
Prometheus Operator
Prometheus
之前的文章介绍过传统方式安装Prometheus来监控集群,但是这种方式有一定的缺陷虽然完全可以用自定义方式来实现,但是不够灵活,不具有通用性。在自定义监控时还需要不断的更新Prometheus的配置。如果是kubernetes集群完全可以使用一种更原始的方式来实现kubernetes集群监控,即采用Prometheus Operator
Operator是由CoreOS公司开发的用来扩展Kubernetes API的特定应用程序控制器,用来创建、配置和管理复杂的有状态应用,例如Mysql、缓存和监控系统。目前CoreOS官方提供了几种Operator的代码实现,其中就包括Prometheus Operator
下图为Prometheus Operator 架构图
Operator作为一个核心的控制器,它会创建Prometheus、ServiceMonitor、alertmanager以及我们的prometheus-rule这四个资源对象,operator会一直监控并维持这四个资源对象的状态,其中创建Prometheus资源对象就是作为Prometheus Server进行监控,而ServiceMonitor就是我们用的exporter的各种抽象(exporter前面文章已经介绍了,就是提供我们各种服务的metrics的工具)Prometheus就是通过ServiceMonitor提供的metrics数据接口把我们数据pull过来的。现在我们监控prometheus不需要每个服务单独创建修改规则。通过直接管理Operator来进行集群的监控。这里还要说一下,一个ServiceMonitor可以通过我们的label标签去匹配集群内部的service,而我们的prometheus也可以通过label匹配多个ServiceMonitor
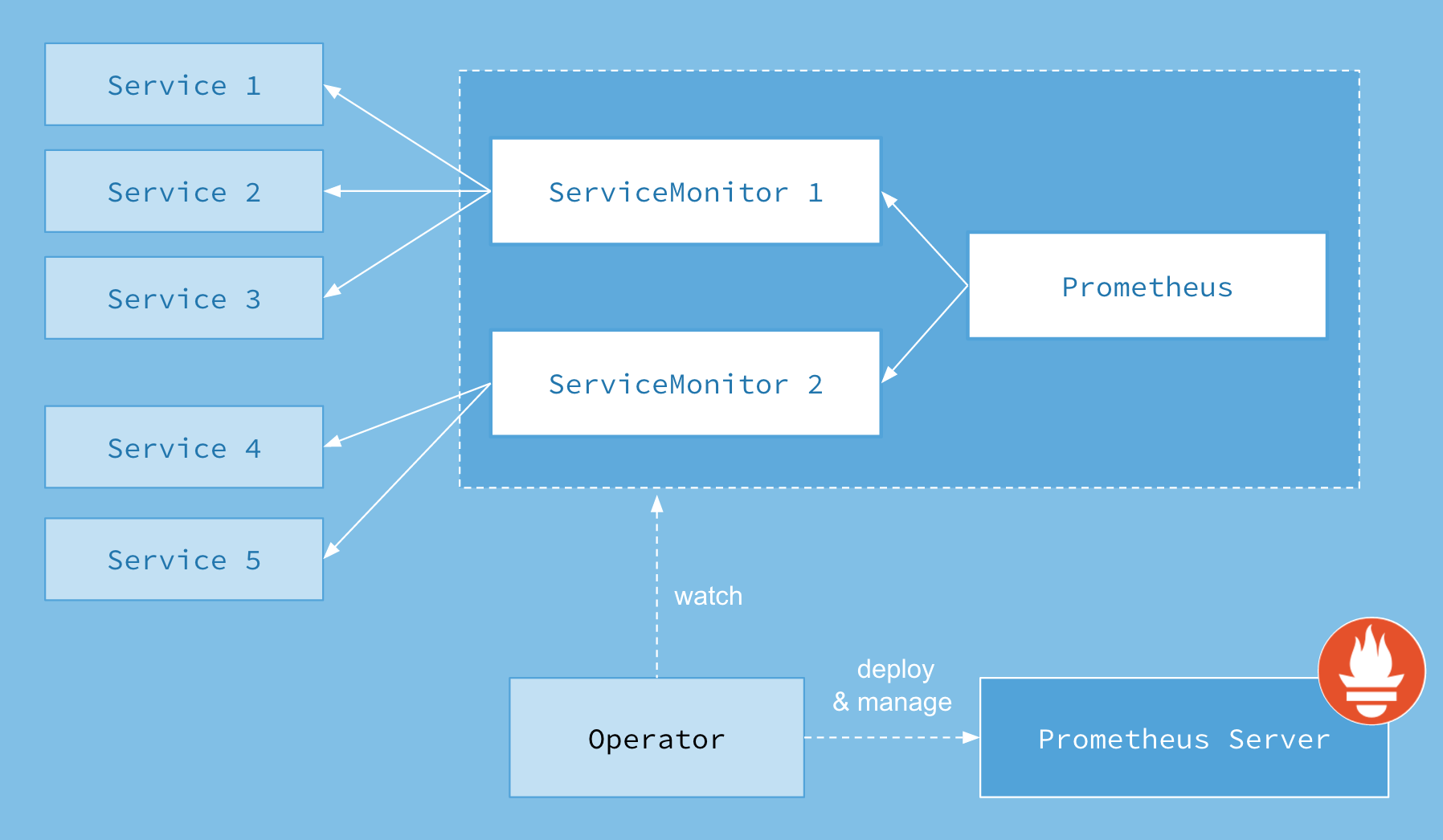
其中,Operator是核心部分,作为一个控制器而存在,Operator会创建Prometheus、ServiceMonitor、AlertManager及PrometheusRule这4个CRD资源对象,然后一直监控并维持这4个CRD资源对象的状态
- Prometheus 资源对象是作为Prometheus Service存在的
- ServiceMonitor 资源对象是专门提供metrics数据接口的exporter的抽象,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的
- AlerManager 资源对象是对应alertmanager组件
- PrometheusRule 资源对象是被Prometheus实例使用的告警规则文件
CRD简介 全称CustomResourceDefinition,在Kubernetes中一切都可视为资源,在Kubernetes1.7之后增加对CRD自定义资源二次开发能力开扩展Kubernetes API,当我们创建一个新的CRD时,Kubernetes API服务器将为你制定的每个版本创建一个新的RESTful资源路径,我们可以根据该API路径来创建一些我们自己定义的类型资源。CRD可以是命名空间,也可以是集群范围。由CRD的作用域scpoe字段中所制定的,与现有的内置对象一样,删除名称空间将删除该名称中的所有自定义对象 简单的来说CRD是对Kubernetes API的扩展,Kubernetes中的每个资源都是一个API对象的集合,例如yaml文件中定义spec那样,都是对Kubernetes中资源对象的定义,所有的自定义资源可以跟Kubernetes中内建的资源一样使用Kubectl
这样,在集群中监控数据,就变成Kubernetes直接去监控资源对象,Service和ServiceMonitor都是Kubernetes的资源对象,一个ServiceMonitor可以通过labelSelector匹配一类Service,Prometheus也可以通过labelSelector匹配多个ServiceMonitor,并且Prometheus和AlertManager都是自动感知监控告警配置的变化,不需要认为进行reload操作。
安装
前天我们也说了Operator是原生支持Prometheus的,可以通过服务发现来监控集群,并且是通用安装。也就是operator提供的yaml文件,基本上在Prometheus是可以直接使用的,需要改动的地方可能就只有几处
有点需要说明一下,前面我们手动安装了prometheus,在这里都需要删除,有一些服务会影响我们这里的资源对象创建,例如node-exporter
#首先我们下载operator #我这里提供的yaml文件和下面的镜像版本是对应的,如果使用官网的请自行下载镜像 wget -P /root/ http://down.i4t.com/abcdocker-prometheus-operator.yaml.zip unzip abcdocker-prometheus-operator.yaml.zip cd /root/kube-prometheus-master/manifests #官方下载 (使用官方下载的出现镜像版本不相同请自己找镜像版本) wget -P /root/ https://github.com/coreos/kube-prometheus/archive/master.zip unzip master.zip cd /root/kube-prometheus-master/manifests
prometheus-serviceMonitorKubelet.yaml (这个文件是用来收集我们service的metrics数据的)
这里不进行修改
cat prometheus-serviceMonitorKubelet.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kubelet
name: kubelet
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
honorLabels: true
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
honorLabels: true
interval: 30s
metricRelabelings:
- action: drop
regex: container_(network_tcp_usage_total|network_udp_usage_total|tasks_state|cpu_load_average_10s)
sourceLabels:
- __name__
path: /metrics/cadvisor
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector: #匹配命名空间,这个代表的意思就是会去匹配kube-system命名空间下,具有k8s-app=kubelet的标签,会将匹配的标签纳入我们prometheus监控中
matchNames:
- kube-system
selector: #这三行是用来匹配我们的service
matchLabels:
k8s-app: kubelet
由于国内网络问题,有一些镜像无法直接下载。我这里提供了所有的镜像,只要导入进去即可
#我这里已经做了免密,直接拷贝镜像地址在所有的服务器上reload一下即可
wget -c http://down.i4t.com/abcdocker-prometheus-opertor.tar
#这里等待会慢些,一会就可以下载好了(遇到报错等等,如果不成功可以将url复制在浏览器在rz上去,总比Google拉不了镜像强)
for i in k8s-master1 k8s-master2 k8s-node1 k8s-node2;do
echo "----- $i -----"
scp abcdocker-prometheus-opertor.tar root@$i:/opt/
ssh root@$i "docker load -i /opt/abcdocker-prometheus-opertor.tar"
done
#这样集群所有节点都有镜像,不存在镜像拉取不到的错误(这里的yaml文件最好使用我的版本,否则后面yaml文件更新了,镜像还需要从新获取)这里有一个k8s.gcr.io/addon-resizer因为在Google上面被墙拦住了,所以大家还是乖乖的用我的镜像吧
这里修改完毕后,我们就可以直接创建配置文件
#需要在manifests目录下进行创建,我会将整个yaml打包,直接进入即可 [root@yzsjhl82-138 ~]# cd kube-prometheus-master/manifests/ [root@k8s-master1 manifests]# kubectl apply -f . ... role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created service/prometheus-k8s created serviceaccount/prometheus-k8s created unable to recognize "0prometheus-operator-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "alertmanager-alertmanager.yaml": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1" unable to recognize "alertmanager-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "grafana-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "kube-state-metrics-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "node-exporter-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-prometheus.yaml": no matches for kind "Prometheus" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-rules.yaml": no matches for kind "PrometheusRule" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-serviceMonitorApiserver.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-serviceMonitorCoreDNS.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-serviceMonitorKubeControllerManager.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-serviceMonitorKubeScheduler.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" unable to recognize "prometheus-serviceMonitorKubelet.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1" #由于配置文件有先后顺序,所以这边有一些文件没有获取到,这里没有关系。我们在从新apply刷新一下即可 [root@k8s-master1 manifests]# kubectl apply -f .
当我们部署成功之后,我们可以查看一下crd,yaml文件会自动帮我们创建crd文件。只有我们创建了crd文件,我们的serviceMonitor才会有用
[root@k8s-master1 manifests]# kubectl get crd NAME CREATED AT alertmanagers.monitoring.coreos.com 2019-07-09T17:38:48Z podmonitors.monitoring.coreos.com 2019-07-09T17:38:48Z prometheuses.monitoring.coreos.com 2019-07-09T17:38:48Z prometheusrules.monitoring.coreos.com 2019-07-09T17:38:49Z servicemonitors.monitoring.coreos.com 2019-07-09T17:38:49Z
其他的资源文件都会部署在一个命名空间下面,在monitoring里面是operator Pod对应的列表
[root@k8s-master1 manifests]# kubectl get pod -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 49m alertmanager-main-1 2/2 Running 0 48m alertmanager-main-2 2/2 Running 0 48m grafana-545d8c5576-8lgvg 1/1 Running 0 51m kube-state-metrics-c86f5648c-4ffdb 4/4 Running 0 25s node-exporter-7hthp 2/2 Running 0 51m node-exporter-r7np2 2/2 Running 0 51m node-exporter-ssbdr 2/2 Running 0 51m node-exporter-wd7jm 2/2 Running 0 51m prometheus-adapter-66fc7797fd-bd7gx 1/1 Running 0 51m prometheus-k8s-0 3/3 Running 1 49m prometheus-k8s-1 3/3 Running 1 49m prometheus-operator-7cfc488cdd-wtm8w 1/1 Running 0 51m
其中prometheus和alertmanager采用的StatefulSet,其他的Pod则采用deployment创建
[root@k8s-master1 manifests]# kubectl get deployments.apps -n monitoring NAME READY UP-TO-DATE AVAILABLE AGE grafana 1/1 1 1 53m kube-state-metrics 1/1 1 1 53m prometheus-adapter 1/1 1 1 53m prometheus-operator 1/1 1 1 53m [root@k8s-master1 manifests]# kubectl get statefulsets.apps -n monitoring NAME READY AGE alertmanager-main 3/3 52m prometheus-k8s 2/2 52m #其中prometheus-operator是我们的核心文件,它是监控我们prometheus和alertmanager的文件
现在创建完成后我们还无法直接访问prometheus
[root@k8s-master1 manifests]# kubectl get svc -n monitoring |egrep "prometheus|grafana|alertmanage" alertmanager-main ClusterIP 10.106.59.84 9093/TCP 59m alertmanager-operated ClusterIP None 9093/TCP,6783/TCP 57m grafana ClusterIP 10.110.58.16 3000/TCP 59m prometheus-adapter ClusterIP 10.105.34.241 443/TCP 59m prometheus-k8s ClusterIP 10.102.246.32 9090/TCP 59m prometheus-operated ClusterIP None 9090/TCP 57m prometheus-operator ClusterIP None 8080/TCP 59m
由于默认的yaml文件svc采用的是ClusterIP,我们无法进行访问。这里我们可以使用ingress进行代理,或者使用node-port临时访问。我这里就修改一下svc,使用node-port进行访问
#我这里使用edit进行修改,或者修改yaml文件apply下即可 kubectl edit svc -n monitoring prometheus-k8s #注意修改的svc是prometheus-k8s因为这个有clusterIP kubectl edit svc -n monitoring grafana kubectl edit svc -n monitoring alertmanager-main #三个文件都需要修改,不要修改错了。都是修改有clusterIP的 ... type: NodePort #将这行修改为NodePort
prometheus-k8s、grafana和alertmanager-main都是只修改type=clusterIP这行
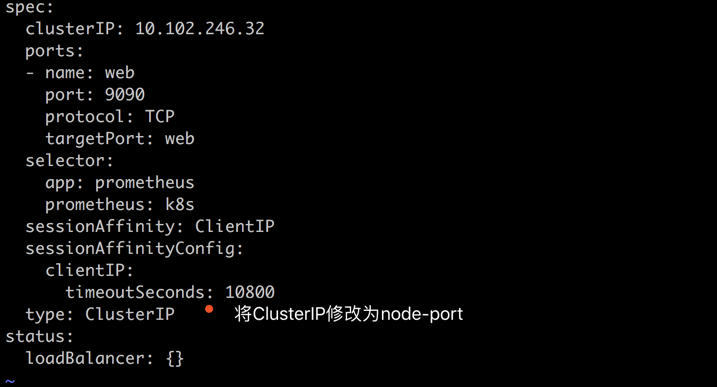
修改完毕后,我们在查看svc,就会发现这几个都包含node端口了,接下来在任意集群节点访问即可
#operator会自动帮我们刷新配置,我们需要修改的地方不是很多 [root@k8s-master1 manifests]# kubectl get svc -n monitoring |egrep "prometheus|grafana|alertmanage" alertmanager-main NodePort 10.106.59.84 9093:30857/TCP 66m alertmanager-operated ClusterIP None 9093/TCP,6783/TCP 64m grafana NodePort 10.110.58.16 3000:32479/TCP 66m prometheus-adapter ClusterIP 10.105.34.241 443/TCP 66m prometheus-k8s NodePort 10.102.246.32 9090:32556/TCP 66m prometheus-operated ClusterIP None 9090/TCP 64m prometheus-operator ClusterIP None 8080/TCP 66m
接下来我们查看prometheus的Ui界面
[root@abcdocker manifests]# kubectl get svc -n monitoring |grep prometheus-k8s prometheus-k8s NodePort 10.110.6.193 9090:31723/TCP 8m10s
我们访问的集群任意IP:31723
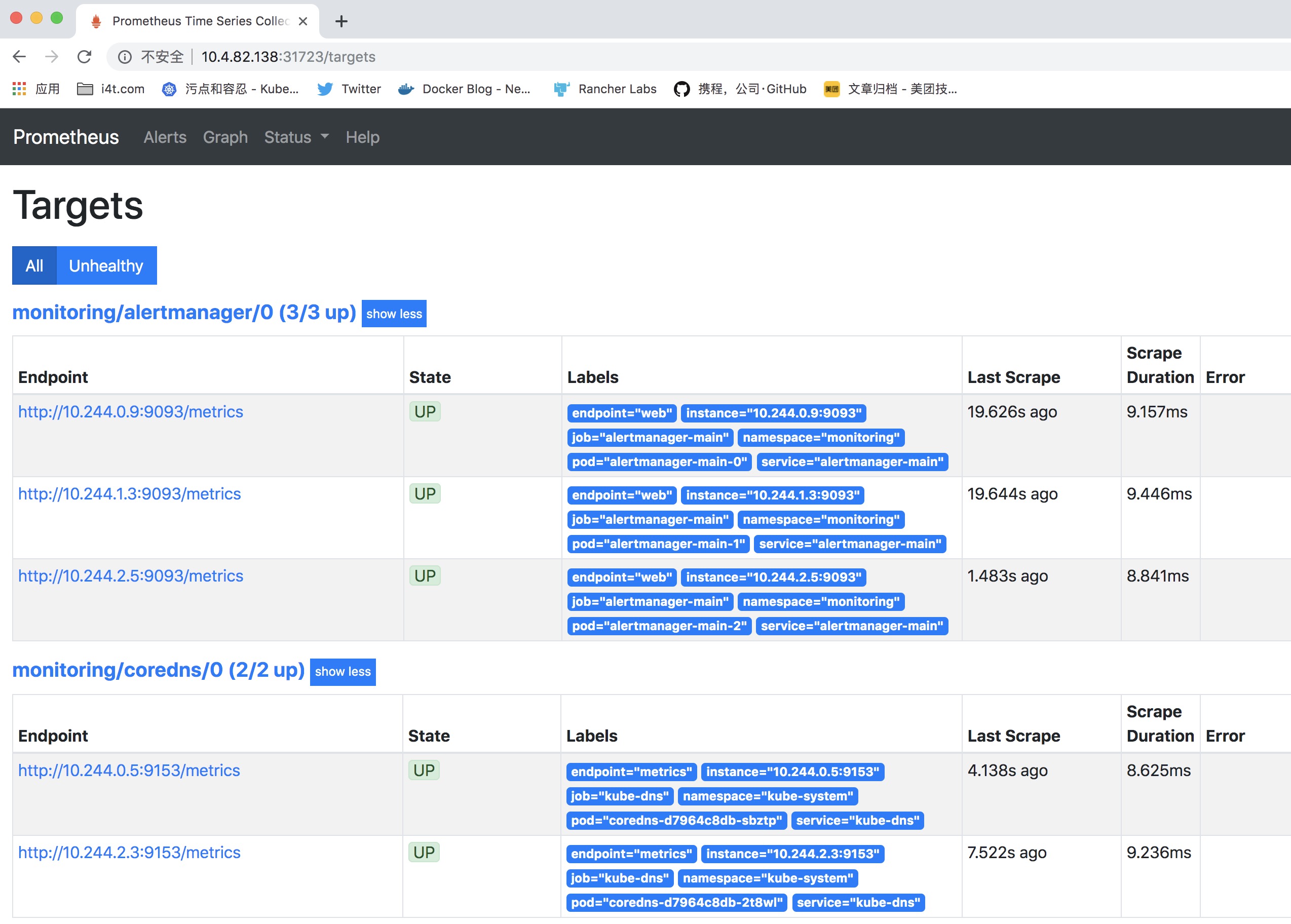
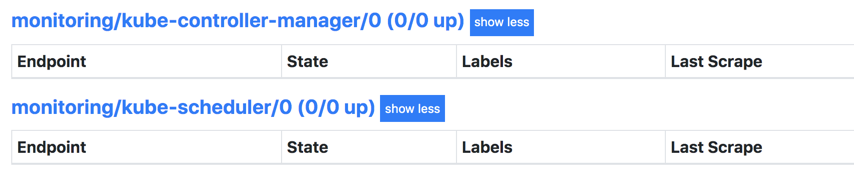
这里kube-controller-manager和kube-scheduler并管理的目标,其他的都有。这里的就是和我们yaml文件里面定义的有关系
配置文件解释
[root@yzsjhl82-138 ~]# cd kube-prometheus-master/manifests/
[root@yzsjhl82-138 manifests]# vim prometheus-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1 #kubectl get crd里面包含的,不进行修改
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler #定义的名称
namespace: monitoring
spec:
endpoints:
- interval: 30s
port: http-metrics #这里定义的就是在svc上的端口名称
jobLabel: k8s-app
namespaceSelector: #表示匹配哪一个命名空间,配置any:true则回去所有命名空间中查询
matchNames:
- kube-system
selector: #这里大概意思就是匹配kube-system命名空间下具有k8s-app=kube-scheduler标签的svc
matchLabels:
k8s-app: kube-scheduler
这时候我们可以手动匹配一下,根据yaml文件的配置是匹配kube-system命名空间下标签为k8s-app=kube-scheduler
#通过匹配可以看到,在kube-system没有一个标签为kube-scheduler [root@abcdocker manifests]# kubectl get svc -n kube-system -l k8s-app=kube-scheduler No resources found. [root@abcdocker manifests]# kubectl get svc -n kube-system -l k8s-app=kubelet NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubelet ClusterIP None 10250/TCP 24h
要想要kube-scheduler关联上,我们就需要手动创建一个svc
未完=========


我按照你这篇文章部署了Prometheus Operator,想问一下,确认一下几点是否需要我自行配置呢?
1.存储的持久化。
2.如果k8s新产生的pod需要配置其监控及告警规则。
目前prometheus operator是支持自动发现的,新的pod和新的svc是会自动发现并按照默认的规则进行报警的。 持久化存储现在使用的是crd。这个 CRD 创建的 Prometheus 并没有做数据的持久化,如果需要你可以需要创建storageclass 通过storageclass添加nfs-client进行持久化
希望能得到你的答复,并加入到abcdocker
prometheus operator改的地方还是比较多,唯一的好处就是快捷。 当然你也可以自定义operator
grafana的默认用户名密码多少?
账号密码默认都是admin
如果镜像存在拉取不下来,或者网络问题。可以直接使用我提供的镜像,包括已经在墙外的镜像。新版本对应的镜像可以到阿里云镜像仓库拉取
http://down.i4t.com/prometheus-operator/addon-resizer.tar
http://down.i4t.com/prometheus-operator/prometheus-operator.tar
alertmanager只有一个pod(alertmanager-main-0),状态有时是CrashLoopBackOff,有时是Running,Ready是1/2,这是什么原因呢