
文章目录
一、Ceph 集群服务维护
之前文章说了一下ceph的安装,安装其实比较简单,但是后续维护起来我们需要知道常用的维护命令
- 第一种,一次性重启所有服务
如果我们机器上osd、mon、rgw等服务都安装在一个节点,可以通过下面的命令直接管理所有服务
ceph target allowing to start/stop all ceph*@.service instances at once
[root@ceph-01 ~]# systemctl start ceph.target #将本节点所有的ceph相关的组件进行启动
#这个命令适用于我们当前ceph节点有多个ceph组件- 第二种,单个服务重启
上面我们说的是一下重启所有的服务,很多情况下我们只想重启osd或者mon,就可以通过下面的命令进行
[root@ceph-01 ~]# systemctl status ceph-osd.target
[root@ceph-01 ~]# systemctl status ceph-mon.target
[root@ceph-01 ~]# systemctl status ceph-mds.target- 第三种,我们osd或者mon可能在一台服务器上有多个服务
如果我们使用systemctl status ceph-osd.target重启osd,可能ceph这台服务器上多个osd都会被重启,可能我们只想重启其中一个节点的osd
[root@ceph-01 ~]# ls /usr/lib/systemd/system/|grep ceph #查看那几个单个服务的节点重启
ceph-crash.service
ceph-fuse@.service
ceph-fuse.target
ceph-mds@.service
ceph-mds.target
ceph-mgr@.service
ceph-mgr.target
ceph-mon@.service
ceph-mon.target
ceph-osd@.service
ceph-osd.target
ceph-radosgw@.service
ceph-radosgw.target
ceph.target
ceph-volume@.service
[root@ceph-01 ~]# ceph osd tree #重启osd前,查看osd对应的id
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17569 root default
-3 0.07809 host ceph-01
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000 #osd ID=3
-5 0.04880 host ceph-02
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host ceph-03
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-9 0 host ceph-04
#上面可以看到ceph节点有2个osd,我们如果想查看osd 3的状态,就可以通过下面的命令
[root@ceph-01 ~]# systemctl status ceph-osd@3二、Ceph 日志分析
在维护过程中,服务出现问题第一时间看服务状态以及对应服务的日志。
ceph服务默认日志路径在/var/log/ceph中
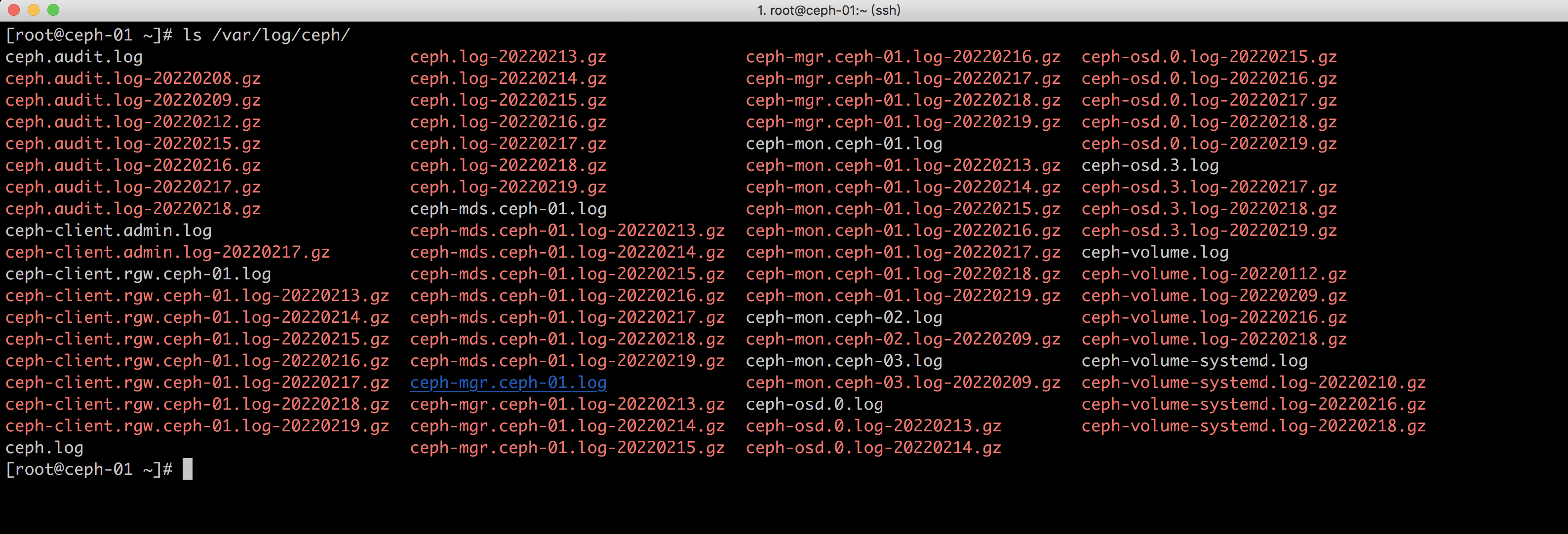
ceph日志格式为ceph-(osd|client|mds|mgr|osd).(节点ip or 节点名称).log
如果我们需要查看ceph-01节点的osd或者mon可以通过下面的命令查看
[root@ceph-01 ceph]# tail /var/log/ceph/ceph-mon.ceph-01.log
[root@ceph-01 ceph]# tail /var/log/ceph/ceph-osd.0.log #因为ceph-01上有2个osd节点,所以会有0和3,0和3代表osd 在集群中的id,通过ceph osd tree可以看到
[root@ceph-01 ceph]# tail /var/log/ceph/ceph-osd.3.log三、Ceph集群健康状态查看
登陆ceph服务器的第一件事我们就是要查看一下ceph集群的状态,一般没事不登录服务器。登陆服务器肯定是ceph集群出现故障,或者ceph服务器进行告警
常用的ceph查看集群的状态有ceph -s和ceph status,实际上这两个命令结果是相同的
[root@ceph-01 ceph]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 37h)
mgr: ceph-03(active, since 11d), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standby
osd: 4 osds: 4 up (since 2d), 4 in (since 2d)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 9 pools, 384 pgs
objects: 2.88k objects, 10 GiB
usage: 35 GiB used, 145 GiB / 180 GiB avail
pgs: 384 active+clean
[root@ceph-01 ceph]# ceph status
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 37h)
mgr: ceph-03(active, since 11d), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standby
osd: 4 osds: 4 up (since 2d), 4 in (since 2d)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 9 pools, 384 pgs
objects: 2.88k objects, 10 GiB
usage: 35 GiB used, 145 GiB / 180 GiB avail
pgs: 384 active+clean除了通过命令直接输出结果,我们还可以进入到ceph终端
实际上就是不在输入ceph命令,直接status
[root@ceph-01 ceph]# ceph
ceph> status
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 37h)
mgr: ceph-03(active, since 11d), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standby
osd: 4 osds: 4 up (since 2d), 4 in (since 2d)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 9 pools, 384 pgs
objects: 2.88k objects, 10 GiB
usage: 35 GiB used, 145 GiB / 180 GiB avail
pgs: 384 active+clean有的时候我们想动态查看ceph的一个集群状态,可以通过ceph -w命令来看一下
[root@ceph-01 ceph]# ceph -w
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 38h)
mgr: ceph-03(active, since 11d), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standby
osd: 4 osds: 4 up (since 2d), 4 in (since 2d)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 9 pools, 384 pgs
objects: 2.88k objects, 10 GiB
usage: 35 GiB used, 145 GiB / 180 GiB avail
pgs: 384 active+clean
...
#如果集群是HEALTH_OK的状态,没有发生变化,那么ceph -w是不会在输出日志的。 只有节点异常后,ceph -w是可以继续输出状态3.1 osd 资源查看
这里的状态查看和我们使用ceph -s 命令是一样的
[root@ceph-01 ceph]# ceph osd stat
4 osds: 4 up (since 2d), 4 in (since 2d); epoch: e370需要看osd详细的状态可以通过ceph osd dump出来
dump命令可以dump osd中很详细的信息
[root@ceph-01 ceph]# ceph osd dump查看ceph osd中所有节点的状态
包括节点信息,osd ID以及osd的状态和权重等
[root@ceph-01 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17569 root default
-3 0.07809 host ceph-01
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.04880 host ceph-02
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host ceph-03
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-9 0 host ceph-04除了在ceph -s中查看ceph集群磁盘的总使用率,还可以通过ceph df查看剩余空间以及每个pool的使用情况
[root@ceph-01 ceph]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 145 GiB 31 GiB 35 GiB 19.22
TOTAL 180 GiB 145 GiB 31 GiB 35 GiB 19.22
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
abcdocker 1 64 136 MiB 68 414 MiB 0.31 44 GiB
.rgw.root 2 32 1.2 KiB 4 768 KiB 0 44 GiB
default.rgw.control 3 32 0 B 8 0 B 0 44 GiB
default.rgw.meta 4 32 1.7 KiB 7 1.1 MiB 0 44 GiB
default.rgw.log 5 32 0 B 207 0 B 0 44 GiB
default.rgw.buckets.index 6 32 0 B 2 0 B 0 44 GiB
default.rgw.buckets.data 7 32 0 B 0 0 B 0 44 GiB
cephfs_data 8 64 10 GiB 2.56k 30 GiB 18.66 44 GiB
cephfs_metadata 9 64 615 KiB 23 3.4 MiB 0 44 GiBCKASS 硬盘类型ssd或hdd
SIZE 集群管理的存储容量。
AVAIL 集群中可用的可用空间量。
USED 用户数据消耗的原始存储量(不包括BlueStore的数据库)
RAW USED 用户数据、内部开销或保留容量消耗的原始存储量。
%RAW USED 使用的原始存储的百分比。将此数字与 和 结合使用,以确保您没有达到集群的容量。
对于Pool的信息注释
ID 池中节点的编号。
STORED 用户/Ceph 存储在池中的实际数据量。这类似于早期版本的 Ceph 中的 USED 列,但计算(对于 BlueStore!)更精确(间隙得到适当处理)。
(DATA) 用于 RBD(RADOS 块设备)、CephFS 文件数据和 RGW(RADOS 网关)对象数据。
(OMAP)键值对。主要由 CephFS 和 RGW(RADOS 网关)用于元数据存储。
OBJECTS每个池中存储的对象的名义数量。“名义”在上文“池”下的段落中定义。
USED为所有 OSD 上的池分配的空间。这包括复制、分配粒度和纠删码开销。压缩节省和对象内容差距也被考虑在内。BlueStore 的数据库不包括在这个数量中。
(DATA) RBD(RADOS 块设备)、CephFS 文件数据和 RGW(RADOS 网关)对象数据的对象使用情况。
(OMAP) 对象键值对。主要由 CephFS 和 RGW(RADOS 网关)用于元数据存储。
%USED 每个池使用的存储空间的名义百分比。
MAX AVAIL估计可以写入此池的名义数据量。
QUOTA OBJECTS 配额对象的数量。
QUOTA BYTES 配额对象中的字节数。
DIRTY 缓存池中已写入缓存池但尚未刷新到基本池的对象数。此字段仅在使用缓存分层时可用。
USED COMPR 为压缩数据分配的空间量(即,这包括压缩数据加上所有分配、复制和纠删码开销)。
UNDER COMPR 通过压缩传递的数据量(所有副本的总和)并且足以以压缩形式存储。
有一种情况我们需要看osd所有节点的使用率可以使用osd df,包含使用率节点,更为详细的命令
[root@ceph-01 ceph]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 7.8 GiB 6.8 GiB 56 KiB 1024 MiB 42 GiB 15.59 0.81 234 up
3 hdd 0.02930 1.00000 30 GiB 4.4 GiB 3.4 GiB 20 KiB 1024 MiB 26 GiB 14.78 0.77 150 up
1 hdd 0.04880 1.00000 50 GiB 11 GiB 10 GiB 39 KiB 1024 MiB 39 GiB 22.37 1.16 384 up
2 hdd 0.04880 1.00000 50 GiB 11 GiB 10 GiB 51 KiB 1024 MiB 39 GiB 22.37 1.16 384 up
TOTAL 180 GiB 35 GiB 31 GiB 168 KiB 4.0 GiB 145 GiB 19.22
MIN/MAX VAR: 0.77/1.16 STDDEV: 3.63同样ceph osd status也是可以看到集群空间使用率
[root@ceph-01 ceph]# ceph osd status
+----+---------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+---------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | ceph-01 | 7981M | 42.2G | 0 | 0 | 0 | 0 | exists,up |
| 1 | ceph-02 | 11.1G | 38.8G | 0 | 0 | 0 | 0 | exists,up |
| 2 | ceph-03 | 11.1G | 38.8G | 0 | 0 | 0 | 0 | exists,up |
| 3 | ceph-01 | 4539M | 25.5G | 0 | 0 | 0 | 0 | exists,up |
+----+---------+-------+-------+--------+---------+--------+---------+-----------+3.2 mon 资源查看
通过mon stat 可以详细的查看集群mon的节点地址,以及对应的id
[root@ceph-01 ceph]# ceph mon stat
e3: 3 mons at {ceph-01=[v2:192.168.31.20:3300/0,v1:192.168.31.20:6789/0],ceph-02=[v2:192.168.31.21:3300/0,v1:192.168.31.21:6789/0],ceph-03=[v2:192.168.31.80:3300/0,v1:192.168.31.80:6789/0]}, election epoch 574, leader 0 ceph-01, quorum 0,1,2 ceph-01,ceph-02,ceph-03
#在信息可以看到 leader ceph-01为leader
# 节点ID为0 ,1,2
#集群节点有ceph-01,ceph-02,ceph-03通过mon dump可以看到更详细的节点信息,包含节点添加时间等
[root@ceph-01 ceph]# ceph mon dump
epoch 3
fsid c8ae7537-8693-40df-8943-733f82049642
last_changed 2022-01-10 22:52:57.150281 #上次修改时间
created 2022-01-10 22:45:09.178972 #创建时间
min_mon_release 14 (nautilus)
0: [v2:192.168.31.20:3300/0,v1:192.168.31.20:6789/0] mon.ceph-01 #节点信息
1: [v2:192.168.31.21:3300/0,v1:192.168.31.21:6789/0] mon.ceph-02
2: [v2:192.168.31.80:3300/0,v1:192.168.31.80:6789/0] mon.ceph-03
dumped monmap epoch 3 #节点数量quorum_status可以看到集群节点选举情况,节点信息等
[root@ceph-01 ceph]# ceph quorum_status
{"election_epoch":574,"quorum":[0,1,2],"quorum_names":["ceph-01","ceph-02","ceph-03"],"quorum_leader_name":"ceph-01","quorum_age":138753,"monmap":{"epoch":3,"fsid":"c8ae7537-8693-40df-8943-733f82049642","modified":"2022-01-10 22:52:57.150281","created":"2022-01-10 22:45:09.178972","min_mon_release":14,"min_mon_release_name":"nautilus","features":{"persistent":["kraken","luminous","mimic","osdmap-prune","nautilus"],"optional":[]},"mons":[{"rank":0,"name":"ceph-01","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.31.20:3300","nonce":0},{"type":"v1","addr":"192.168.31.20:6789","nonce":0}]},"addr":"192.168.31.20:6789/0","public_addr":"192.168.31.20:6789/0"},{"rank":1,"name":"ceph-02","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.31.21:3300","nonce":0},{"type":"v1","addr":"192.168.31.21:6789","nonce":0}]},"addr":"192.168.31.21:6789/0","public_addr":"192.168.31.21:6789/0"},{"rank":2,"name":"ceph-03","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.31.80:3300","nonce":0},{"type":"v1","addr":"192.168.31.80:6789","nonce":0}]},"addr":"192.168.31.80:6789/0","public_addr":"192.168.31.80:6789/0"}]}}3.3 mds 资源查看
跟osd和mon相同,mds同样支持上述的几个命令
[root@ceph-01 ceph]# ceph mds stat
cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standby
#ceph-03节点为工作节点,ceph-01 ceph-02为standby状态ceph fs dump同样可以获取到mds内部状态
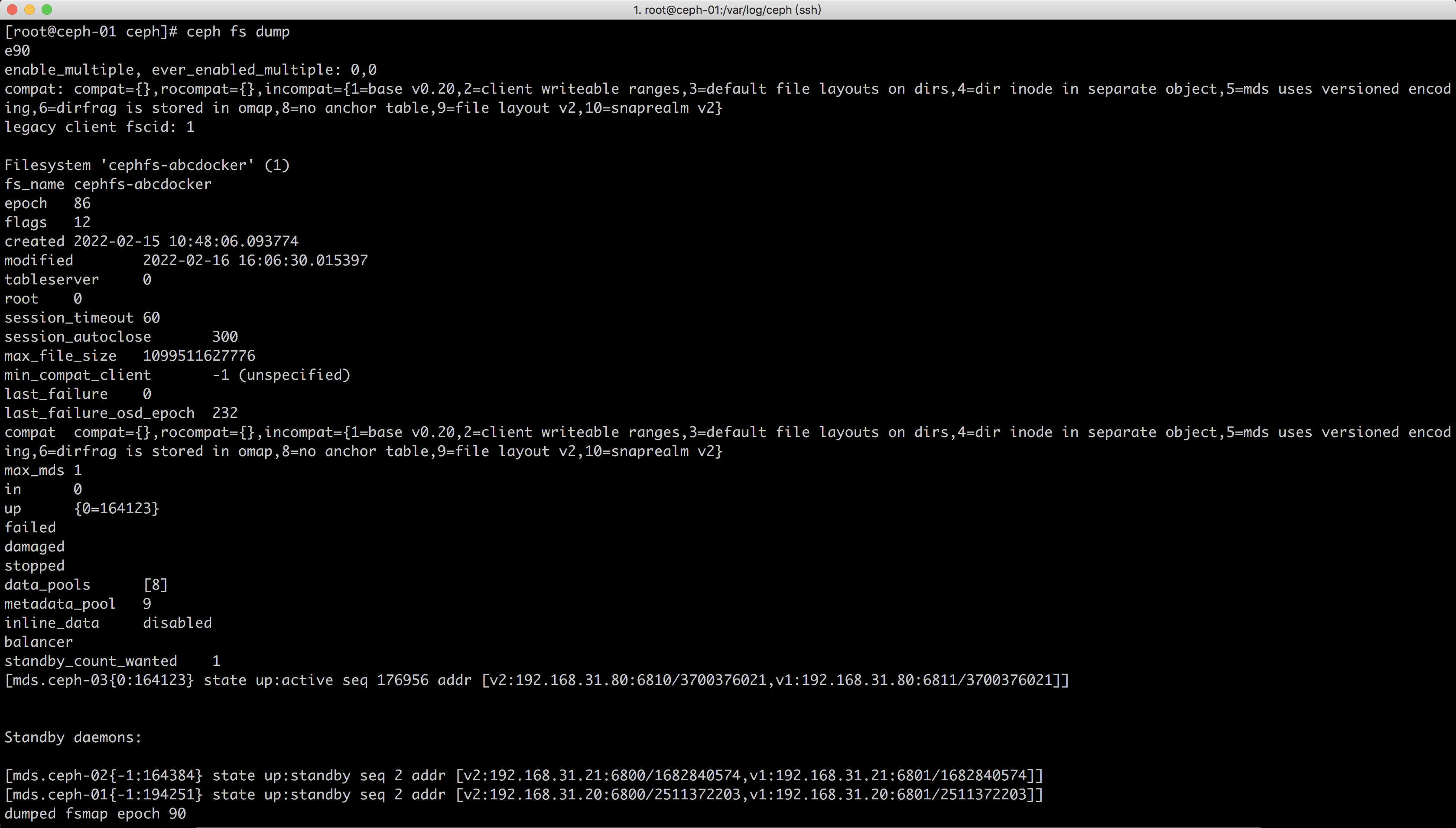
3.4 ADMIN SOCKET
admin socket可以看到ceph节点中某个服务的守护进程配置信息
#例如我们要查看osd的配置文件
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-osd.0.asok config show
#mon配置文件
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok config show通过下面的命令可以看到我们可以执行的命令
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-osd.0.asok help例如查看mon选举情况
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok help|grep status
"mon_status": "show current monitor status",
"quorum_status": "show current quorum status",
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok quorum_status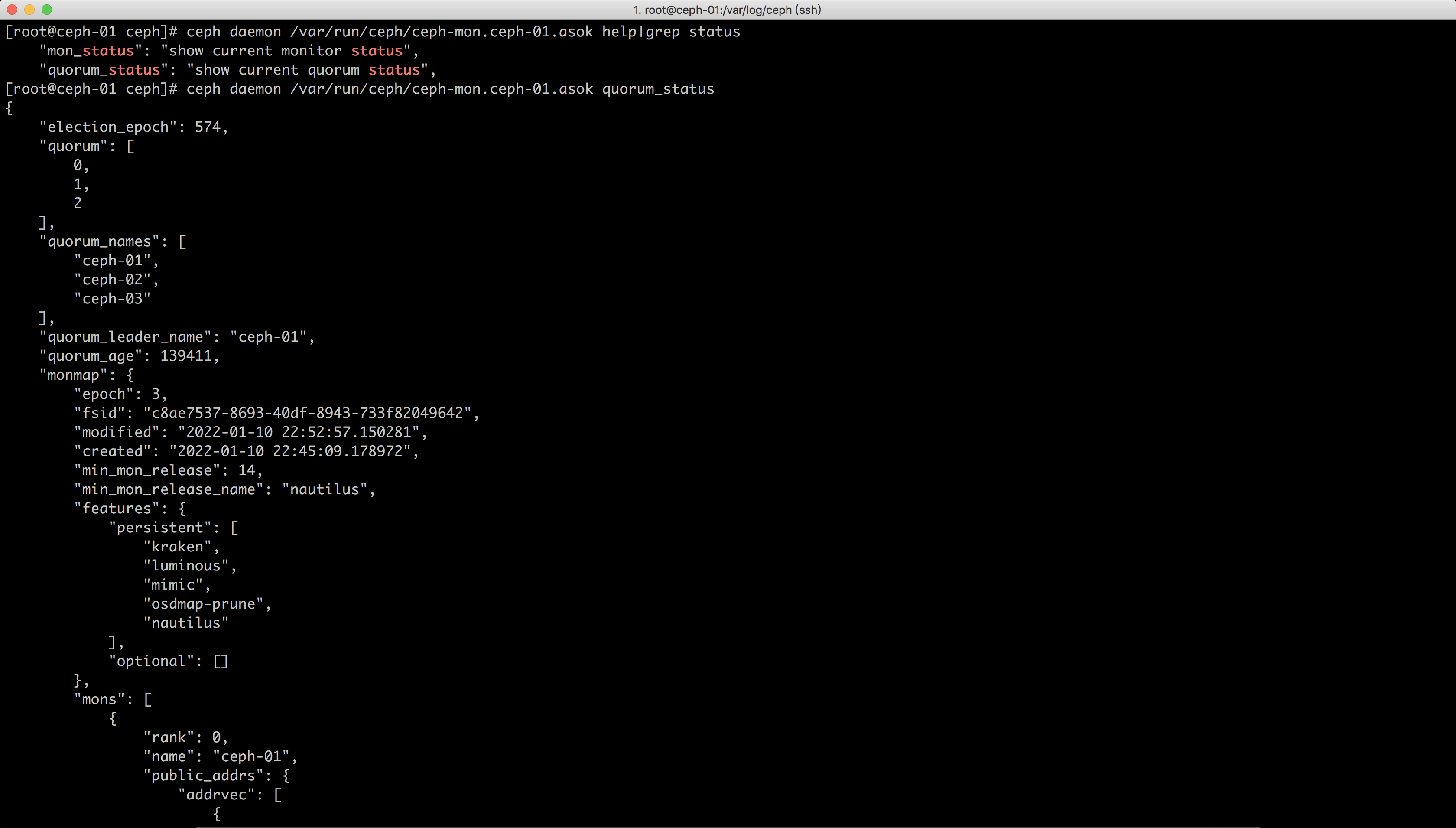
ceph集群的配置参数除了在/etc/ceph/ceph.conf中修改,还可以通过SOCKET直接设置
#例如修改时钟参数
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok help|grep config
#查看config可以直接的命令
"config diff": "dump diff of current config and default config",
"config diff get": "dump diff get <field>: dump diff of current and default config setting <field>",
"config get": "config get <field>: get the config value",
"config help": "get config setting schema and descriptions",
"config set": "config set <field> <val> [<val> ...]: set a config variable",
"config show": "dump current config settings",
"config unset": "config unset <field>: unset a config variable",
#通过config set替换对应的值
[root@ceph-01 ceph]# ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok config set 变量名 值四、Ceph Pool 资源池管理
查看pool
[root@ceph-01 ~]# ceph osd pool ls && ceph osd lspools
abcdocker
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
default.rgw.buckets.index
default.rgw.buckets.data
cephfs_data
cephfs_metadata设置pool规则,pg大小、pgp大小,pool配额等
[root@ceph-01 ~]# ceph osd pool get pool
Invalid command: missing required parameter var(size|min_size|pg_num|pgp_num|crush_rule|hashpspool|nodelete|nopgchange|nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|use_gmt_hitset|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|all|min_write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority|compression_mode|compression_algorithm|compression_required_ratio|compression_max_blob_size|compression_min_blob_size|csum_type|csum_min_block|csum_max_block|allow_ec_overwrites|fingerprint_algorithm|pg_autoscale_mode|pg_autoscale_bias|pg_num_min|target_size_bytes|target_size_ratio)
osd pool get <poolname> size|min_size|pg_num|pgp_num|crush_rule|hashpspool|nodelete|nopgchange|nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|use_gmt_hitset|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|all|min_write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority|compression_mode|compression_algorithm|compression_required_ratio|compression_max_blob_size|compression_min_blob_size|csum_type|csum_min_block|csum_max_block|allow_ec_overwrites|fingerprint_algorithm|pg_autoscale_mode|pg_autoscale_bias|pg_num_min|target_size_bytes|target_size_ratio : get pool parameter <var>
Error EINVAL: invalid command创建pool
#格式如下
ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] [replicated] \
[crush-rule-name] [expected-num-objects]
ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] erasure \
[erasure-code-profile] [crush-rule-name] [expected_num_objects] [--autoscale-mode=<on,off,warn>]
#创建一个名称为test_i4t
#pg大小为16
#pgp大小为16
[root@ceph-01 ~]# ceph osd pool create test_i4t 16 16
pool 'test_i4t' created
[root@ceph-01 ~]# ceph osd lspools
1 abcdocker
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_data
9 cephfs_metadata
10 test_i4t查看副本数量
[root@ceph-01 ~]# ceph osd pool get test_i4t size
size: 3
#这里可以看到pool副本数量为3将size改成pg_num和pgp_num可以看到ceph中pg和pgp的数量,我们创建的时候定义的
[root@ceph-01 ~]# ceph osd pool get test_i4t pg_num
pg_num: 16
[root@ceph-01 ~]#
[root@ceph-01 ~]# ceph osd pool get test_i4t pgp_num
pgp_num: 16设置pool
#刚刚我们获取到pool的一些参数变量,我们可以来进行修改这些
#比如讲副本数由3个修改为5个
[root@ceph-01 ~]# ceph osd pool set test_i4t size 5
set pool 10 size to 5
[root@ceph-01 ~]# ceph osd pool get test_i4t size
size: 5将Pool关联到Application上
pool创建完成后,需要初始化。将相关的pool关联到application上。类似一个别名
CephFS 使用应用程序名称cephfs,RBD 使用应用程序名称rbd,RGW 使用应用程序名称rgw。
[root@ceph-01 ~]# ceph osd pool application get test_i4t
{}
[root@ceph-01 ~]# ceph osd pool application enable test_i4t rdb #支持的类型为rdb、rgw、以及cephfs
enabled application 'rdb' on pool 'test_i4t'
[root@ceph-01 ~]# ceph osd pool application get test_i4t
{
"rdb": {}
}我们还可以给pool限制配额,指pool可以允许使用多少个ojbect或者是允许使用多少空间
[root@ceph-01 ~]# ceph osd pool set-quota test_i4t max_objects 100
set-quota max_objects = 100 for pool test_i4t
[root@ceph-01 ~]# ceph osd pool get-quota test_i4t
quotas for pool 'test_i4t':
max objects: 100 objects
max bytes : N/A
#通过get-quota和set-quota变量来查看我们修改的变量pool存储空间占用率查看
#除了使用ceph df查看,还可以使用rados df查看ceph pool空间使用率的情况
[root@ceph-01 ~]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 145 GiB 31 GiB 35 GiB 19.22
TOTAL 180 GiB 145 GiB 31 GiB 35 GiB 19.22
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
abcdocker 1 64 136 MiB 68 414 MiB 0.31 44 GiB
.rgw.root 2 32 1.2 KiB 4 768 KiB 0 44 GiB
default.rgw.control 3 32 0 B 8 0 B 0 44 GiB
default.rgw.meta 4 32 1.7 KiB 7 1.1 MiB 0 44 GiB
default.rgw.log 5 32 0 B 207 0 B 0 44 GiB
default.rgw.buckets.index 6 32 0 B 2 0 B 0 44 GiB
default.rgw.buckets.data 7 32 0 B 0 0 B 0 44 GiB
cephfs_data 8 64 10 GiB 2.56k 30 GiB 18.66 44 GiB
cephfs_metadata 9 64 615 KiB 23 3.4 MiB 0 44 GiB
test_i4t 10 16 0 B 0 0 B 0 26 GiB
[root@ceph-01 ~]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 77 77 KiB 4 4 KiB 0 B 0 B
abcdocker 414 MiB 68 0 204 0 0 0 1269 6.3 MiB 178 145 MiB 0 B 0 B
cephfs_data 30 GiB 2561 0 7683 0 0 0 0 0 B 2665 10 GiB 0 B 0 B
cephfs_metadata 3.4 MiB 23 0 69 0 0 0 15 27 KiB 483 847 KiB 0 B 0 B
default.rgw.buckets.data 0 B 0 0 0 0 0 0 7122 8.7 MiB 23272 31 MiB 0 B 0 B
default.rgw.buckets.index 0 B 2 0 6 0 0 0 21540 23 MiB 10744 5.2 MiB 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 2706443 2.6 GiB 1803450 2 KiB 0 B 0 B
default.rgw.meta 1.1 MiB 7 0 21 0 0 0 105 97 KiB 42 18 KiB 0 B 0 B
test_i4t 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
total_objects 2880
total_used 35 GiB
total_avail 145 GiB
total_space 180 GiBpool使用命令可以参考https://docs.ceph.com/en/latest/rados/operations/pools/
删除pool
[root@ceph-01 ~]# ceph osd lspools
1 abcdocker
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_data
9 cephfs_metadata
10 test_i4t
[root@ceph-01 ~]#
[root@ceph-01 ~]# ceph osd pool rm test_i4t test_i4t
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool test_i4t. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[root@ceph-01 ~]#
[root@ceph-01 ~]# ceph osd pool rm test_i4t test_i4t --yes-i-really-really-mean-it
pool 'test_i4t' removed
#如果无法删除pool,需要在ceph.conf中添加下面的配置
mon allow pool delete = trueCeph PG数据调整
下面的命令可以动态调整pg和pgp的大小
ceph osd pool set {pool-name} pg_num {pg_num}
ceph osd pool set {pool-name} pgp_num {pgp_num}
同步配置文件
同步配置文件可以使用下面的命令
[root@ceph-01 ~]# cd ceph-deploy
[root@ceph-01 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-01 ceph-02 ceph-03
#ceph添加节点名称
#ceph-deploy命令需要到ceph-deploy目录中进行执行
