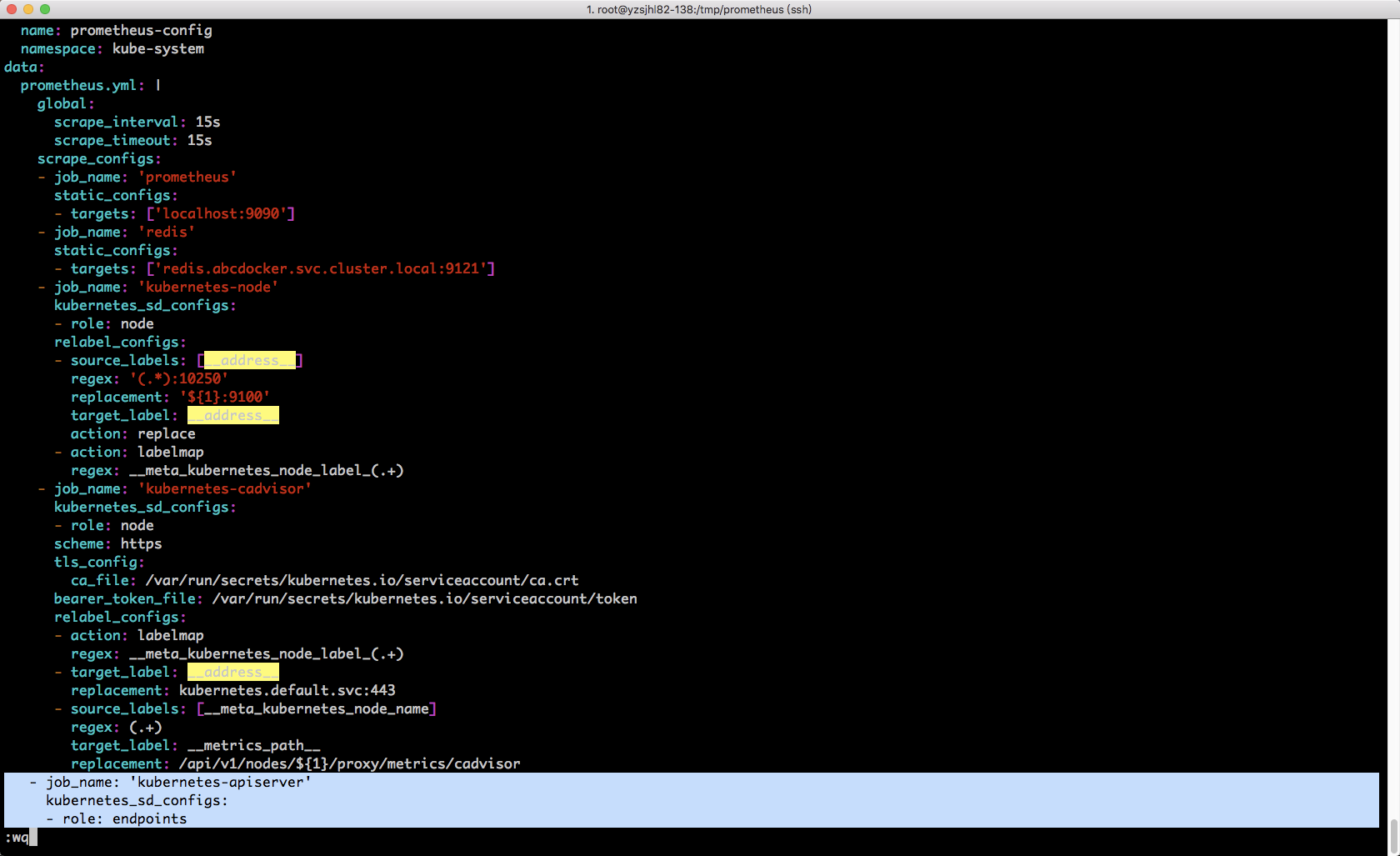
刷新配置文件,最好是多刷新几次
kubectl delete -f prometheus.configmap.yaml kubectl create -f prometheus.configmap.yaml curl -X POST http://10.101.143.162:9090/-/reload
更新完成后,我们可以看到kubernetes-apiserver下面出现了很多实例,这是因为我们这里使用的Endpoints类型的服务发现,所以prometheus把所有的Endpoints服务都抓取过来了,同样的我们要监控的kubernetes也在列表中。
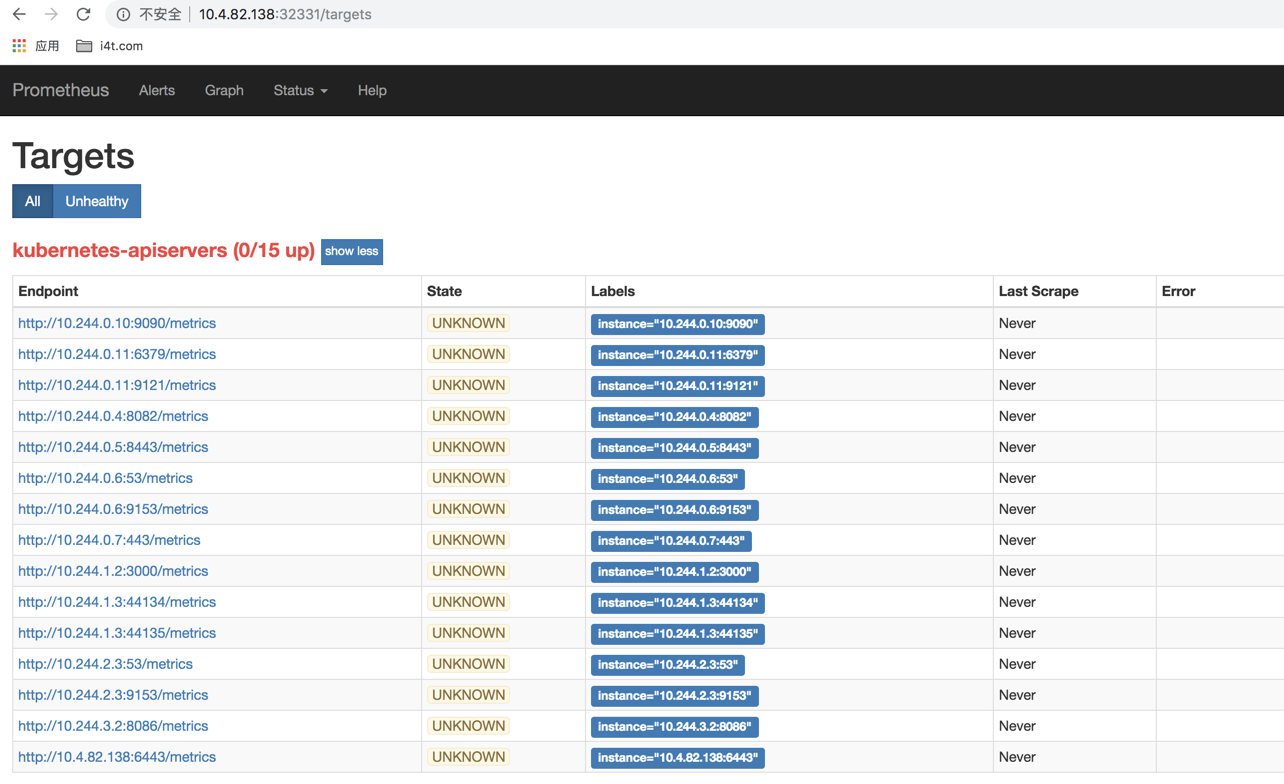
这里我们使用keep动作,将符合配置的保留下来,例如我们过滤default命名空间下服务名称为kubernetes的元数据,这里可以根据__meta_kubernetes_namespace和__mate_kubertnetes_service_name2个元数据进行relabel
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
#参数解释
action: keep #保留哪些标签
regex: default;kubernetes;https #匹配namespace下的default命名空间下的kubernetes service 最后https协议
可以通过`kubectl describe svc kubernetes`查看到
刷新配置
kubectl delete -f prometheus.configmap.yaml kubectl create -f prometheus.configmap.yaml curl -X POST http://10.101.143.162:9090/-/reload #这个过程比较慢,可能要等几分钟,可以多reload几次
出现状态UNKOWN等3秒在刷新就正常了
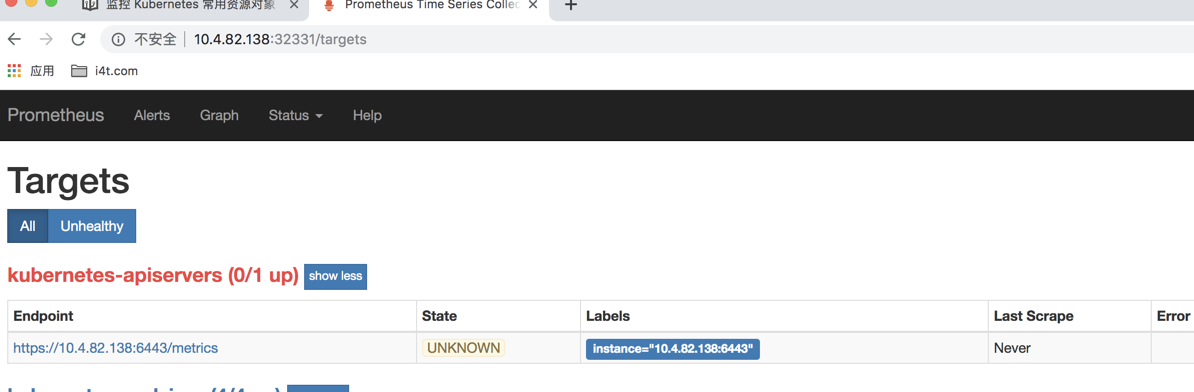
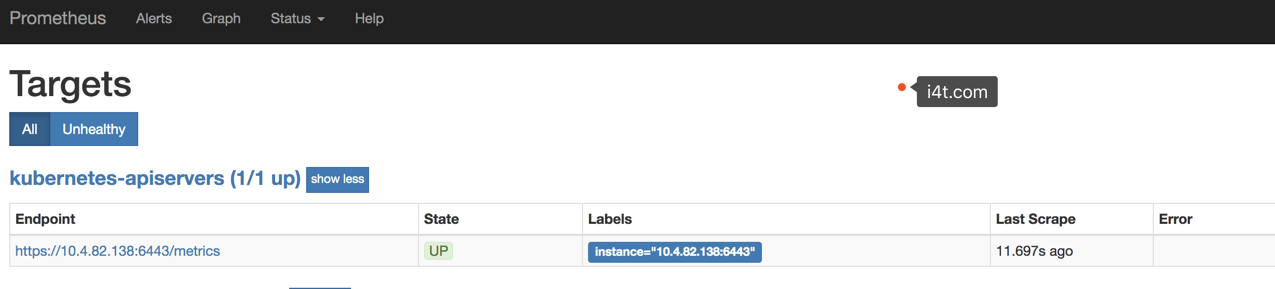
接下来我们还是前往Greph上查看采集到的数据
sum(rate(apiserver_request_count[1m])) #这里使用的promql里面的rate和sun函数,意思是apiserver在1分钟内请求的数
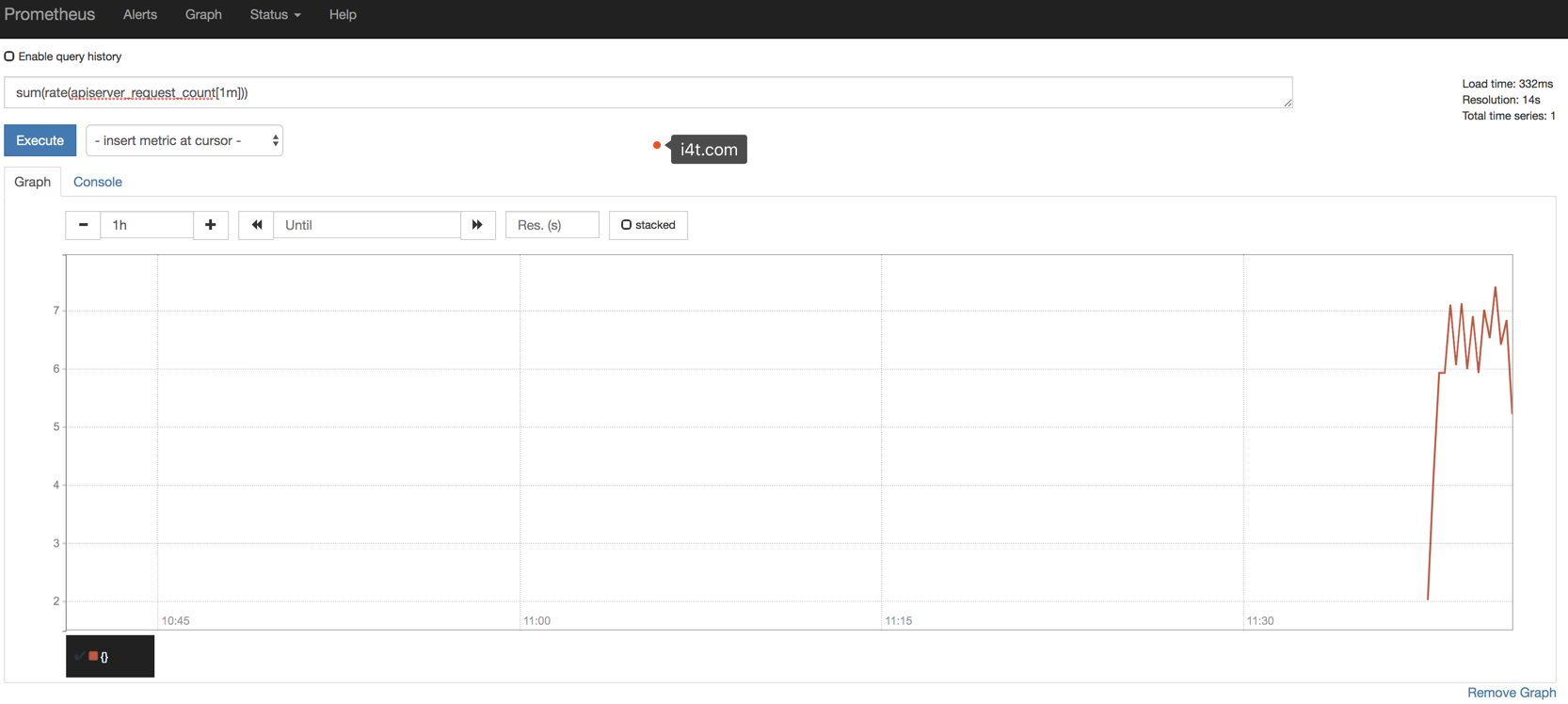
如果我们要监控其他系统组件,比如kube-controller-manager、kube-scheduler的话就需要单独手动创建service,因为apiserver服务默认在default,而其他组件在kube-steam这个namespace下。其中kube-sheduler的指标数据端口为10251,kube-controller-manager对应端口为10252
三、Service 监控
apiserver实际上是一种特殊的Service,现在配置一个专门发现普通类型的Service
这里我们对service进行过滤,只有在service配置了
prometheus.io/scrape: "true"过滤出来
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
继续重复步骤,刷新配置
#要多刷几次,要不你就等会 kubectl delete -f prometheus.configmap.yaml kubectl create -f prometheus.configmap.yaml curl -X POST http://10.101.143.162:9090/-/reload
Serivce自动发现参数说明 (并不是所有创建的service都可以被prometheus发现)
#1.参数解释
relabel_configs:
-source_labels:[__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true 保留标签
source_labels: [__meta_kubernetes_service_annotation_prometheus_io_cheme]
这行配置代表我们只去筛选有__meta_kubernetes_service_annotation_prometheus_io_scrape的service,只有添加了这个声明才可以自动发现其他service
#2.参数解释
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
#指定一个抓取的端口,有的service可能有多个端口(比如之前的redis)。默认使用的是我们添加是使用kubernetes_service端口
#3.参数解释
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
#这里如果是https证书类型,我们还需要在添加证书和token
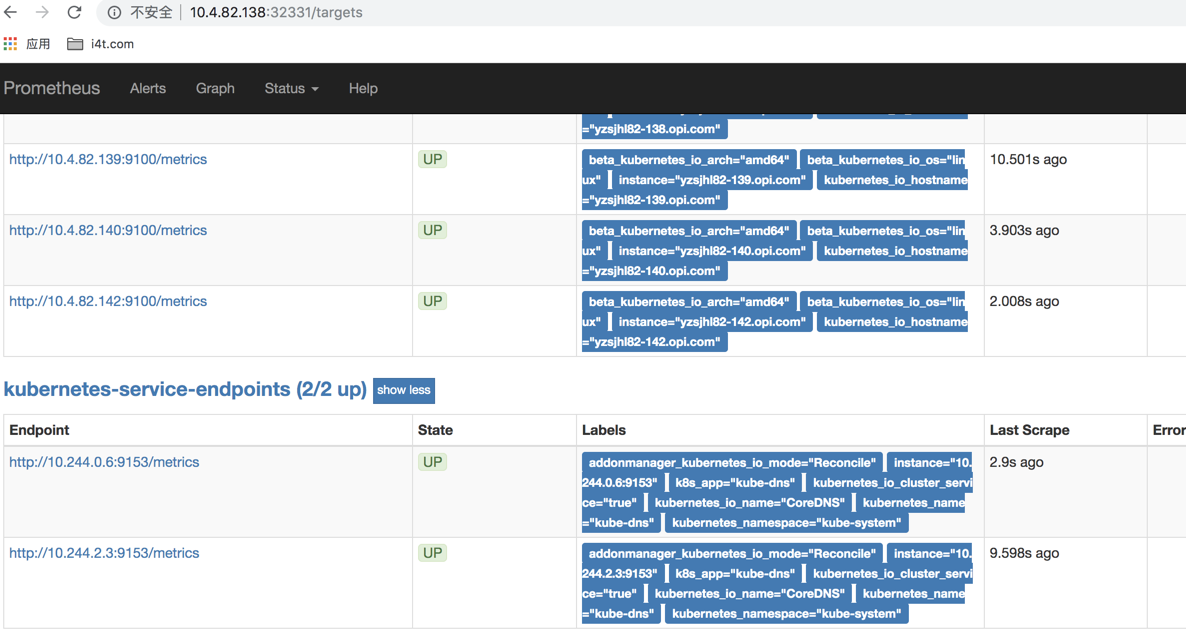
我们可以看到这里的服务的core DNS,为什么那么多service只有coreDNS可以被收集到呢?
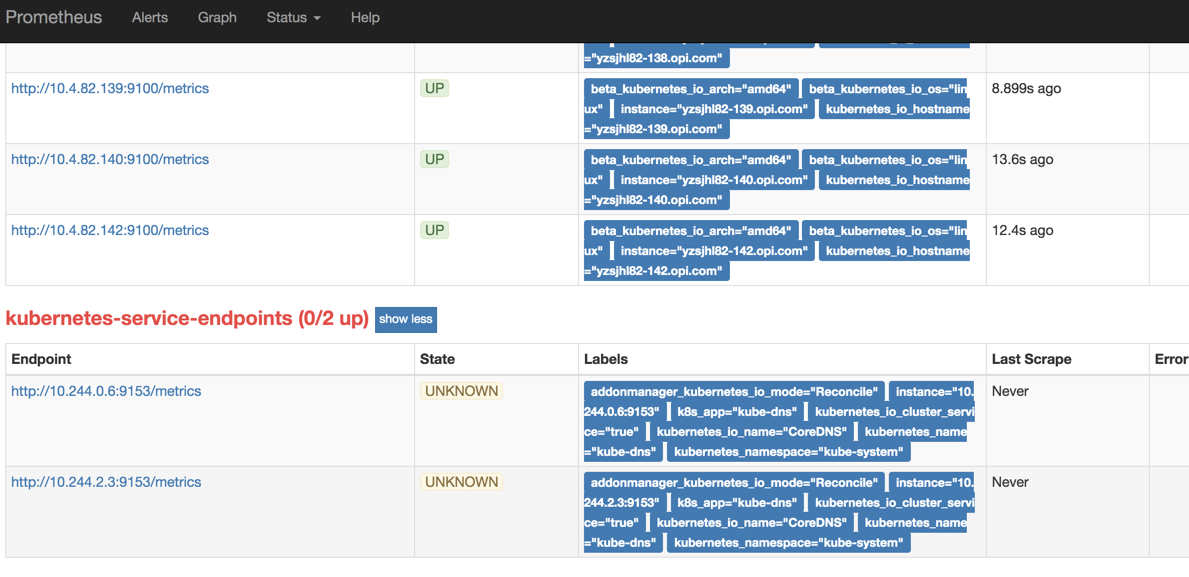
上面也说了,我们有过滤条件,只有复合条件的才进行过滤
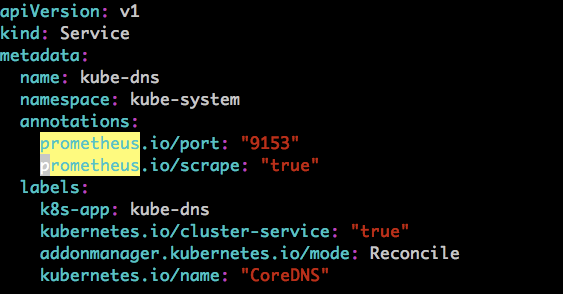
core DNS serviceYaml 文件包含
true参数,所以会被匹配到
当我们再次查看,发现状态完成
案例:之前我们配置了一个Redis的一个exporter,我们通过redis进行暴露监控
我们在之前的Redis上添加prometheus.io/scrape=true
cat >>prometheus-redis-exporter.yaml <<EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: redis
namespace: abcdocker
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
spec:
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:4
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: abcdocker
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
EOF
由于Redis服务的metrics接口在redis-exporter 9121上,我们还需要添加prometheus.io/port=9121这样的annotation
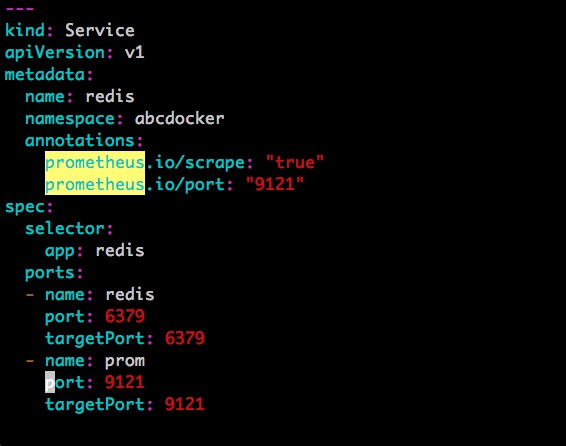
接下来我们刷新一下Redis的Service配置
[root@abcdocker prometheus]# kubectl apply -f prometheus-redis-exporter.yaml deployment.extensions/redis unchanged service/redis unchanged
我们之前配置的Redis exporter就可以不需要了(因为我们这里就是动态获取了)
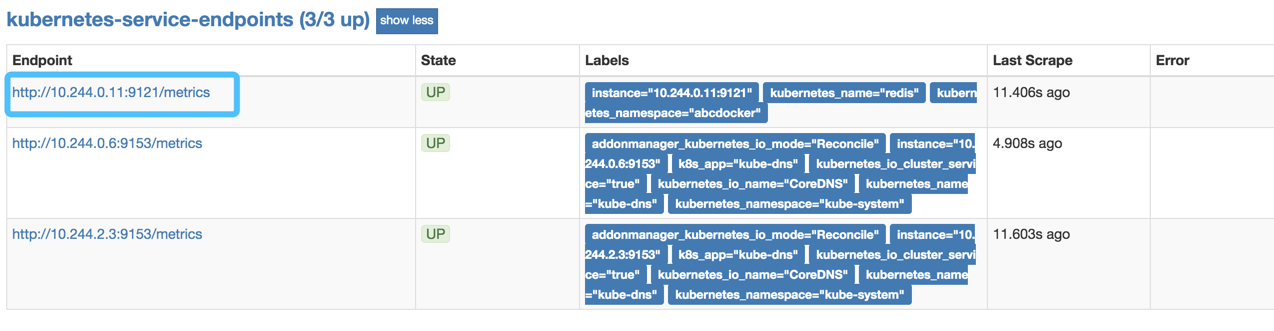
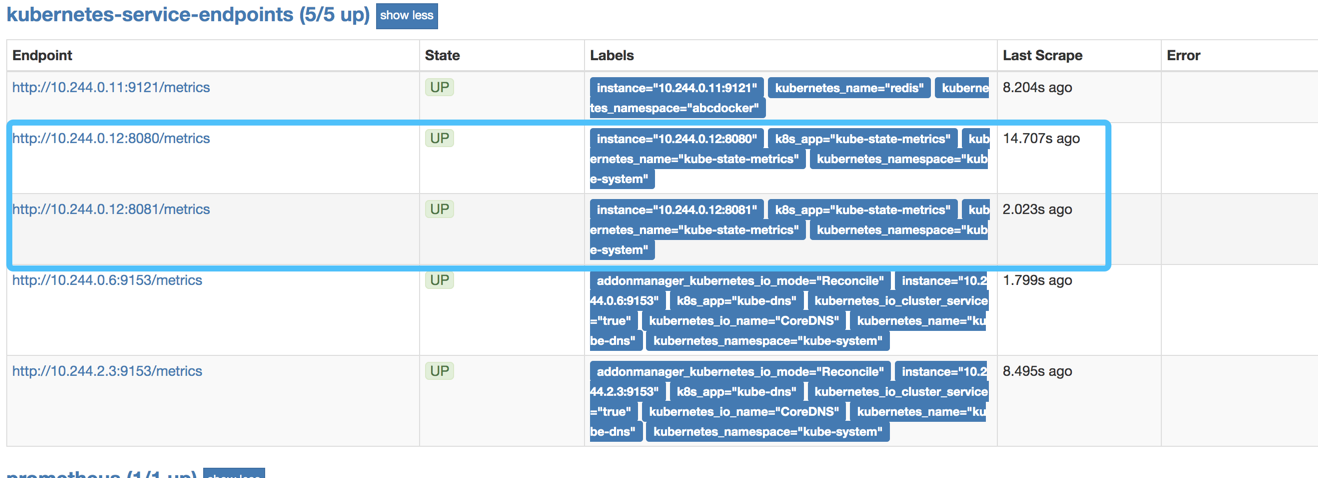
kube-state-metrics
kube-state-metrics是一个简单的服务,它监听Kubernetes API服务器并生成相关指标数据,它不单关注单个Kubernetes组件的运行情况,而是关注内部各种对象的运行状况
在K8s集群上Pod、DaemonSet、Deployment、Job、CronJob等各种资源对象的状态也需要监控,这些指标主要来自于apiserver和kubelet中集成的cAvisor,但是并没有具体的各种资源对象的状态指标。对于Prometheus来说,当然是需要引入新的exporter来暴露这些指标,Kubernetes提供了一个kube-state-metrics
kube-state-metrics已经给出了在Kubernetes部署的文件,我们直接将代码Clone到集群中执行yaml文件即可
将kube-state-metrics部署在kubernetes上之后,会发现kubernetes集群中的prometheus会在kube-state-metrics这个job下自动发现kube-state-metrics,并开始拉去metrics,这是因为部署kube-state-metrics的manifest定义文件kube-state-metrics-server.yaml对Service的定义包含prometheus.io/scrape: 'true'这样的一个annotation。因此kube-state-metrics的endpoint可以被Prometheus自动发现
关于kube-state-metrics暴露所有监控指标可以参考kube-state-metrics的文档kube-state-metrics Documentation
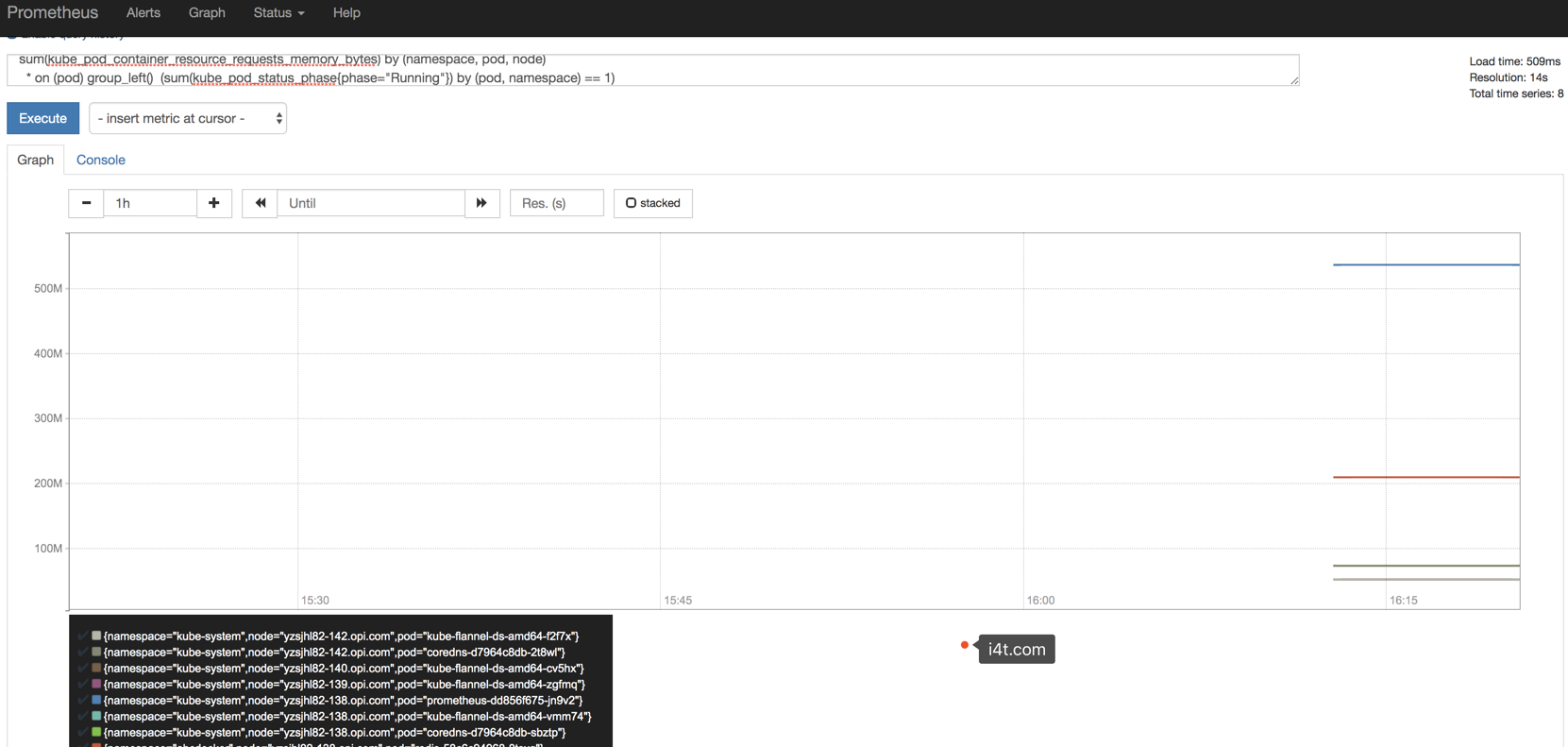
可以通过Graph进行测试一下
官方文档给出了一个例子是按照Pod内存使用情况进行绘图
sum(kube_pod_container_resource_requests_memory_bytes) by (namespace, pod, node)
* on (pod) group_left() (sum(kube_pod_status_phase{phase="Running"}) by (pod, namespace) == 1)


博主,你好,我用prometheus监控公司项目pod,在部署pod中添加了prometheus.io/scrape=true,但是状态都是down,提示的是no token found,这是一个nginx pod,不需要token的。这个问题卡了我很久了,求指导!
你的地址写的就不对,80端口后面跟的是index.html,prometheus监控数据需要有metrics数据
检查是否metrics数据
楼主, 我在添加node节点的job之后, mettries 特能获取到数据 但是在targets一直看不到node 的监控. 这是怎么回事呢?
看配置情况像是reload失败,你可能更新的监控项没有更新成功。所以你prometheus没有显示
你需要使用kubectl get svc -n kube-system|grep prometheus 来进行查看svc的ip和端口
楼主, 我在添加node节点的job之后, mettries 特能获取到数据 但是在targets一直看不到node 的监控. 这是怎么回事呢?
你这reload是失败的啊
这是mettries获取的数据
配置文件没有报错吧?
配置文件都没有报错,
我的这个都是不行, prometheus 和redis 都在192.168.251.102 这台node上, 只有在这台node上能curl 通. 但是也没明显的报错, 请问这是怎么回事
配置文件没有报错,不代表可以获取到metrics,没有通的后面肯定是有报错啊,您直接QQ问我吧 604419314
博主,请教我在 curl -X POST http://x.x.x.x:9090/-/reload这个地址的时候报
curl: (7) Failed connect to x.x.x.x:9090; Connection refused!是什么原因导致这个问题的!谢谢
1.检查pod状态,返回是否是正常
2.检查pod日志
3.这种情况一般就是你configmap写的不对,可以直接复制我下面完整的configmap
我执行完curl -X POST http://x.x.x.x:9090/-/reload这一步的时候,看pod日志 竟然是GET 而不是POST是啥情况
-X POST 你提交不就是post请求吗? 日志肯定是post啊