
Grafana 安装并监控k8s集群
Grafana

由于Prometheus自带的web Ui图标功能相对较弱,所以一般情况下我们会使用一个第三方的工具来展示这些数据
Grafana介绍
grafana 是一个可视化面包,有着非常漂亮的图片和布局展示,功能齐全的度量仪表盘和图形化编辑器,支持Graphite、Zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticasearch等作为数据源,比Prometheus自带的图标展示功能强大很多,更加灵活,有丰富的插件
我们这里使用deployment持久化安装grafana
cat >>grafana_deployment.yaml <<EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: grafana
namespace: kube-system
labels:
app: grafana
spec:
revisionHistoryLimit: 10
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:5.3.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: abcdocker
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 300m
memory: 1024Mi
requests:
cpu: 300m
memory: 1024Mi
volumeMounts:
- mountPath: /var/lib/grafana
subPath: grafana
name: storage
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
EOF
这里使用了grafana 5.3.4的镜像,添加了监控检查、资源声明,比较重要的变量是GF_SECURITY_ADMIN_USER和GF_SECURITY_ADMIN_PASSWORD为grafana的账号和密码。
由于grafana将dashboard、插件这些数据保留在/var/lib/grafana目录下,所以我们这里需要做持久化,同时要针对这个目录做挂载声明,由于5.3.4版本用户的userid和groupid都有所变化,所以这里添加了一个securityContext设置用户ID

现在我们添加一个pv和pvc用于绑定grafana
cat >>grafana_volume.yaml <<EOF
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 10.4.82.138
path: /data/k8s
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: kube-system
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
EOF
这里配置依旧使用NFS进行挂载使用
现在我们还需要创建一个service,使用NodePort
cat >>grafana_svc.yaml<<EOF
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-system
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
EOF
由于5.1(可以选择5.1之前的docker镜像,可以避免此类错误)版本后groupid更改,同时我们将/var/lib/grafana挂载到pvc后,目录拥有者可能不是grafana用户,所以我们还需要添加一个Job用于授权目录
cat grafana_job.yaml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: grafana-chown
namespace: kube-system
spec:
template:
spec:
restartPolicy: Never
containers:
- name: grafana-chown
command: ["chown", "-R", "472:472", "/var/lib/grafana"]
image: busybox
imagePullPolicy: IfNotPresent
volumeMounts:
- name: storage
subPath: grafana
mountPath: /var/lib/grafana
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
EOF
这里使用一个busybox镜像将/var/lib/grafana目录修改为权限472
#需要先创建pv和pvc (这里是需要安装顺序来创建) kubectl create -f grafana_volume.yaml kubectl create -f grafana_job.yaml kubectl create -f grafana_deployment.yaml kubectl create -f grafana_svc.yaml
创建完成后我们打开grafana的dashboard界面
[root@abcdocker grafana]# kubectl get svc -n kube-system |grep grafana grafana NodePort 10.98.192.213 3000:32452/TCP 9h
然后我们在任意集群中的节点访问端口为32452
这里的集群密码就是上面我们创建deployment里面设置的变量,我这里用户设置为admin密码abcdocker

登陆到grafana就显示到了我们的引导界面
第一次创建grafana需要添加数据源
类型选择prometheus
这里的地址我们填写下面的url
这里的prometheus代表service名称
kube-system代表命名空间
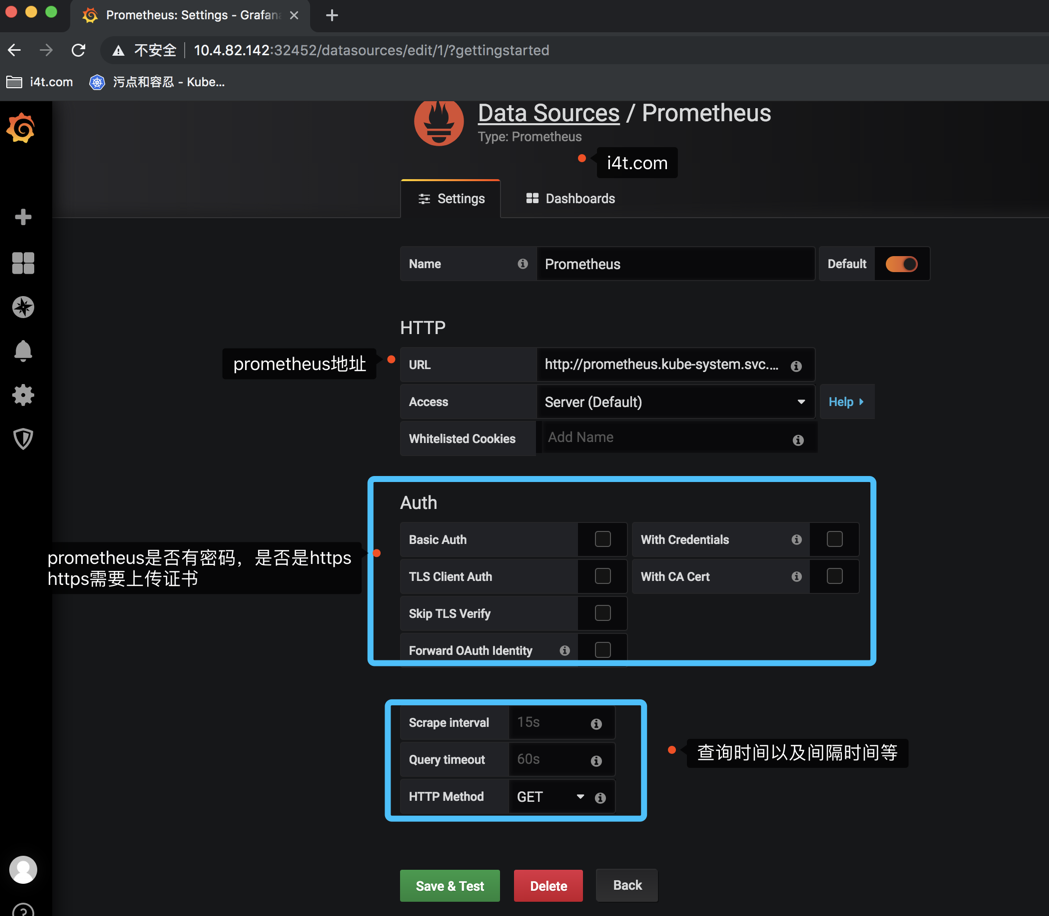
这里的Access配置要说明一下
服务器(Server)访问模式(默认):所有请求都将从浏览器发送到 Grafana 后端的服务器,后者又将请求转发到数据源,通过这种方式可以避免一些跨域问题,其实就是在 Grafana 后端做了一次转发,需要从Grafana 后端服务器访问该 URL。 浏览器(Browser)访问模式:所有请求都将从浏览器直接发送到数据源,但是有可能会有一些跨域的限制,使用此访问模式,需要从浏览器直接访问该 URL。
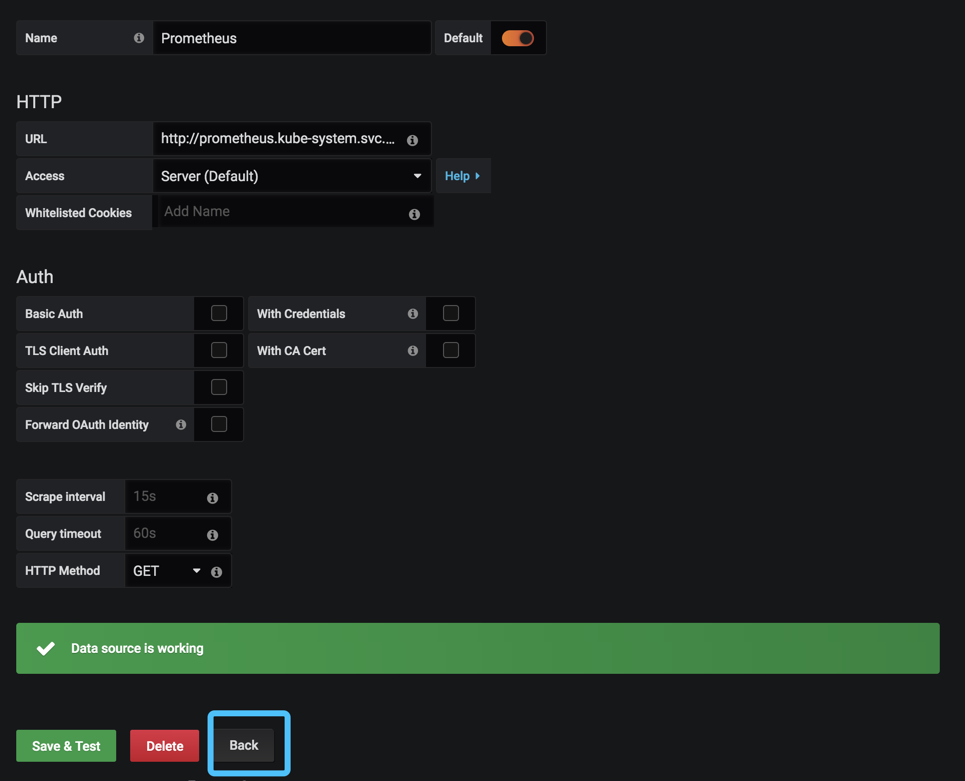
我们可以检查一下数据源是否配置成功
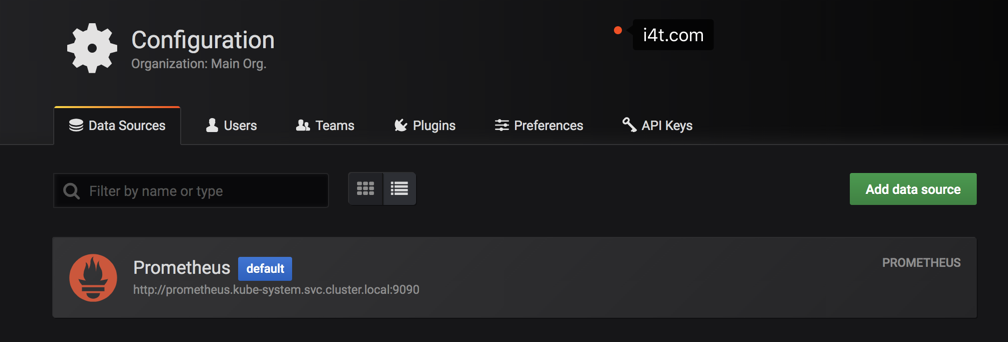
数据源添加完毕后,接下来添加New dashboard
这里我们可以自定义模板,或者可以使用别人写好的模板 (写好的模板后面是需要我们自己修改的)
grafana提供了很多模板,类似和docker镜像仓库一下。导入模板也极其简单。点击上方的Dashboard
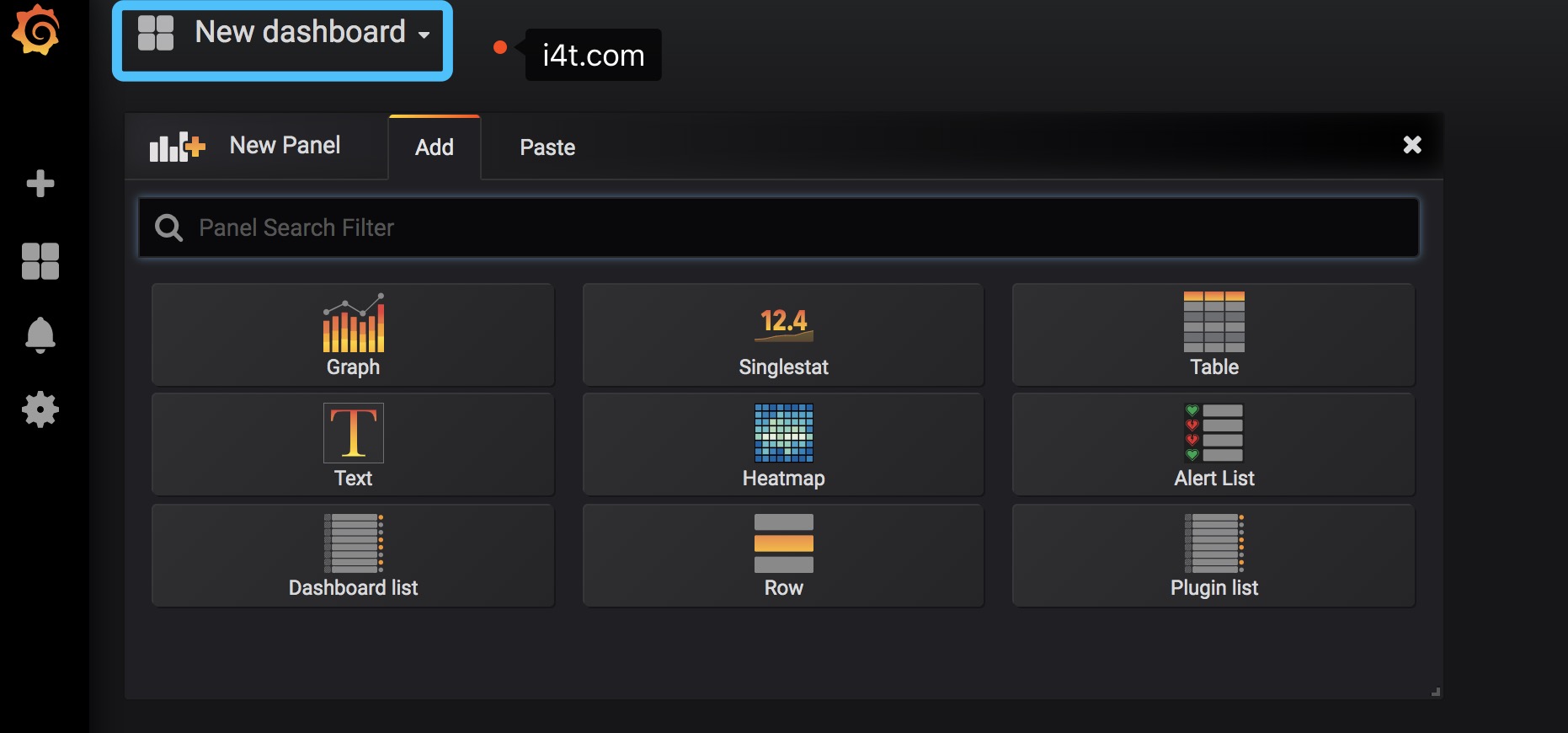
这里面的模板都是公共的,可以免费使用
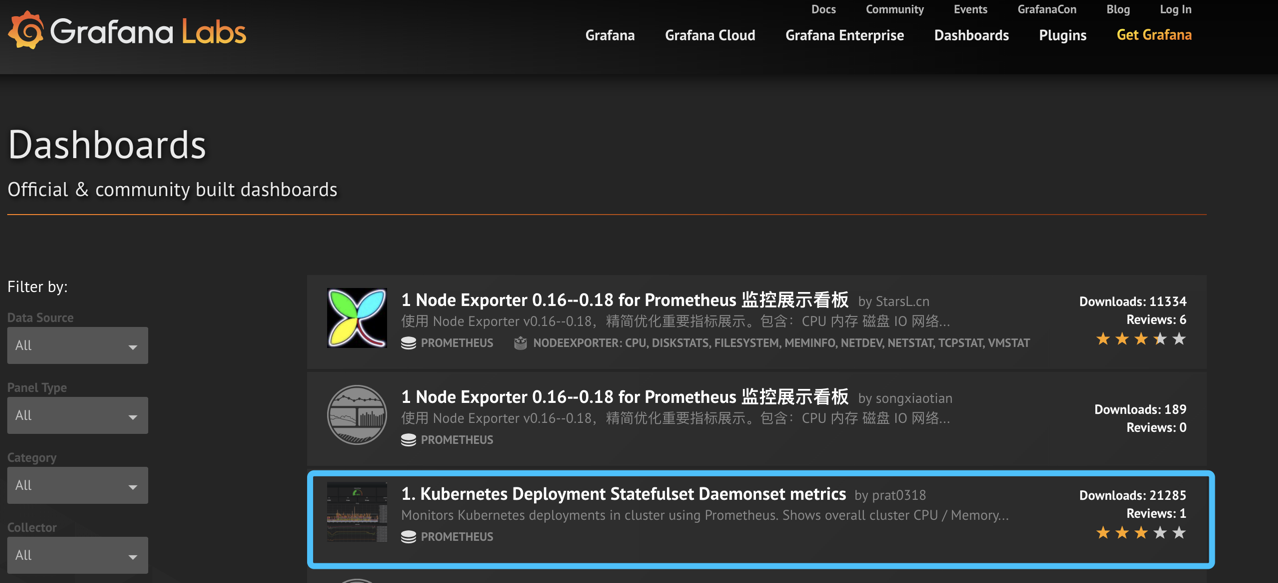
点进去任意一个模板后,我们可以看到ID,复制ID然后在返回grafana
我这里添加一个监控Kubernetes集群。显示整体群集CPU、内存、磁盘使用情况以及单个pod统计信息。
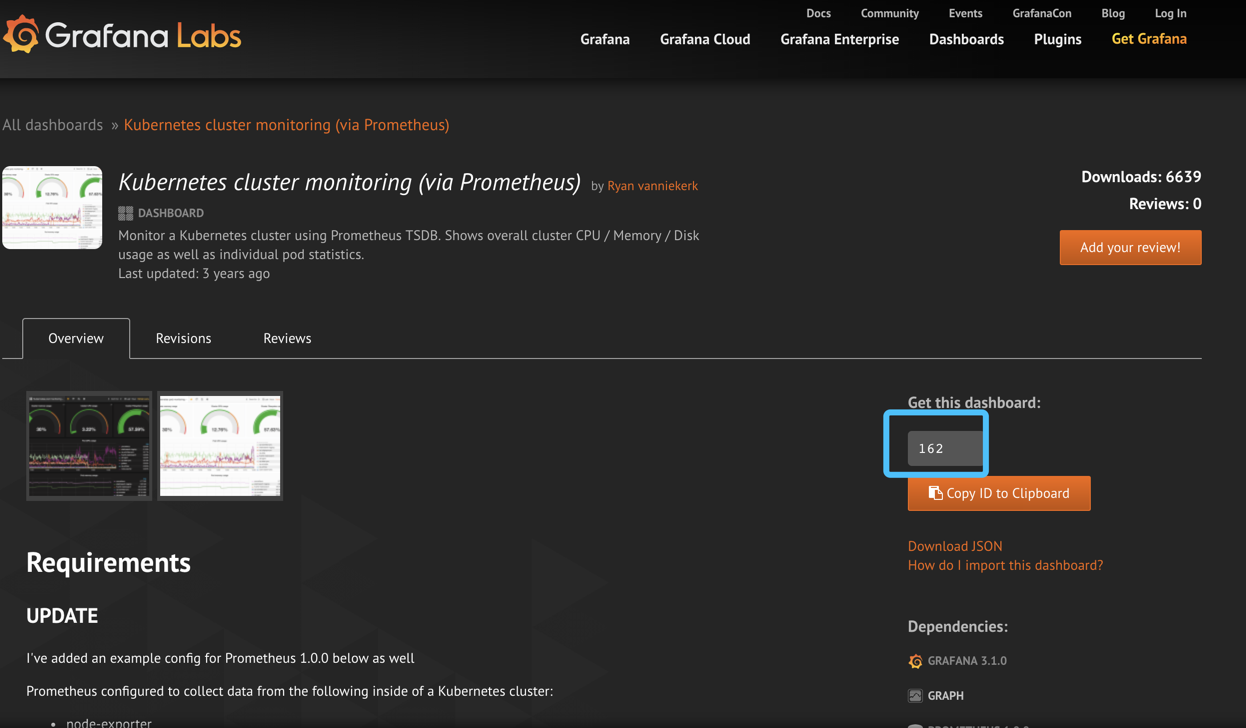
点击导入模板

在这里我们输入162或者url,会自动跳转到配置页面
https://grafana.com/dashboards/162
选择好数据源之后,我们在点击Import即可
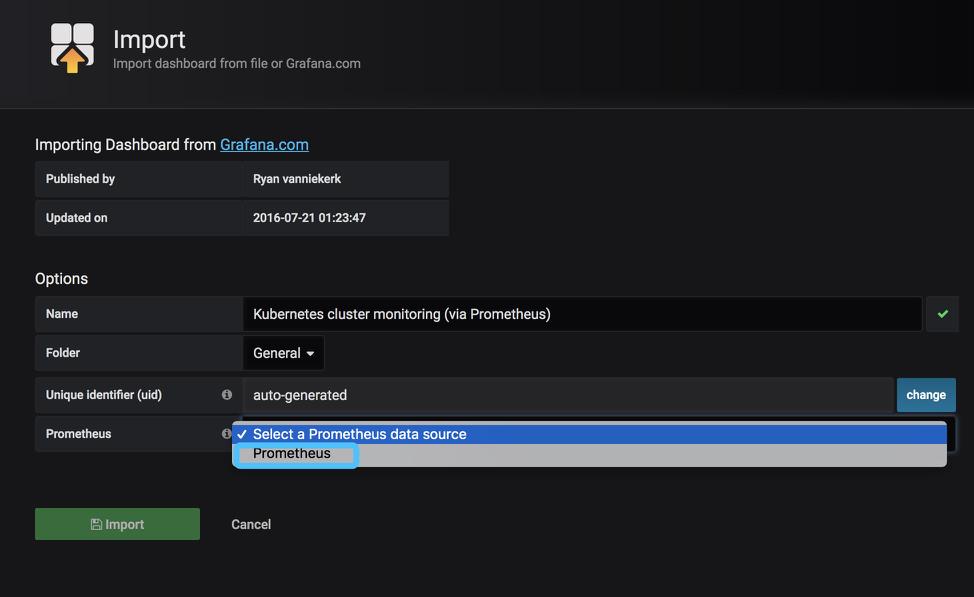
这里就会将模板162给我们导入进行
这里就会获取我们prometheus里面的数据了
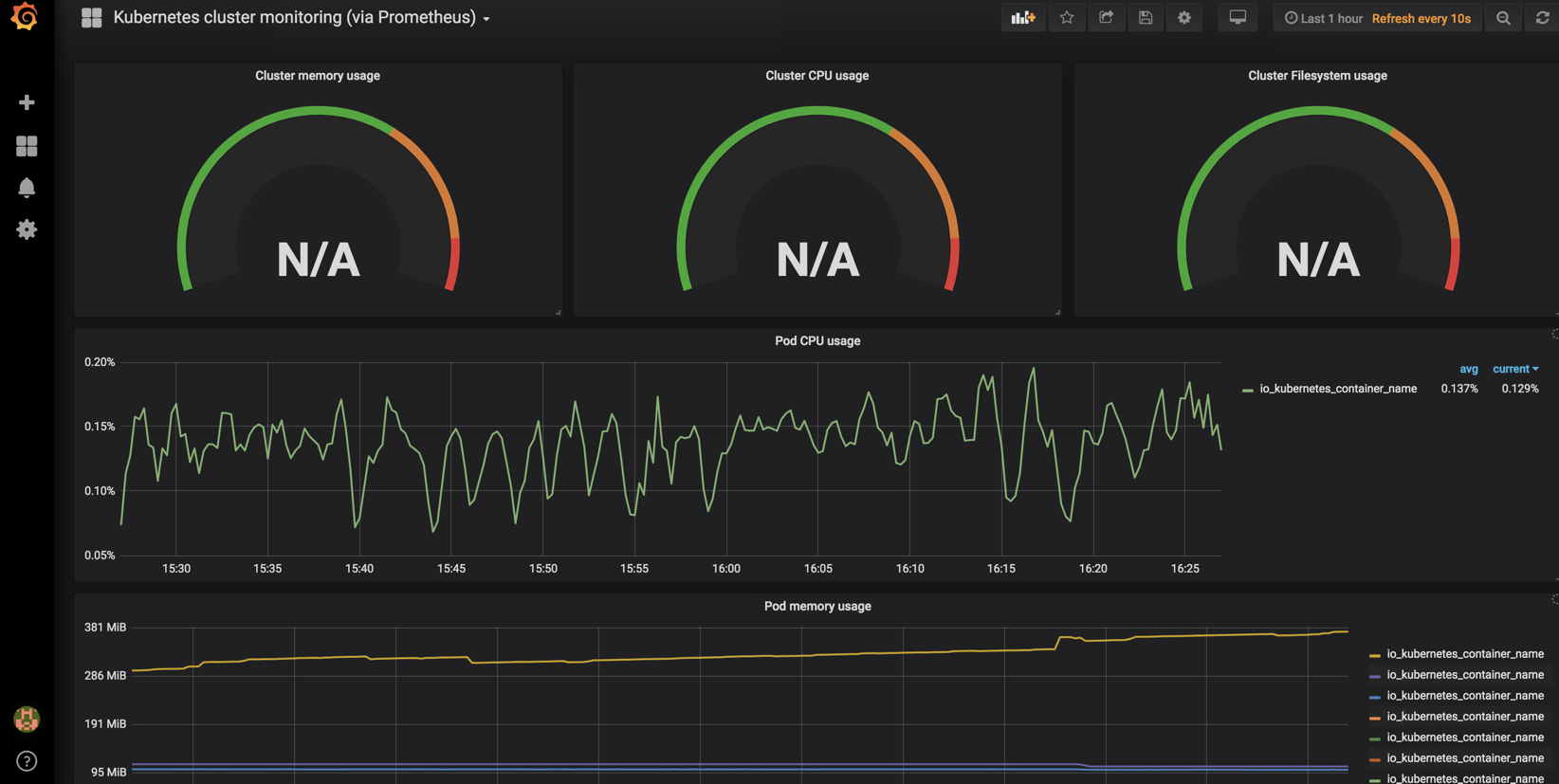
现在的模板还没有进行保存,我们要点击保存一下
现在就保存下来了
目前我们导入模板之后是无法直接使用滴
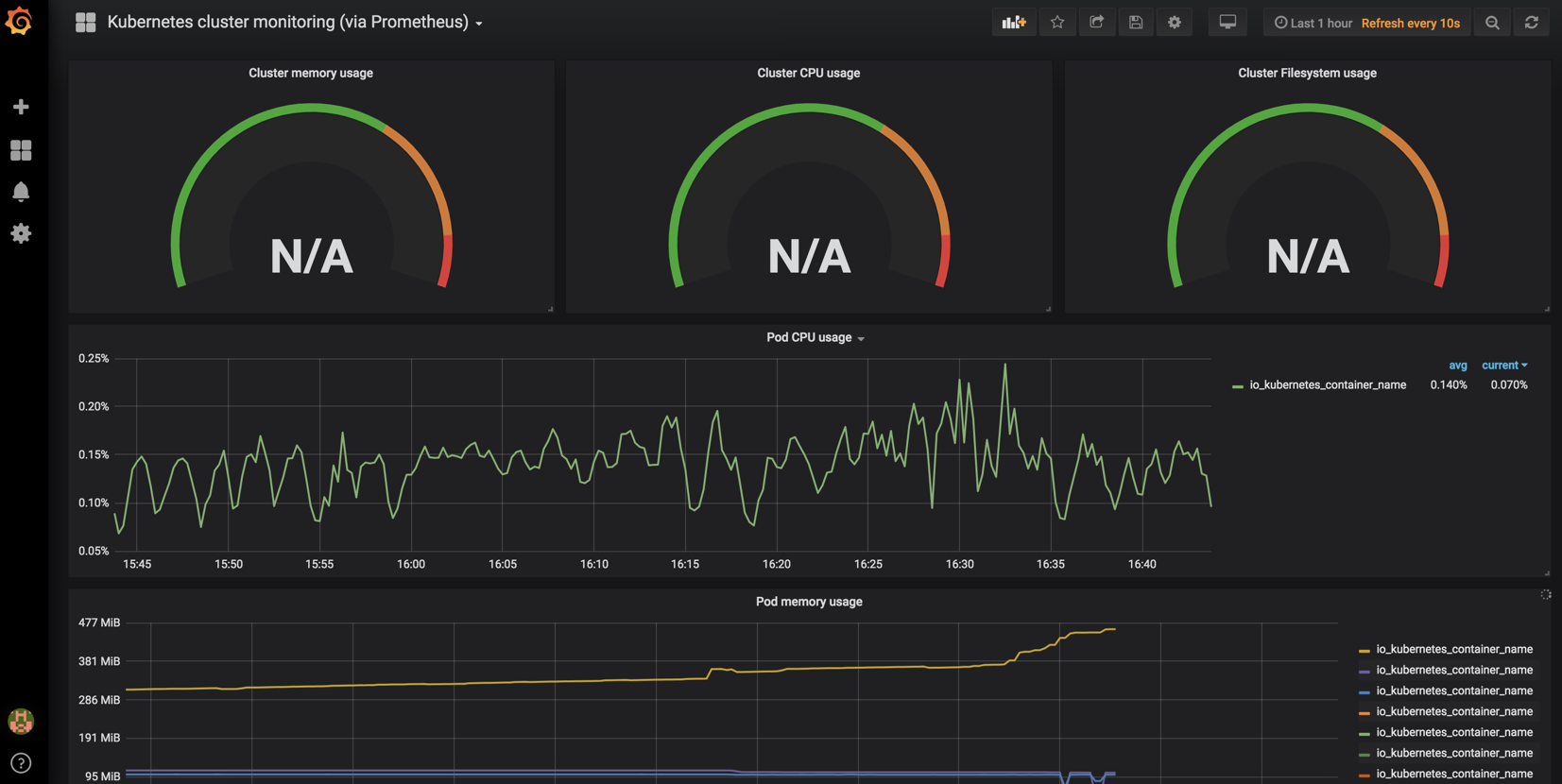
这里无法显示是由于模板定义的标签,我们prometheus并没有这个数据元,所以说我们要对模板进行修改!
在修改之前我们先设置一下时区,grafana默认走的是浏览器时区,但是prometheus使用的是
UTC时区
修改默认模板 (我这里使用的是162模板,下面模板修改请根据我的操作步骤进行操作)
grafana模板修改
前面的步骤必须和我相同,否则这里可能会无法出现值
首先我们进行编辑 Cluster memory usage (集群内存使用率)
计算方式就是(整个集群的内存-(整个集群剩余的内存以及Buffer和Cached))/整
(sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes)) / sum(node_memory_MemTotal_bytes) * 100
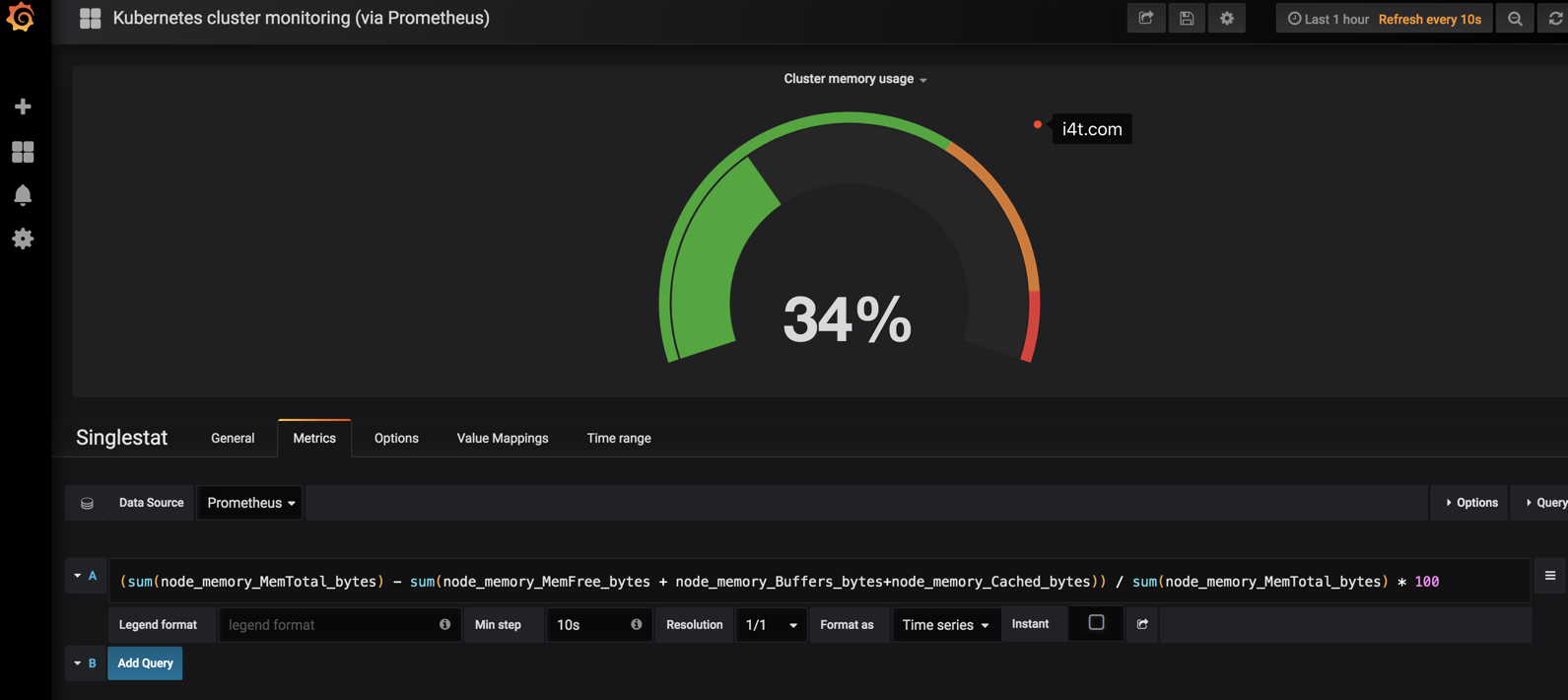
这里要说明一点,这里填写的是PromSQL,也就是说是可以在prometheus查询到的。 如果查询不到grafana也是会获取不到数据的
这里在prometheus是可以获取到的
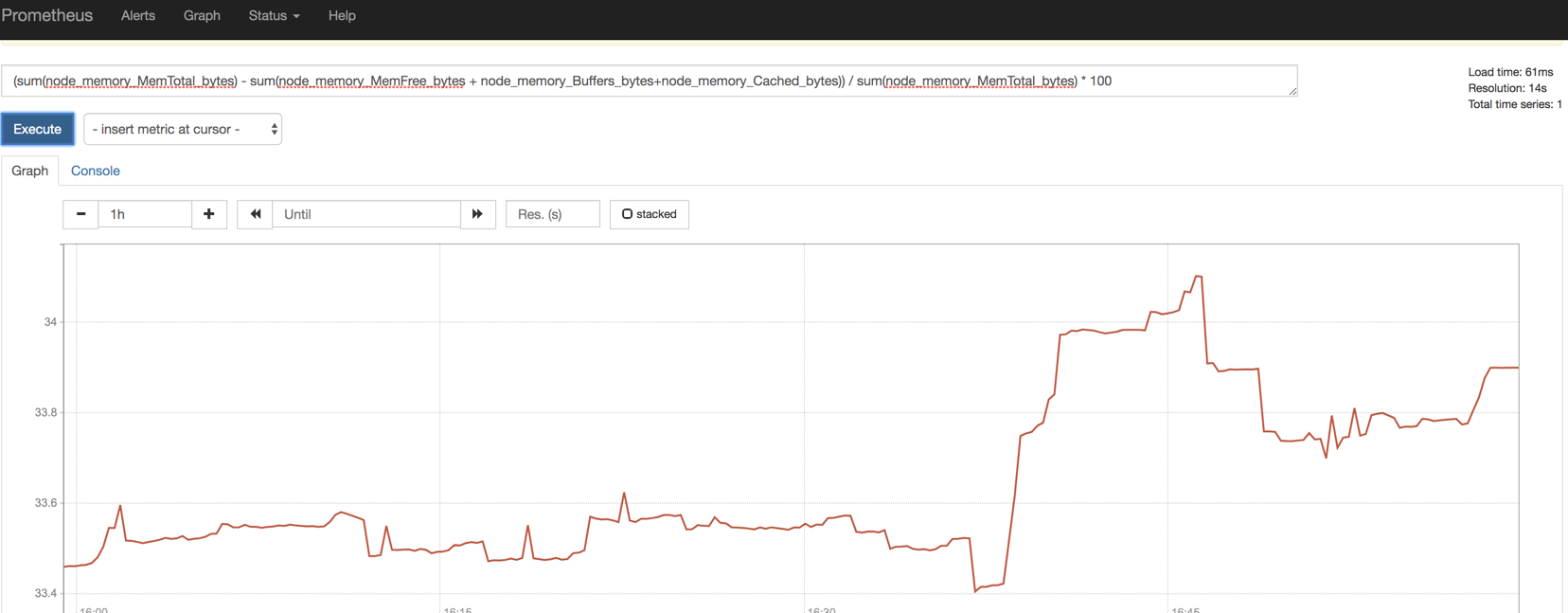
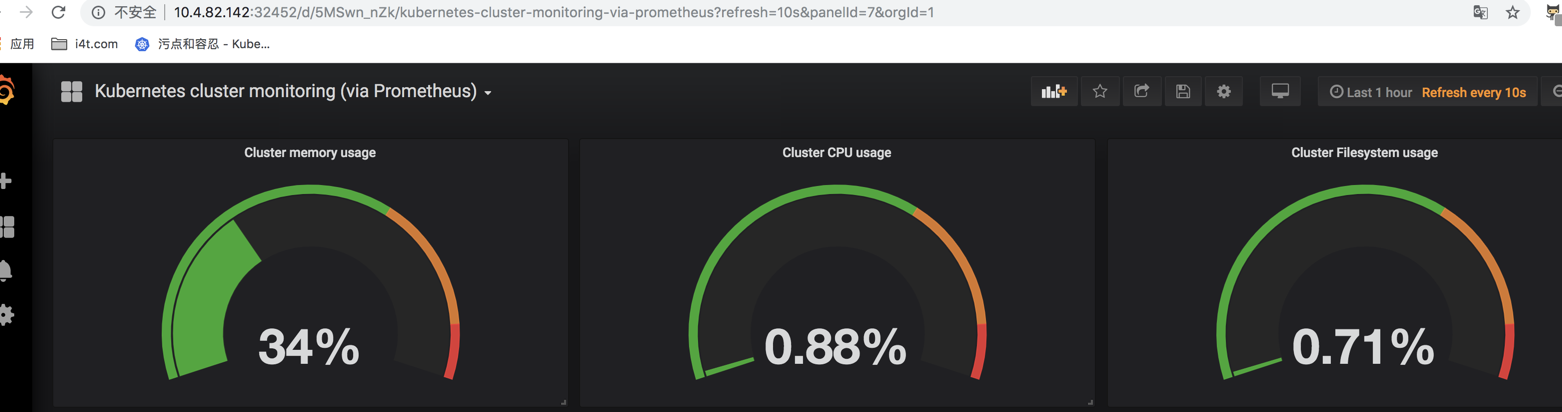
Cluster memory usage 配置如下 (集群内存使用率)
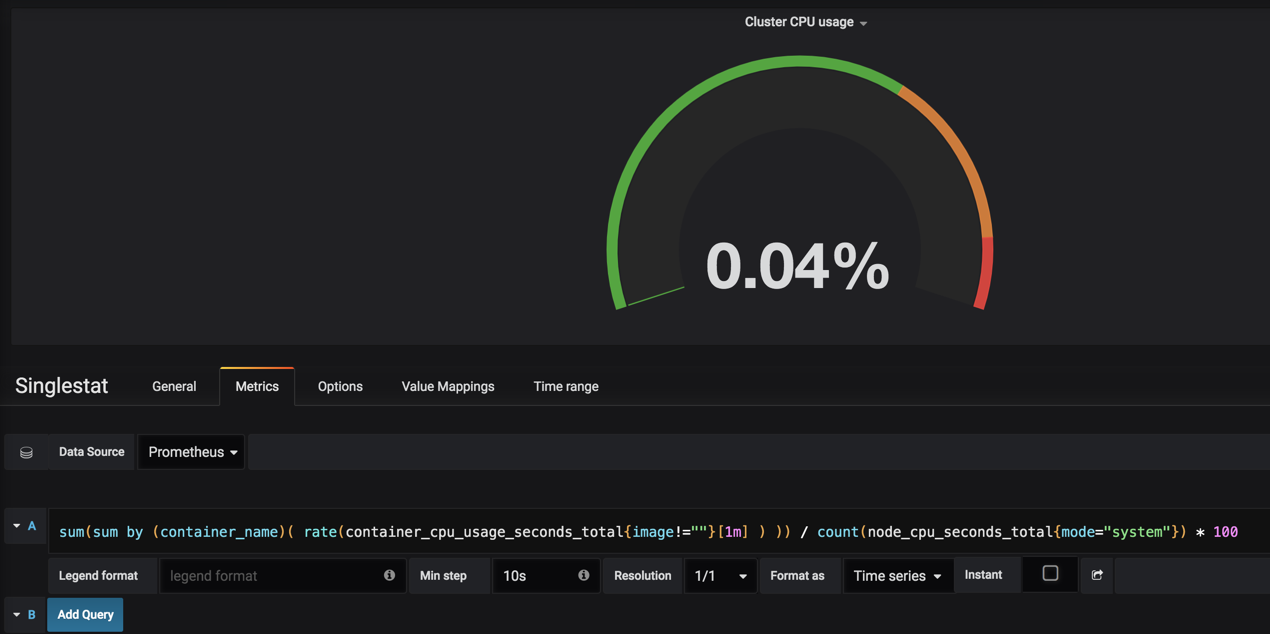
sum(sum by (container_name)( rate(container_cpu_usage_seconds_total{image!=""}[1m] ) )) / count(node_cpu_seconds_total{mode="system"}) * 100
Cluster filesystem usage 集群文件系统使用率
(sum(node_filesystem_size_bytes{device="tmpfs"}) - sum(node_filesystem_free_bytes{device="tmpfs"}) ) / sum(node_filesystem_size_bytes{device="tmpfs"}) * 100
这里如果不出值可以在冒泡专区发截图,在截图中执行df -h -T
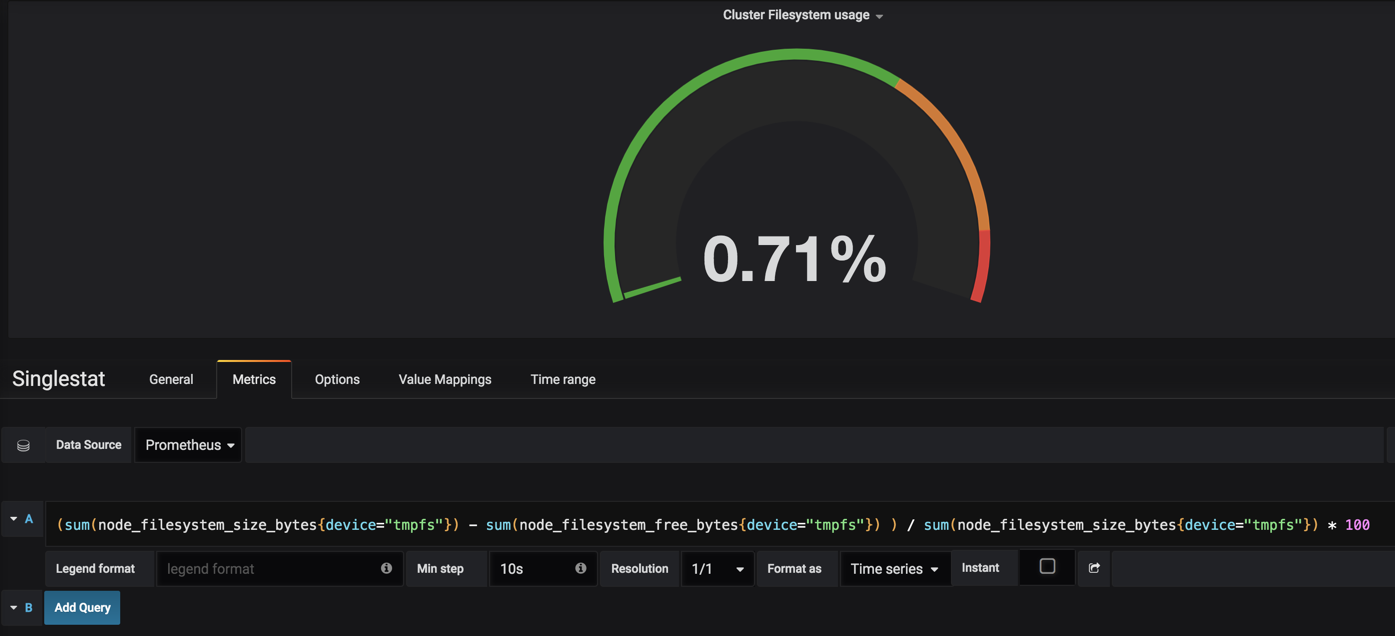
这里我们就获取到数据了
接下来我们配置集群中Pod cpu使用率
sum by (pod_name)(rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m]))
下面显示的地方配置
{{ pod_name }}

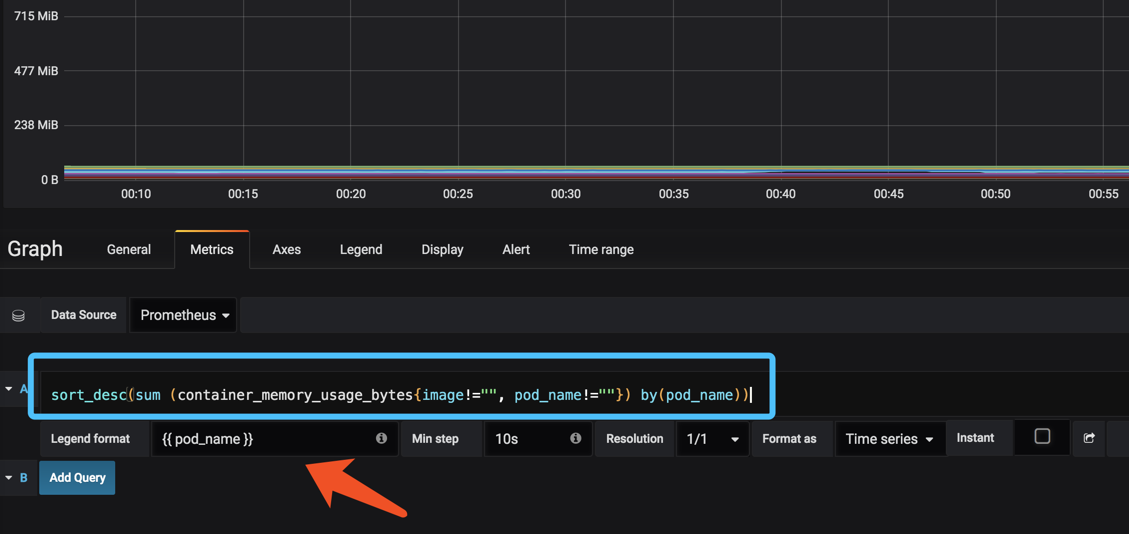
集群pod 内存使用率
sort_desc(sum (container_memory_usage_bytes{image!="", pod_name!=""}) by(pod_name))
下面显示的名称同样也是{{ pod_name }}
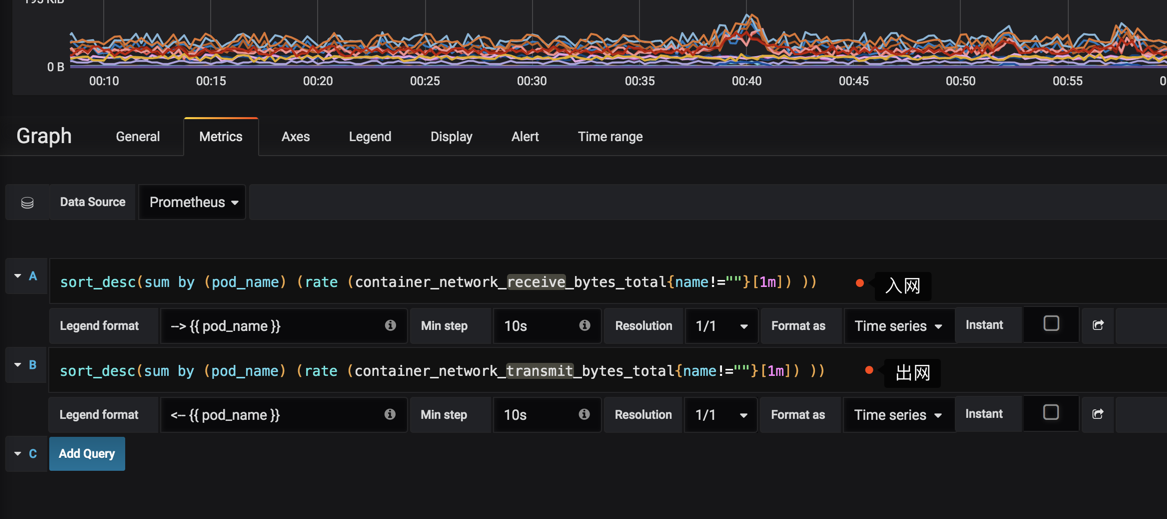
最后我们配置一下Pod 网络监控
1.入口流量
sort_desc(sum by (pod_name) (rate (container_network_receive_bytes_total{name!=""}[1m]) ))
2.出口流量
sort_desc(sum by (pod_name) (rate (container_network_transmit_bytes_total{name!=""}[1m]) ))
#监控时间为1分钟
效果图如下 记得点击保存
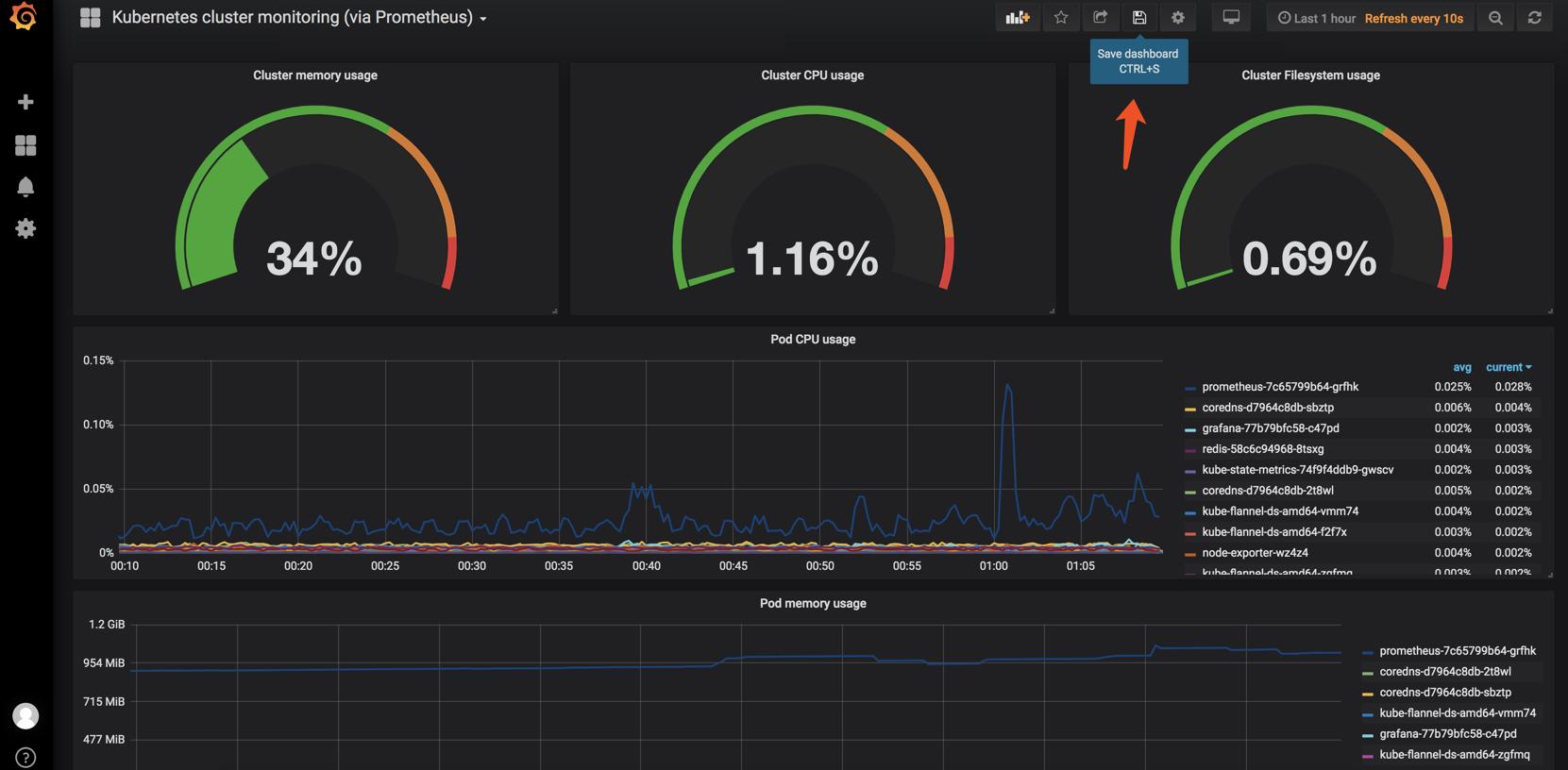
所有的PromSQL都是可以在prometheus获取到数据的!
各位看官如果有问题可以前往论坛专区发帖求助
请务必和我环境保持一致


继续努力小伙子 ✗肌肉✗
少了 “>”
了解,尽快我修改
安装文档,没有图像,请教什么原因?
有7小时时区问题,只要你能获取到mertic就行
在Prometheus执行都提示No datapoints found.
Prometheus是按照”Prometheus 持久化安装”安装的。但是查不到数据
1.Cluster memory usage (集群内存使用率)
->(sum(node_memory_MemTotal_bytes) – sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes)) / sum(node_memory_MemTotal_bytes) * 100
3.Cluster cpu usage (集群CPU使用率)
->sum(sum by (container_name)( rate(container_cpu_usage_seconds_total{image!=””}[1m] ) )) / count(node_cpu_seconds_total{mode=”system”}) * 100
2.Cluster filesystem usage(集群文件系统使用率)
->(sum(node_filesystem_size_bytes{device=”tmpfs”}) – sum(node_filesystem_free_bytes{device=”tmpfs”}) ) / sum(node_filesystem_size_bytes{device=”tmpfs”}) * 100
是要先处理“Prometheus监控Kubernetes 集群节点及应用”吗?
对滴,你要看你prometheus监控了哪些指标,有没有node_exporter,如果没有你需要安装一下,没有node_exporter是获取不到服务器的资源的
今天上午 网站挂了 ,我以为你跑路了
昨晚调整cdn了,早上起来才发现