
强大的Grafana k8s 插件
Grafana

Dashboard的时间需要修改改一下,改成UTC并且+10小时
之前我们说过grafana监控K8s,当时使用的模板,自己进行修改的值。grafana有一个专门针对Kubernetes集群监控的插件
效果图
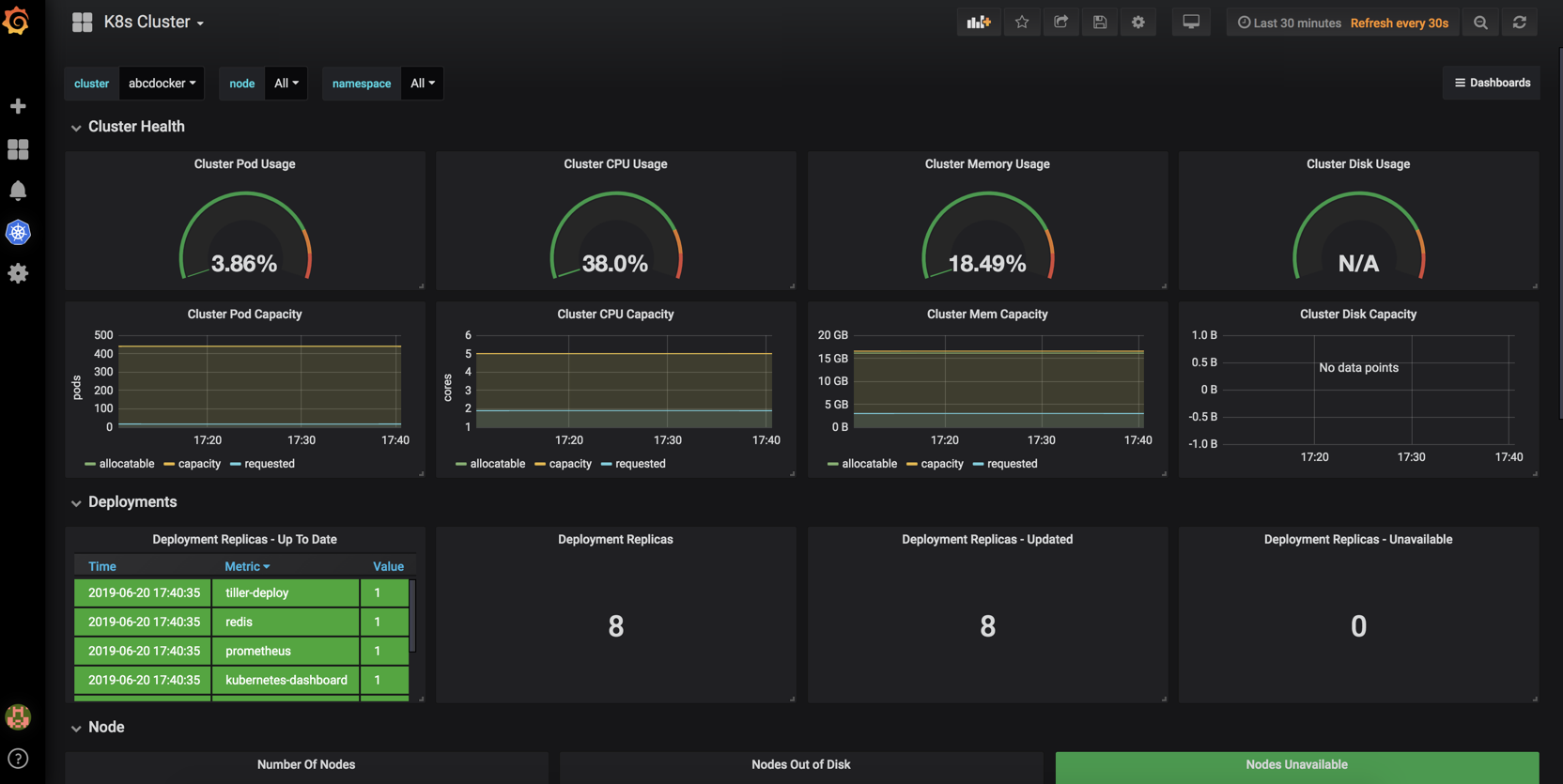
Grafana Kubernetes应用程序允许您监控Kubernetes集群的性能。它包括4个仪表板,集群,节点,Pod /容器和部署。它允许自动部署所需的Prometheus导出器和默认的scrape配置,以用于集群中的Prometheus部署。收集的指标包括高级别群集和节点统计信息以及较低级别的容器和容器统计信息。使用高级指标进行提醒,使用低级指标进行故障排除。
# 官方文档grafana-kubernetes-app插件说明 要求 目前只支持普罗米修斯 对于出口商的自动部署,则需要Kubernetes 1.6或更高版本。 Grafana 5.0.0+ 特征 该应用程序使用Kubernetes标记来过滤pod指标。Kubernetes集群往往有很多pod和很多pod指标。Pod / Container仪表板利用pod标签,因此您可以轻松找到相关的pod或pod。 轻松安装导出器,无论是从Grafana单击部署还是使用kubectl手动部署它们的详细说明(也非常简单!) Heapster中不可用的群集级别度量标准,如CPU容量与CPU使用率。 群集指标 Pod容量/用法 内存容量/使用情况 CPU容量/使用率 磁盘容量/使用情况 节点,窗格和容器概述 节点度量标准 中央处理器 内存可用 每个CPU加载 读取IOPS 写IOPS %的Util 网络流量/秒 网络数据包/秒 网络错误/秒 Pod / Container度量标准 内存使用情况 网络流量 CPU使用率 读取IOPS 写IOPS
我们可以在grafana 面包上的插件找到
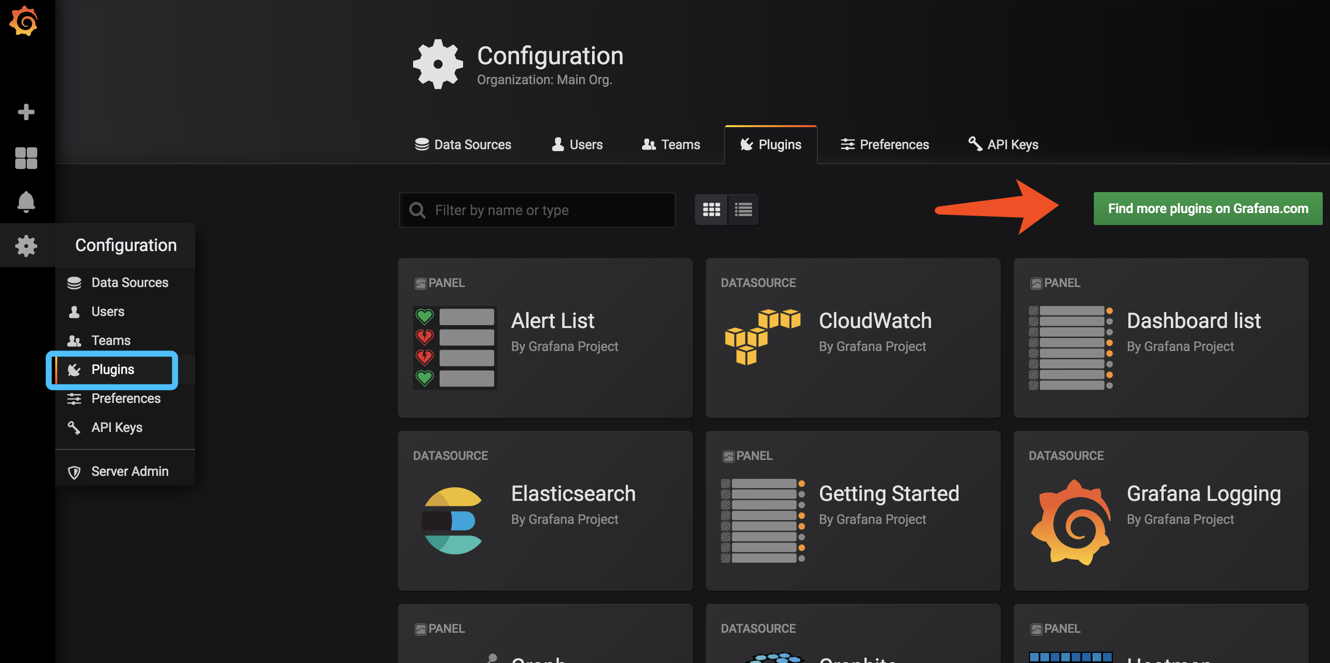
这里有很多grafana提供的插件可以给我们使用

这里还可以选择版本
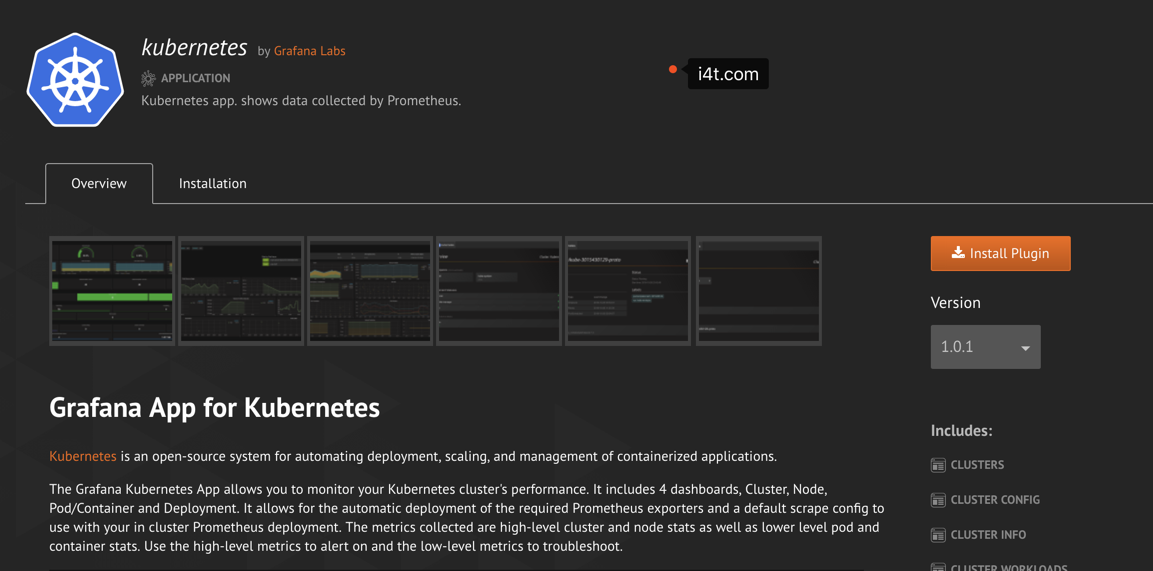
插件安装
如果想要安装这个插件需要进行到Pod里面,或者将插件上传到pod /var/lib/grafana/plugins
# 首先要找到Pod [root@abcdocker ~]# kubectl get pod -n kube-system |grep grafana grafana-77b79bfc58-c47pd 1/1 Running 0 22h grafana-chown-qsctd 0/1 Completed 0 23h # 进入Pod [root@abcdocker ~]# kubectl exec -it --namespace=kube-system grafana-77b79bfc58-c47pd bash # 使用grafana-cli下载插件 grafana-cli plugins install grafana-kubernetes-app
步骤截图
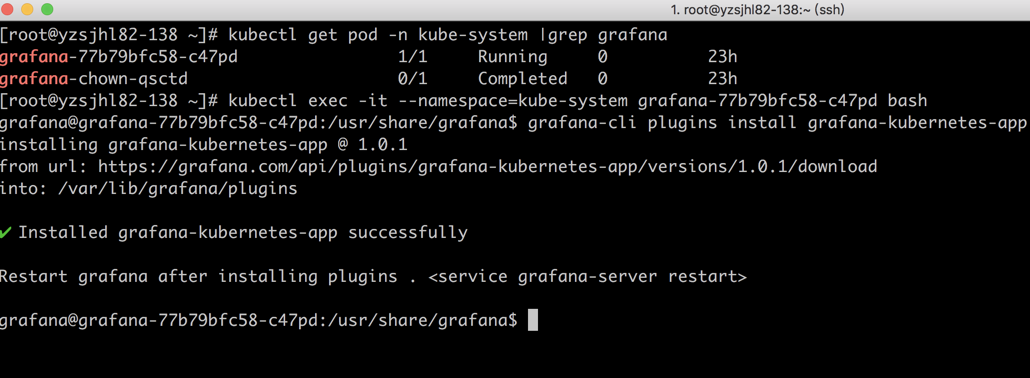
由于需要重启生效,我们这里直接将Pod删除
[root@abcdocker ~]# kubectl get pod -n kube-system |grep grafana grafana-77b79bfc58-c47pd 1/1 Running 0 23h grafana-chown-qsctd 0/1 Completed 0 23h [root@abcdocker ~]# [root@abcdocker ~]# [root@abcdocker ~]# kubectl delete pod -n kube-system grafana-77b79bfc58-c47pd pod "grafana-77b79bfc58-c47pd" deleted # -n后面是命名空间,在后面是pod名称,要根据当前Pod的名称进行删除
当我们看到Pod启动成功后,我们这里继续访问grafana就可以

找到我们的插件

右手可以看到插件的版本和插件的说明
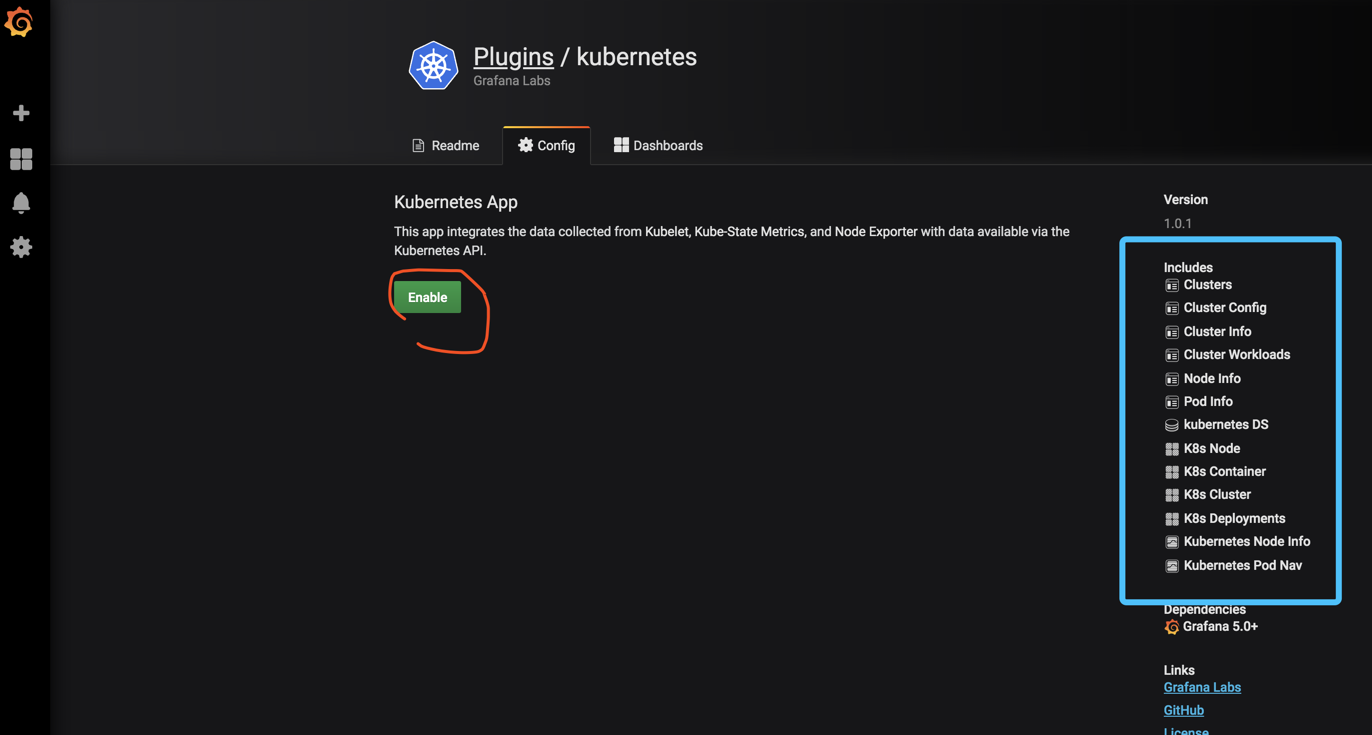
点击Enable之后,出现以下状态说明正常
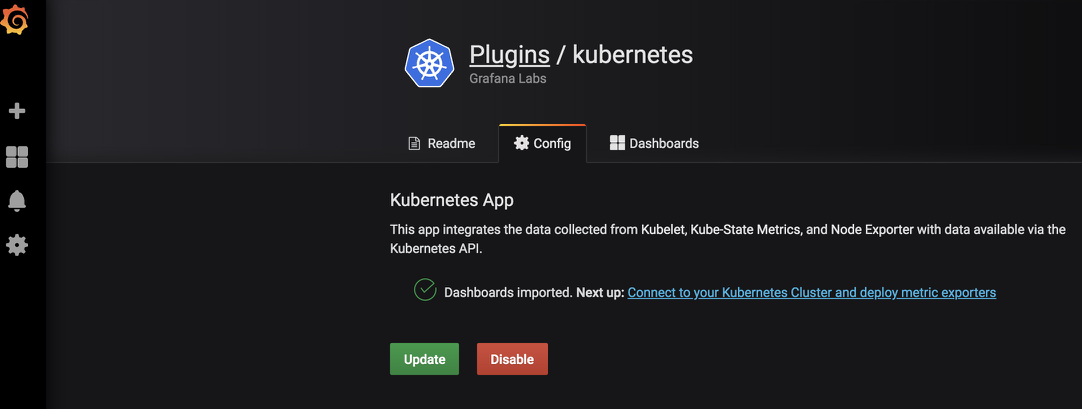
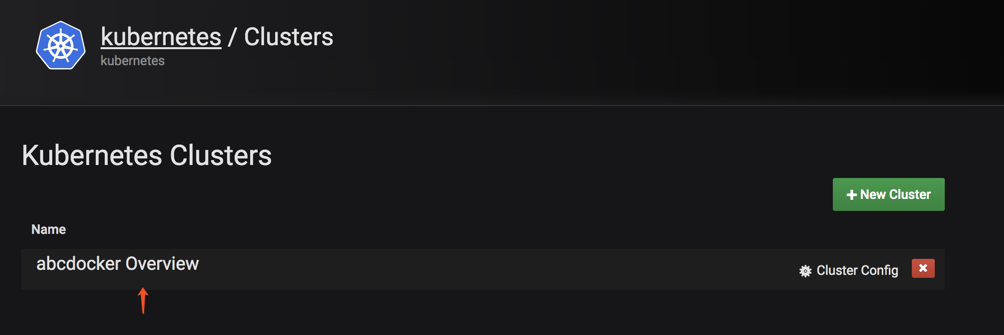
这时候我们点击左边的k8s小图表,点击创建集群

接下来就是配置我们的集群
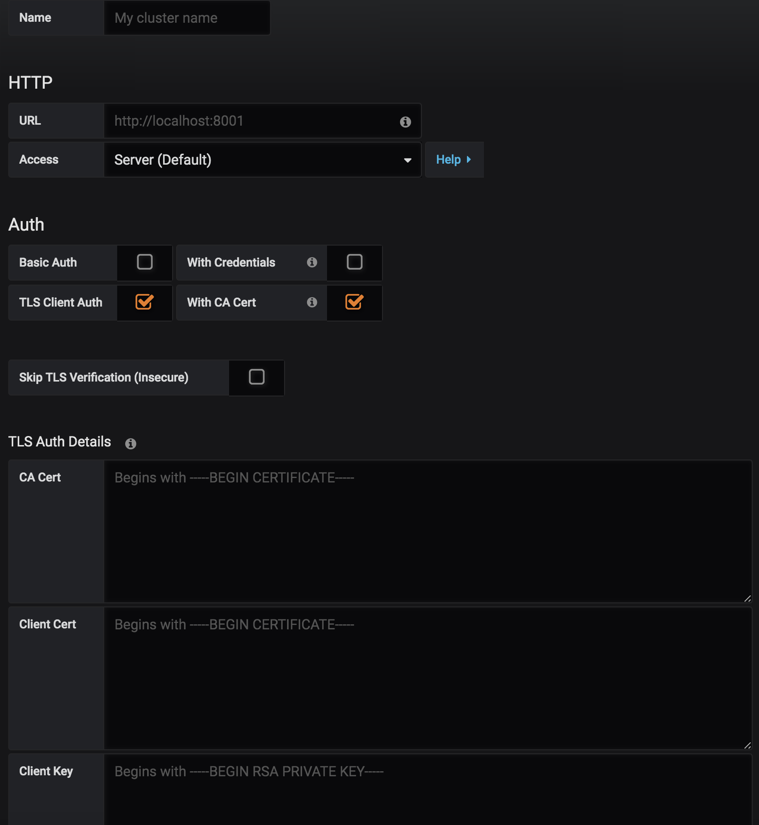
简单说明一下
Name 集群名称(自定义) URL Kubernetes Apiserver地址 因为apiserver是使用443端口,还需要开启https,并获取Key Datasource 选择数据源 (之前创建prometheus数据源)
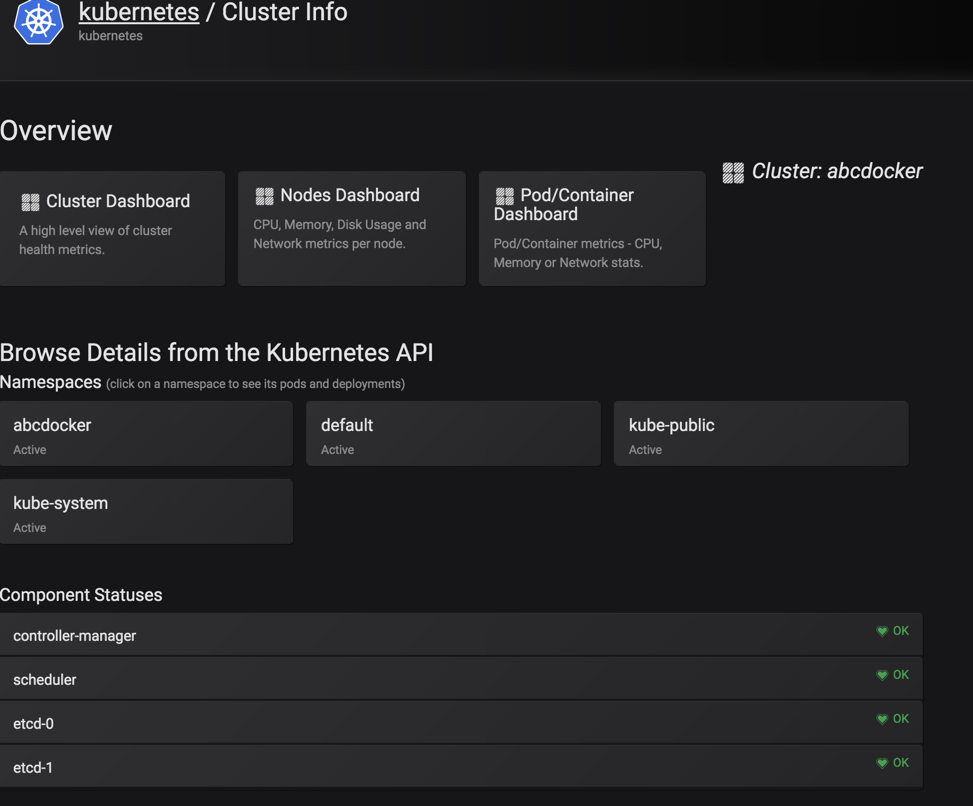
接下来我们需要查看api-server的信息
[root@abcdocker ~]# cat /root/.kube/config
certificate-authority-data = CA Cert 对应
server = https://10.4.82.141:8443 (这里是apiserver地址,我这里用的是vip,根据你们自己的环境配置)
client-certificate-data = Client Cert
client-key-data = Client Key
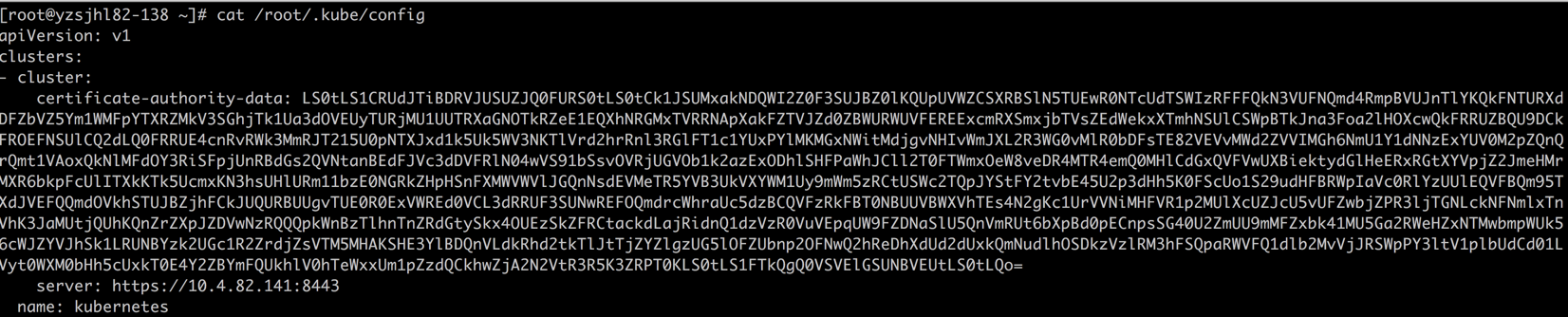
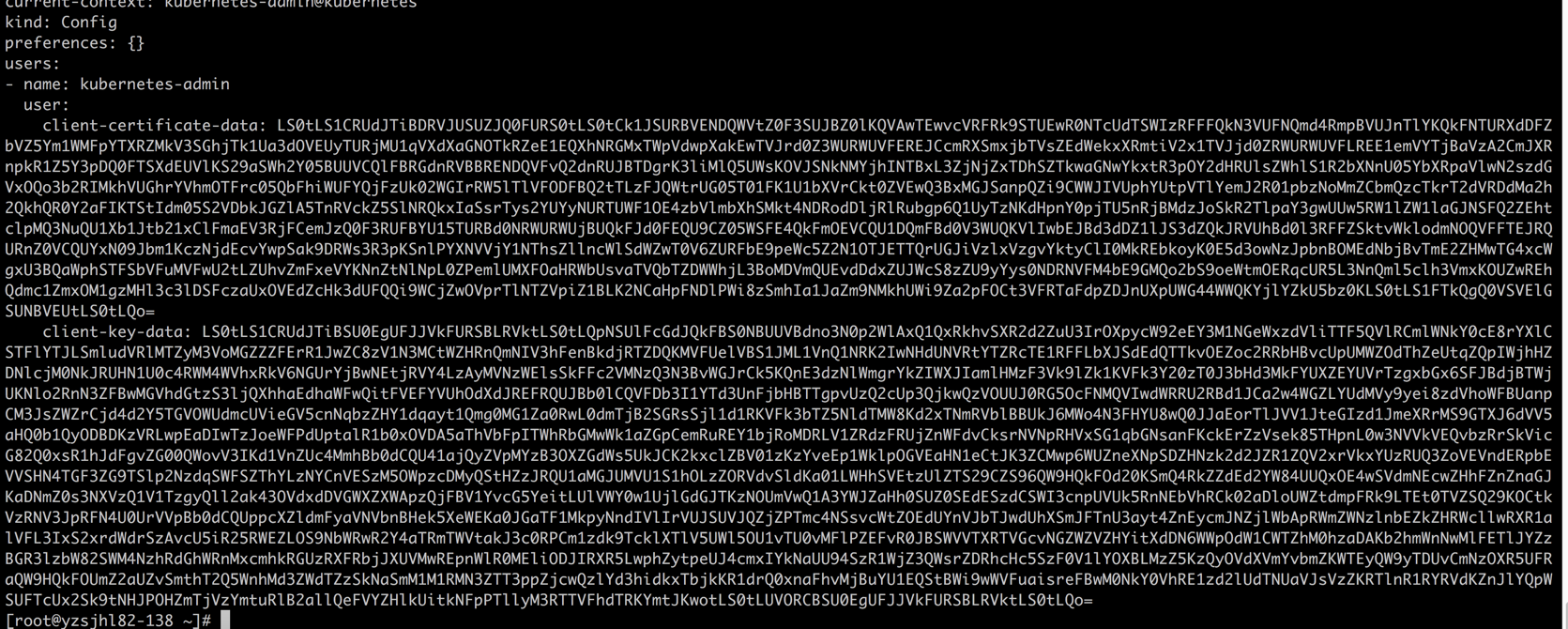
这里需要说明一下,config文件里面是使用base64编译过后的,所以我们填写的时候是需要使用base64解码

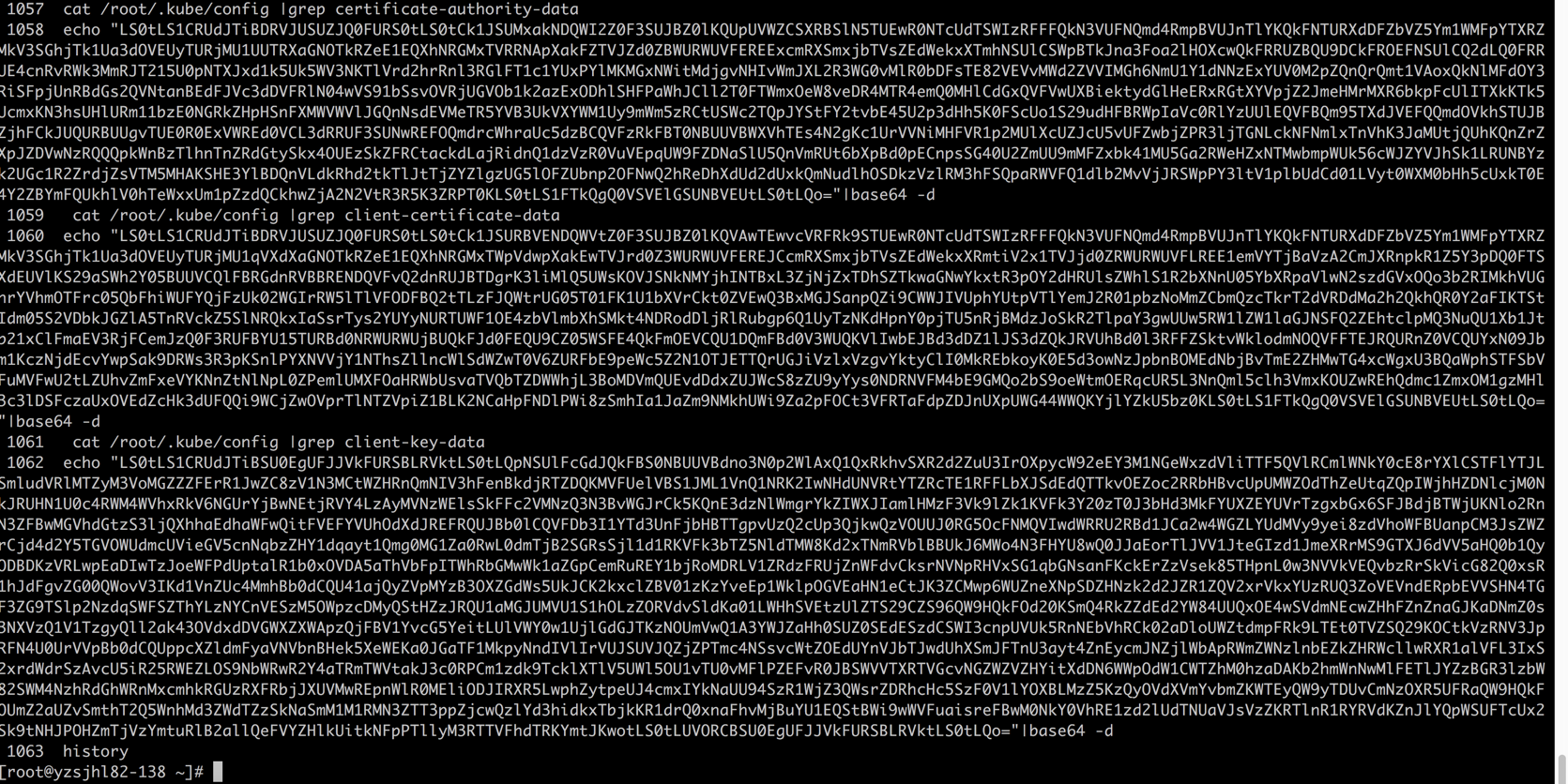
cat /root/.kube/config |grep certificate-authority-data echo "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMxakNDQWI2Z0F0......"|base64 -d
我的环境配置如下
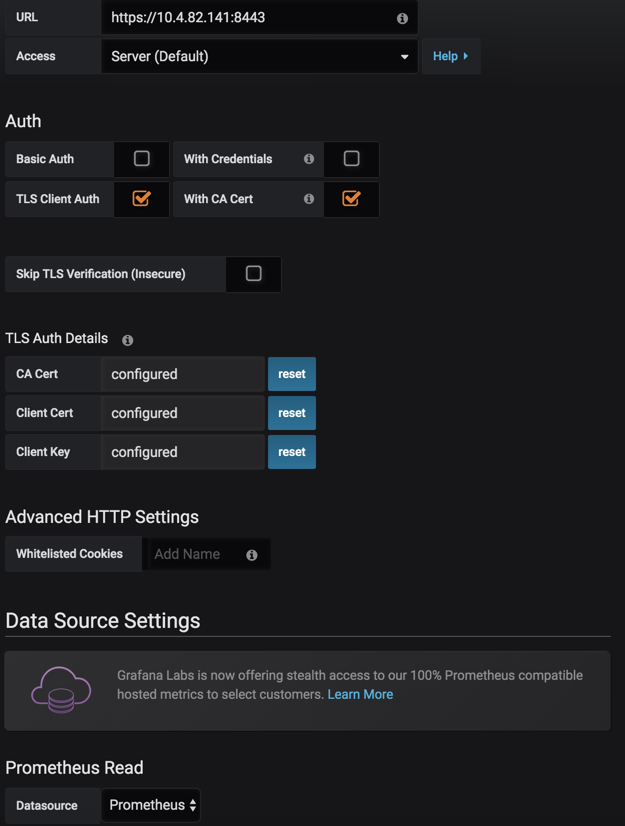
然后我们点击Save
如果没有提示证书错误,提示找不到这个元数据,那么请等一会
有报错会有红色的叹�号
解决不了可以到https://i4t.com/bubble进行提问,账号免注册直接qq登陆
Dashboard的时间需要修改改一下,改成UTC并且+10小时
最后效果图如下
效果图修改好之后,我们记得curl +s或者点击保存按钮


配置完成后点了保存,显示保存成功脸接成功,但是查看dashboard报错,查看pod日志如下
2020/07/15 09:14:16 http: proxy error: context canceled
2020/07/15 09:14:16 http: proxy error: context canceled
2020/07/15 09:14:16 http: proxy error: context canceled
2020/07/15 09:14:16 http: proxy error: context canceled
2020/07/15 09:14:16 http: proxy error: context canceled
t=2020-07-15T09:14:16+0000 lvl=info msg=”Request Completed” logger=context userId=1 orgId=1 uname=admin method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=172.16.180.34 time_ms=29956 size=0 referer=”http://172.16.180.34:30168/d/eGlOxK7Mk/k8s-cluster?var-datasource=prometheus-ops&var-cluster=ceshi&refresh=30s&orgId=1″
t=2020-07-15T09:14:16+0000 lvl=info msg=”Request Completed” logger=context userId=1 orgId=1 uname=admin method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=172.16.180.34 time_ms=29964 size=0 referer=”http://172.16.180.34:30168/d/eGlOxK7Mk/k8s-cluster?var-datasource=prometheus-ops&var-cluster=ceshi&refresh=30s&orgId=1″
t=2020-07-15T09:14:16+0000 lvl=info msg=”Request Completed” logger=context userId=1 orgId=1 uname=admin method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=172.16.180.34 time_ms=29969 size=0 referer=”http://172.16.180.34:30168/d/eGlOxK7Mk/k8s-cluster?var-datasource=prometheus-ops&var-cluster=ceshi&refresh=30s&orgId=1″
t=2020-07-15T09:14:16+0000 lvl=info msg=”Request Completed” logger=context userId=1 orgId=1 uname=admin method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=172.16.180.34 time_ms=29972 size=0 referer=”http://172.16.180.34:30168/d/eGlOxK7Mk/k8s-cluster?var-datasource=prometheus-ops&var-cluster=ceshi&refresh=30s&orgId=1″
t=2020-07-15T09:14:16+0000 lvl=info msg=”Request Completed” logger=context userId=1 orgId=1 uname=admin method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=172.16.180.34 time_ms=29986 size=0 referer=”http://172.16.180.34:30168/d/eGlOxK7Mk/k8s-cluster?var-datasource=prometheus-ops&var-cluster=ceshi&refresh=30s&orgId=1″
在K8s Deployment dashboard 页面,deployment变量获取不到值有没有遇到过的?把query换成pod是可以过滤出结果的
连接报“HTTP Error Bad Request”会是什么原因呢?
看一下日志吧