
文章目录
一、Ceph原理
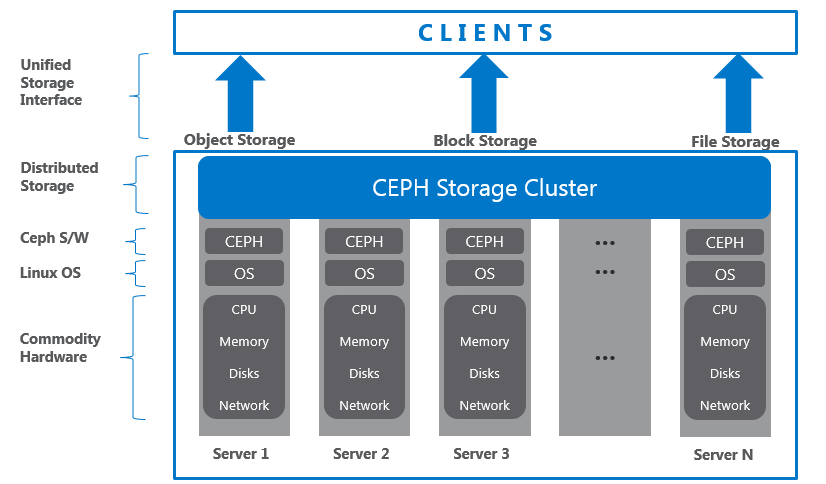
二、环境准备
文档没有标注哪台节点执行,默认情况下就是所有节点执行的命令!
集群信息
| IP | 作用 |
|---|---|
| 192.168.31.20 | ceph01、NTP Server |
| 192.168.31.21 | ceph02 |
| 192.168.31.22 | ceph03 |
主机名需要和host设置相同,必须设置否则无法初始化,后续也有问题!
首先我们需要添加NTP服务器
#NTP SERVER (ntp server 与阿里与ntp时间服务器进行同步)
#首先我们配置ntp server,我这里在ceph01上面配置
yum install -y ntp
[root@ceph-01 ~]# systemctl start ntpd
[root@ceph-01 ~]# systemctl enable ntpd
[root@ceph-01 ~]# timedatectl set-timezone Asia/Shanghai
#将当前的 UTC 时间写入硬件时钟
[root@ceph-01 ~]# timedatectl set-local-rtc 0
#重启依赖于系统时间的服务
[root@ceph-01 ~]# systemctl restart rsyslog
[root@ceph-01 ~]# systemctl restart crond
#这样我们的ntp server自动连接到外网,进行同步 (时间同步完成在IP前面会有一个*号)
[root@ceph-01 ~]# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
120.25.115.20 10.137.53.7 2 u 8 64 17 40.203 -24.837 0.253
*203.107.6.88 100.107.25.114 2 u 8 64 17 14.998 -22.611 0.186
#NTP Agent (ntp agent同步ntp server时间)
ntp agent需要修改ntp server的地址
[root@ceph-02 ~]# vim /etc/ntp.conf
server 192.168.31.20 iburst
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#注释默认的server,添加一条我们ntp server的地址
[root@ceph-02 ~]# systemctl restart ntpd
[root@ceph-02 ~]# systemctl enable ntpd
#等待几分钟出现*号代表同步完成
[root@ceph-02 ~]# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
*192.168.31.20 120.25.115.20 3 u 13 64 1 0.125 -19.095 0.095
#ceph-03节点操作相同在ntp_agent节点添加定时同步任务
$ crontab -e
*/5 * * * * /usr/sbin/ntpdate 192.168.31.20ntp时间服务器设置完成后在所有节点修改时区以及写入硬件
timedatectl set-timezone Asia/Shanghai
#将当前的 UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
#重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond校对时间
[root@ceph-01 ~]# date
Tue Sep 8 17:35:43 CST 2020
[root@ceph-02 ~]# date
Tue Sep 8 17:35:46 CST 2020
[root@ceph-03 ~]# date
Tue Sep 8 17:35:47 CST 2020如果时间不同步,osd创建完成后会有error提示
添加host (所有节点)
cat >>/etc/hosts <<EOF
192.168.31.20 ceph-01
192.168.31.21 ceph-02
192.168.31.22 ceph-03
EOFceph01 设置免密
ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa
for i in ceph-01 ceph-02 ceph-03 ;do
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$i
expect {
"*yes/no*" {send "yesr"; exp_continue}
"*password*" {send "123456r"; exp_continue}
"*Password*" {send "123456r";}
} "
done
#123456为密码所有节点关闭防火墙selinux
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/configceph yum源配置
#配置centos、epeo、ceph源
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
wget -O /etc/yum.repos.d/ceph.repo http://down.i4t.com/ceph/ceph.repo
yum clean all
yum makecache所有工作完成后建议所有节点重启一下服务器
rebootceph-01部署节点安装依赖包以及ceph部署工具ceph-deploy
[root@ceph-01 ~]# yum install -y python-setuptools
[root@ceph-01 ~]# yum install -y ceph-deploy执行ceph-deploy可以看到ceph的版本
[root@ceph-01 ~]# ceph-deploy
usage: ceph-deploy [-h] [-v | -q] [--version] [--username USERNAME]
[--overwrite-conf] [--ceph-conf CEPH_CONF]
COMMAND ...
Easy Ceph deployment
-^-
/
|O o| ceph-deploy v2.0.1
).-.(
'/|||`
| '|` |
'|`三、ceph部署
下面先运行单节点的monitor
3.1 部署monitor
接下来为ceph创建一个配置目录,后面操作需要在这个目录下进行
mkdir /root/ceph-deploy
cd /root/ceph-deploy创建monitor
[root@ceph-01 ceph-deploy]# ceph-deploy new ceph-01 --public-network 192.168.31.0/24
#ceph-01代表部署monitor节点
#参数设置
--cluster-network 集群对外的网络
--public-network 集群内通信的网络
#--public-network建议添加,否则后面添加monitor节点会提示错误执行完毕后我们可以看到在/root/ceph-deploy目录会有为我们生成的一些文件
[root@ceph-01 ceph-deploy]# ls /root/ceph-deploy
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
ceph配置文件 ceph日志文件 keyring主要做身份验证
#我们可以根据自身需要修改ceph.conf文件,比如上面创建集群中添加的网络,在这里也可以添加添加ceph时间配置
#添加允许ceph时间偏移
echo "mon clock drift allowed = 2" >>/root/ceph-deploy/ceph.conf
echo "mon clock drift warn backoff = 30" >>/root/ceph-deploy/ceph.conf在所有节点安装ceph相关软件包
yum install -y ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds
#当然如果你不在乎网络问题,也可以使用官方推荐的安装方式,下面的方式会重新给我们配置yum源,这里不太推荐
ceph-deploy install ceph-01 ceph-02 ceph-03接下来我们需要初始化monitor
[root@ceph-01 ~]# cd /root/ceph-deploy
[root@ceph-01 ceph-deploy]# ceph-deploy mon create-initial
#需要进入到我们之前创建的ceph目录中接下来我们在/root/ceph-deploy下面可以看到刚刚生成的一些文件
[root@ceph-01 ceph-deploy]# ll
total 44
-rw-------. 1 root root 113 Sep 9 11:51 ceph.bootstrap-mds.keyring
-rw-------. 1 root root 113 Sep 9 11:51 ceph.bootstrap-mgr.keyring
-rw-------. 1 root root 113 Sep 9 11:51 ceph.bootstrap-osd.keyring
-rw-------. 1 root root 113 Sep 9 11:51 ceph.bootstrap-rgw.keyring
-rw-------. 1 root root 151 Sep 9 11:51 ceph.client.admin.keyring
-rw-r--r--. 1 root root 196 Sep 9 02:23 ceph.conf
-rw-r--r--. 1 root root 15628 Sep 9 11:51 ceph-deploy-ceph.log
-rw-------. 1 root root 73 Sep 9 02:23 ceph.mon.keyring
#ceph.bootstrap-*为我们初始化的秘钥文件,包括osd、mds、mgr将我们刚刚生成的文件拷贝到所有的节点上 (拷贝完成后就可以使用ceph -s参数)
[root@ceph-01 ceph-deploy]# ceph-deploy admin ceph-01 ceph-02 ceph-03
#把配置文件和admin密钥分发到各个节点禁用不安全模式
ceph config set mon auth_allow_insecure_global_id_reclaim false接下来我们执行ceph -s就可以看到已经初始化完毕
[root@ceph-01 ceph-deploy]# ceph -s
cluster:
id: f0060344-e237-426f-87f3-9e1fac373fcb
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-01 (age 6m) #这里是包含一个monitor
mgr: no daemons active #我们还没有创建mgr
osd: 0 osds: 0 up, 0 in #当然osd也没有的
data: #资源池我们还没有添加
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
#我们可以看到cluster.health后面的状态为OK创建 manager daemon (主要用于监控)
#这里我们只是将ceph-01作为manager daemon节点
[root@ceph-01 ceph-deploy]# ceph-deploy mgr create ceph-01接下来我们在执行ceph -s就会看到有一个刚添加的好的mgr节点
[root@ceph-01 ceph-deploy]# ceph -s
cluster:
id: f0060344-e237-426f-87f3-9e1fac373fcb
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-01 (age 10m)
mgr: ceph-01(active, since 32s) <<添加完毕后,mgr在ceph-01节点上,节点状态为active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 3.2 部署OSD
OSD负责相应客户端请求返回具体数据的进程,一个Ceph集群一般都有很多个OSD
OSD实际上就是存储我们数据的地方,所以我们的服务器需要添加一块硬盘作为数据存储,我这里3台节点都添加50G的数据,一共150G作为演示。这里我使用ESXI进行演示,与VMware操作相同。如果是物理服务器添加硬盘即可
点击编辑

添加一个50G的数据
添加完毕后我们开机
接下来我们在每台节点查看磁盘信息
因为我这里一共就只有2个硬盘,所以命名全部都是sdb (具体命名请根据实际的情况选择)
#ceph-01
[root@ceph-01 ceph-deploy]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 2M 0 part
├─sda2 8:2 0 200M 0 part /boot
└─sda3 8:3 0 49.8G 0 part /
sdb 8:16 0 50G 0 disk #sdb就是我们添加了一个50G的硬盘
sr0 11:0 1 1024M 0 rom
#ceph-02
[root@ceph-02 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 2M 0 part
├─sda2 8:2 0 200M 0 part /boot
└─sda3 8:3 0 49.8G 0 part /
sdb 8:16 0 50G 0 disk
sr0 11:0 1 1024M 0 rom
#ceph-03
[root@ceph-03 yum.repos.d]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 2M 0 part
├─sda2 8:2 0 200M 0 part /boot
└─sda3 8:3 0 49.8G 0 part /
sdb 8:16 0 50G 0 disk
sr0 11:0 1 1024M 0 rom接下来我们来创建osd
#这里添加三台osd集群
[root@ceph-01 ceph-deploy]# cd /root/ceph-deploy/
[root@ceph-01 ceph-deploy]# ceph-deploy osd create ceph-01 --data /dev/sdb
[root@ceph-01 ceph-deploy]# ceph-deploy osd create ceph-02 --data /dev/sdb
[root@ceph-01 ceph-deploy]# ceph-deploy osd create ceph-03 --data /dev/sdb接下来我们在查看ceph osd就可以看到有3台osd节点
[root@ceph-01 ceph-deploy]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-01 (age 5m)
mgr: ceph-01(active, since 3m)
osd: 3 osds: 3 up (since 82s), 3 in (since 82s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 147 GiB / 150 GiB avail
pgs: 温馨提示: 只有health状态为OK,证明集群同步正常
同样查看ceph osd的状态命令也有很多
[root@ceph-01 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.14639 root default
-3 0.04880 host ceph-01
0 hdd 0.04880 osd.0 up 1.00000 1.00000
-5 0.04880 host ceph-02
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host ceph-03
2 hdd 0.04880 osd.2 up 1.00000 1.00000 到这里我们就把ceph完毕3个osd。并且数据总大小为150G
如果期间我们有需要修改cpeh.conf的操作,只需要在ceph-01上修改,使用下面的命令同步到其他节点上
[root@ceph-01 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-01 ceph-02 ceph-03四、集群部署
4.1 部署monitor
接下来我们部署一个monitor高可用
扩展monitor
monitor负责保存OSD的元数据,所以monitor当然也需要高可用。 这里的monitor推荐使用奇数节点进行部署,我这里以3台节点部署

当我们添加上3个monitor节点后,monitor会自动进行选举,自动进行高可用
添加monitor
[root@ceph-01 ceph-deploy]# cd /root/ceph-deploy
[root@ceph-01 ceph-deploy]# ceph-deploy mon add ceph-02 --address 192.168.31.21
[root@ceph-01 ceph-deploy]# ceph-deploy mon add ceph-03 --address 192.168.31.22
#没有提示红色的error,证明monitor添加成功这个时候我们可以看到monitor节点已经添加成功
[root@ceph-01 ceph-deploy]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 1.51402s) #已经将monitor节点信息显示出来
mgr: ceph-01(active, since 5m)
osd: 3 osds: 3 up (since 3m), 3 in (since 3m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 147 GiB / 150 GiB avail
pgs:
我们还可以使用ceph自带的命令,查看monitor选举情况,以及集群的健康状态
[root@ceph-01 ~]# ceph quorum_status --format json-pretty
{
"election_epoch": 12,
"quorum": [
0,
1,
2
],
"quorum_names": [
"ceph-01", #集群节点信息
"ceph-02",
"ceph-03"
],
"quorum_leader_name": "ceph-01", #当前leader节点
"quorum_age": 151,
"monmap": {
"epoch": 3, #monitor节点数量
"fsid": "f0060344-e237-426f-87f3-9e1fac373fcb",
"modified": "2020-09-09 12:18:08.869325",
"created": "2020-09-09 11:51:11.201509",
"min_mon_release": 14,
"min_mon_release_name": "nautilus",
"features": {
"persistent": [
"kraken",
"luminous",
"mimic",
"osdmap-prune",
"nautilus"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "ceph-01",
"public_addrs": {
"addrvec": [
{
"type": "v2", #下面就可以看到我们每一个monitor的节点信息
"addr": "192.168.31.20:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.31.20:6789",
"nonce": 0
}
]
},
"addr": "10.4.81.120:6789/0",
"public_addr": "192.168.31.20:6789/0"
},
{
"rank": 1,
"name": "ceph-02",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.31.21:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.31.21:6789",
"nonce": 0
}
]
},
"addr": "192.168.31.21:6789/0",
"public_addr": "192.168.31.21:6789/0"
},
{
"rank": 2,
"name": "ceph-03",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.31.22:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.31.22:6789",
"nonce": 0
}
]
},
"addr": "192.168.31.22:6789/0",
"public_addr": "192.168.31.22:6789/0"
}
]
}
}同样查看monitor还可以通过下面的命令,直接查看monitor的map
e3: 3 mons at {ceph-01=[v2:192.168.31.20:3300/0,v1:192.168.31.20:6789/0],ceph-02=[v2:192.168.31.21:3300/0,v1:192.168.31.21:6789/0],ceph-03=[v2:192.168.31.80:3300/0,v1:192.168.31.80:6789/0]}, election epoch 12, leader 0 ceph-01, quorum 0,1,2 ceph-01,ceph-02,ceph-03还可以使用dump参数查看关于monitor更细的信息
[root@ceph-01 ~]# ceph mon dump
dumped monmap epoch 3
epoch 3
fsid f0060344-e237-426f-87f3-9e1fac373fcb
last_changed 2020-09-09 12:18:08.869325
created 2020-09-09 11:51:11.201509
min_mon_release 14 (nautilus)
0: [v2:10.4.81.120:3300/0,v1:10.4.81.120:6789/0] mon.ceph-01
1: [v2:10.4.81.121:3300/0,v1:10.4.81.121:6789/0] mon.ceph-02
2: [v2:10.4.81.122:3300/0,v1:10.4.81.122:6789/0] mon.ceph-03
#更多关于monitor的信息可以使用ceph mon -h查看到4.3 部署manager daemon
扩展manager daemon
Ceph-MGR目前的主要功能是把集群的一些指标暴露给外界使用
mgr集群只有一个节点为active状态,其它的节点都为standby。只有当主节点出现故障后,standby节点才会去接管,并且状态变更为active
这里扩展mgr的方法与monitor方法类似
[root@ceph-01 ~]# cd /root/ceph-deploy
[root@ceph-01 ceph-deploy]# ceph-deploy mgr create ceph-02 ceph-03
#create 后面为ceph节点的名称我们查看一下ceph状态
[root@ceph-01 ceph-deploy]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 2m)
mgr: ceph-01(active, since 7m), standbys: ceph-02, ceph-03
osd: 3 osds: 3 up (since 5m), 3 in (since 5m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 147 GiB / 150 GiB avail
pgs:
#这里已经看到mgr已经添加上去,只有ceph-01节点为active,其余节点均为standbys四、RBD 块存储
块存储是存储区域网络中使用的一个数据存储类型。在这种类型中,数据以块的形式存储在卷里,卷会挂载到节点上。可以为应用程序提供更大的存储容量,并且可靠性和性能都更高。
RBD协议,也就是Ceph块设备 (Ceph Block Device)。RBD除了可靠性和性能之外,还支持完整和增量式快照,精简的配置,写时复制(copy-on-write)式克隆。并且支持全内存式缓存。
目前CEPH RBD支持的最大镜像为16EB,镜像可以直接作为磁盘映射到物理裸机,虚拟机或者其他主机使用,KVM和Xen完全支持RBD,VMware等云厂商也支持RBD模式
RBD数据写入流程
创建资源池Pool
[root@ceph-01 ~]# ceph osd pool create abcdocker 64 64
pool 'abcdocker' created
#abcdocker为pool名称
#pg为64个 (pg和pgp数量需要一致)
#pgp为64个
#我们不需要指定副本,默认就为三个副本我们可以查看到pool
[root@ceph-01 ~]# ceph osd lspools
1 abcdocker可以通过下面的命令获取到pool详细状态
#下面是可以查看的参数,不比如我们就看一下刚刚创建的pg数量还有pgp的数量
[root@ceph-01 ~]# ceph osd pool get abcdocker
Invalid command: missing required parameter var(size|min_size|pg_num|pgp_num|crush_rule|hashpspool|nodelete|nopgchange|nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|use_gmt_hitset|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|all|min_write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority|compression_mode|compression_algorithm|compression_required_ratio|compression_max_blob_size|compression_min_blob_size|csum_type|csum_min_block|csum_max_block|allow_ec_overwrites|fingerprint_algorithm|pg_autoscale_mode|pg_autoscale_bias|pg_num_min|target_size_bytes|target_size_ratio)
[root@ceph-01 ~]# ceph osd pool get abcdocker pg_num
pg_num: 64
[root@ceph-01 ~]# ceph osd pool get abcdocker pgp_num
pgp_num: 64还可以查看一下副本数量
默认情况下pool会为我们找到3个osd副本,保证高可用
[root@ceph-01 ~]# ceph osd pool get abcdocker size
size: 3当然这些默认的参数也是可以修改的,比如我们修改一下osd副本数量
[root@ceph-01 ~]# ceph osd pool set abcdocker size 2
set pool 1 size to 2
[root@ceph-01 ~]# ceph osd pool get abcdocker size
size: 2RBD创建和映射
在创建镜像前我们还需要修改一下features值
在Centos7内核上,rbd很多特性都不兼容,目前3.0内核仅支持layering。所以我们需要删除其他特性
- layering: 支持分层
- striping: 支持条带化 v2
- exclusive-lock: 支持独占锁
- object-map: 支持对象映射(依赖 exclusive-lock)
- fast-diff: 快速计算差异(依赖 object-map)
- deep-flatten: 支持快照扁平化操作
- journaling: 支持记录 IO 操作(依赖独占锁)
关闭不支持的特性一种是通过命令的方式修改,还有一种是在ceph.conf中添加rbd_default_features = 1来设置默认 features(数值仅是 layering 对应的 bit 码所对应的整数值)。
features编码如下
例如需要开启layering和striping,rbd_default_features = 3 (1+2)
属性 BIT码
layering 1
striping 2
exclusive-lock 4
object-map 8
fast-diff 16
deep-flatten 32动态关闭
[root@ceph-01 ~]# cd /root/ceph-deploy
[root@ceph-01 ceph-deploy]# echo "rbd_default_features = 1" >>ceph.conf
[root@ceph-01 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-01 ceph-02 ceph-03
#当然也在rbd创建后手动删除,这种方式设置是临时性,一旦image删除或者创建新的image 时,还会恢复默认值。
rbd feature disable abcdocker/abcdocker-rbd.img deep-flatten
rbd feature disable abcdocker/abcdocker-rbd.img fast-diff
rbd feature disable abcdocker/abcdocker-rbd.img object-map
rbd feature disable abcdocker/abcdocker-rbd.img exclusive-lock
#需要按照从后往前的顺序,一条条删除RBD创建就是通过rbd命令来进行创建,例子如下
#这里我们使用ceph-01进行演示,创建rbd需要使用key,可以使用-k参数进行指定,我这里已经默认使用了admin的key,所以不需要指定
[root@ceph-01 ~]# rbd create -p abcdocker --image abcdocker-rbd.img --size 15G
#-p pool名称
#--image 镜像名称(相当于块设备在ceph名称)
#--size 镜像大小 (块大小)
#创建rbd设备还可以通过下面的方式简写
[root@ceph-01 ~]# rbd create abcdocker/abcdocker-rbd-1.img --size 15G
#省略-p和--image参数查看rbd
[root@ceph-01 ~]# rbd -p abcdocker ls
abcdocker-rbd-1.img
abcdocker-rbd.img删除rbd
[root@ceph-01 ~]# rbd rm abcdocker/abcdocker-rbd-1.img
Removing image: 100% complete...done.
#同样,删除rbd也可以简写,或者加入-p和--image我们可以通过info查看rbd信息
#第一种查看方式
[root@ceph-01 ~]# rbd info -p abcdocker --image abcdocker-rbd.img
rbd image 'abcdocker-rbd.img':
size 15 GiB in 3840 objects #可以看到空间大小,和有多少个object
order 22 (4 MiB objects) #每个object大小
snapshot_count: 0
id: 1e687dd7cfb9
block_name_prefix: rbd_data.1e687dd7cfb9 #id号
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #如果前面我们设置features 为1,这里只可以看到一个layering
op_features:
flags:
create_timestamp: Thu Sep 10 16:19:44 2020
access_timestamp: Thu Sep 10 16:19:44 2020
modify_timestamp: Thu Sep 10 16:19:44 2020
#第二种查看方式
[root@ceph-01 ~]# rbd info abcdocker/abcdocker-rbd.img
rbd image 'abcdocker-rbd.img':
size 15 GiB in 3840 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1e687dd7cfb9
block_name_prefix: rbd_data.1e687dd7cfb9
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Sep 10 16:19:44 2020
access_timestamp: Thu Sep 10 16:19:44 2020
modify_timestamp: Thu Sep 10 16:19:44 2020块文件挂载
接下来我们要进行rbd的挂载 (这里不建议分区,如果分区,后续扩容比较麻烦,容易存在丢数据的情况。在分区不够的情况下建议多块rbd)
[root@ceph-01 ceph-deploy]# rbd map abcdocker/abcdocker-rbd.img
/dev/rbd0
#abcdocker 为pool名称,当然可以通过-p
#abcdocker-rbd.img 为rbd文件名称上面已经生成了块设备,我们还可以通过下面的命令进行查看
[root@ceph-01 ceph-deploy]# rbd device list
id pool namespace image snap device
0 abcdocker abcdocker-rbd.img - /dev/rbd0
#可以看到pool名称,img名称,以及设备信息同样我们可以通过fdisk命令看到,现在块设备就相当于我们在服务器上插入了一块硬盘,挂载即可使用
在下面我们可以看到一个磁盘/dev/rbd0 大小16G的硬盘
[root@ceph-01 ceph-deploy]# fdisk -l
磁盘 /dev/sda:53.7 GB, 53687091200 字节,104857600 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x0009e898
设备 Boot Start End Blocks Id System
/dev/sda1 2048 6143 2048 83 Linux
/dev/sda2 * 6144 415743 204800 83 Linux
/dev/sda3 415744 104857599 52220928 83 Linux
磁盘 /dev/sdb:53.7 GB, 53687091200 字节,104857600 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/mapper/ceph--1fde1a1c--f1e7--4ce7--927a--06b7599e5cb5-osd--block--76ee00a5--6fa5--4865--ac39--aa12d5dc3623:53.7 GB, 53682896896 字节,104849408 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/rbd0:16.1 GB, 16106127360 字节,31457280 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):4194304 字节 / 4194304 字节这里不建议进行分区
接下来进行格式化操作
[root@ceph-01 ceph-deploy]# mkfs.ext4 /dev/rbd0
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: 完成
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=1024 blocks, Stripe width=1024 blocks
983040 inodes, 3932160 blocks
196608 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2151677952
120 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成现在就可以进行挂载使用了
[root@ceph-01 ceph-deploy]# mkdir /mnt/abcdocker
[root@ceph-01 ceph-deploy]# mount /dev/rbd0 /mnt/abcdocker/
[root@ceph-01 ceph-deploy]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 909M 0 909M 0% /dev
tmpfs 920M 0 920M 0% /dev/shm
tmpfs 920M 8.9M 911M 1% /run
tmpfs 920M 0 920M 0% /sys/fs/cgroup
/dev/sda3 50G 2.4G 48G 5% /
/dev/sda2 197M 147M 51M 75% /boot
tmpfs 920M 24K 920M 1% /var/lib/ceph/osd/ceph-0
tmpfs 184M 0 184M 0% /run/user/0
/dev/rbd0 15G 41M 14G 1% /mnt/abcdocker
[root@ceph-01 ceph-deploy]#
[root@ceph-01 ceph-deploy]# cd /mnt/abcdocker/
[root@ceph-01 abcdocker]# ls
lost+found
[root@ceph-01 abcdocker]# touch abcdocker
[root@ceph-01 abcdocker]# echo "123" >abcdocker
[root@ceph-01 abcdocker]# cat abcdocker
123RBD扩容
目前我们的rbd大小为15个G,这里我们演示将它扩展到30G。在不丢数据的情况下
[root@ceph-01 ~]# rbd -p abcdocker ls
abcdocker-rbd.img
[root@ceph-01 ~]# rbd info abcdocker/abcdocker-rbd.img
rbd image 'abcdocker-rbd.img':
size 15 GiB in 3840 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1e789f433420d
block_name_prefix: rbd_data.1e789f433420d
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Sep 10 16:57:59 2020
access_timestamp: Thu Sep 10 16:57:59 2020
modify_timestamp: Thu Sep 10 16:57:59 2020
[root@ceph-01 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 909M 0 909M 0% /dev
tmpfs 920M 0 920M 0% /dev/shm
tmpfs 920M 8.9M 911M 1% /run
tmpfs 920M 0 920M 0% /sys/fs/cgroup
/dev/sda3 50G 2.4G 48G 5% /
/dev/sda2 197M 147M 51M 75% /boot
tmpfs 920M 24K 920M 1% /var/lib/ceph/osd/ceph-0
/dev/rbd0 15G 41M 14G 1% /mnt/abcdocker接下来使用resize参数进行扩容
[root@ceph-01 ~]# rbd resize abcdocker/abcdocker-rbd.img --size 30G
Resizing image: 100% complete...done.
#abcdocker为pool名称
#abcdocker-rbd.img为镜像文件
#--size 为扩容后镜像大小现在我们可以在查看一下abcdocker-rbd.img镜像大小
#下面我们可以看到我们的size大小已经修改为30G,对应的object也已经成了7680
[root@ceph-01 ~]# rbd info abcdocker/abcdocker-rbd.img
rbd image 'abcdocker-rbd.img':
size 30 GiB in 7680 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1e789f433420d
block_name_prefix: rbd_data.1e789f433420d
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Sep 10 16:57:59 2020
access_timestamp: Thu Sep 10 16:57:59 2020
modify_timestamp: Thu Sep 10 16:57:59 2020扩容之后我们的设备是已经扩容上去,但是我们的文件系统并没有扩容上
接下来我们需要使用resize2fs对文件系统进行扩容
关于resize2fs解释:
调整ext2ext3ext4文件系统的大小,它可以放大或者缩小没有挂载的文件系统的大小。如果文件系统已经挂载,它可以扩大文件系统的大小,前提是内核支持在线调整大小
此命令的适用范围:RedHat、RHEL、Ubuntu、CentOS、SUSE、openSUSE、Fedora。
只需要执行resize2fs加上文件系统的地址即可,扩容完毕我们就可以看到/dev/rbd0大小为28G
[root@ceph-01 ~]# resize2fs /dev/rbd0
我们可以到挂载的目录进行查看,之前创建的数据也还在
[root@ceph-01 ~]# ls /mnt/abcdocker/
abcdocker lost+found
[root@ceph-01 ~]# cat /mnt/abcdocker/abcdocker
123对于扩容一般会涉及三方面的内容: 1.底层存储(rbd resize) 2.磁盘分区的扩容 (例如mbr分区) 3.Linux文件系统的扩容
所以这里不建议在rbd块设备进行分区
CEPH警告处理
当我们osd有数据写入时,我们在查看ceph集群。发现ceph集群目前有警告这时候我们就需要处理这些警告
[root@ceph-01 ~]# ceph -s
cluster:
id: 0d2ca51e-38cd-4d34-b73d-2ae26f7e2ffd
health: HEALTH_WARN
application not enabled on 1 pool(s)
1 daemons have recently crashed
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 7h)
mgr: ceph-01(active, since 2d), standbys: ceph-02, ceph-03
osd: 3 osds: 3 up (since 2d), 3 in (since 2d)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 5 pools, 192 pgs
objects: 348 objects, 382 MiB
usage: 4.1 GiB used, 146 GiB / 150 GiB avail
pgs: 192 active+clean当我们创建pool资源池后,必须制定它使用ceph应用的类型 (ceph块设备、ceph对象网关、ceph文件系统)
如果我们不指定类型,集群health会提示HEALTH_WARN
#我们可以通过ceph health detail命令查看ceph健康详情的信息
[root@ceph-01 ~]# ceph health detail
HEALTH_WARN application not enabled on 1 pool(s); 1 daemons have recently crashed
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)
application not enabled on pool 'abcdocker'
use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.接下来我们将这个pool资源池进行分类,将abcdocker pool标示为rbd类型
[root@ceph-01 ~]# ceph osd pool application enable abcdocker rbd
enabled application 'rbd' on pool 'abcdocker'如果我们在创建pool进行初始化后,就不会提示这个报错
rbd pool init <pool-name>
当我们初始化后,rbd会将我们的pool修改为rbd格式。 健康状态自然就不会报错
设置完毕后,我们通过下面的命令可以看到pool目前的类型属于rbd类型
[root@ceph-01 ~]# ceph osd pool application get abcdocker
{
"rbd": {}
}处理完application告警,我们继续查看ceph健康信息
[root@ceph-01 ~]# ceph health detail
HEALTH_WARN 1 daemons have recently crashed
RECENT_CRASH 1 daemons have recently crashed
mon.ceph-01 crashed on host ceph-01 at 2020-09-11 12:01:02.351322Z这里我们发现monitor ceph-01节点有告警,大致意思是ceph-01节点有一个crashed守护进程崩溃了。
官方解释如下
One or more Ceph daemons has crashed recently, and the crash has not yet been archived (acknowledged) by the administrator. This may indicate a software bug, a hardware problem (e.g., a failing disk), or some other problem.
一个或多个Ceph守护进程最近崩溃,管理员尚未存档(确认)崩溃。这可能表示软件错误、硬件问题(例如,磁盘故障)或其他问题。
这个报错并不影响我们,我们可以通过下面的命令看到crashed进程 (只要我们其他组件都是正常的,那么这一条就多半是误报。生产环境中处理这个故障还是要根据实际情况进行处理,不可以盲目的删除告警)
[root@ceph-01 ~]# ceph crash ls-new
ID ENTITY NEW
2020-09-11_12:01:02.351322Z_eacf8b0d-f25c-4b2d-9d14-aa9a7fa9c6d4 mon.ceph-01 * 同时还可以使用ceph crash info [ID]查看进程详细信息
那么如何处理这个警告呢
第一种方法 (适合处理单个告警)
ceph crash archive <ID>第二种方法 (将所有的crashed打包归档)
[root@ceph-01 ~]# ceph crash archive-all
[root@ceph-01 ~]# ceph crash ls-new我们再次查看状态就已经恢复
[root@ceph-01 ~]# ceph -s
cluster:
id: 0d2ca51e-38cd-4d34-b73d-2ae26f7e2ffd
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 7h)
mgr: ceph-01(active, since 2d), standbys: ceph-02, ceph-03
osd: 3 osds: 3 up (since 2d), 3 in (since 2d)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 5 pools, 192 pgs
objects: 348 objects, 382 MiB
usage: 4.1 GiB used, 146 GiB / 150 GiB avail
pgs: 192 active+clean五、RGW 对象存储
对象存储是什么?
可以理解是一个海量的存储空间,可以通过API在任何时间、任何地点访问对象存储里面的数据。我们常用的阿里云OSS、七牛云存储以及百度网盘、私有网盘等都属于对象存储。
Cpeh是一个分布式对象存储系统,通过它的对象网关(object gateway),也就是RADOS网关(radosgw)提供对象存储接口。RADOS网关利用librgw (RADOS网关库)和librados这些库,允许应用程序跟CEPH对象存储建立连接。Ceph通过RESTful API提供可访问且最稳定的多租户对象存储解决方案之一。
RADOS网关提供RESTful接口让用户的应用程序将数据存储到CEPH集群中。RADOS网关接口满足以下特点;
- 兼容Swift: 这是为了OpenStack Swift API提供的对象存储功能
- 兼容S3: 这是为Amazon S3 API提供的对象存储功能
- Admin API: 这也称为管理API或者原生API,应用程序可以直接使用它来获取访问存储系统的权限以及管理存储系统
除了上述的特点,对象存储还有以下特点
- 支持用户认证
- 使用率分析
- 支持分片上传 (自动切割上传重组)
- 支持多站点部署、多站点复制

对象存储网关架构讲解
5.1 部署RGW存储网关
使用ceph对象存储我们需要安装对象存储网关(RADOSGW)
ceph-radosgw软件包我们之前是已经安装过了,这里可以检查一下
[root@ceph-01 ~]# rpm -qa|grep ceph-radosgw
ceph-radosgw-14.2.11-0.el7.x86_64
#如果没有安装可以通过yum install ceph-radosgw安装部署对象存储网关
这里我使用ceph-01当做存储网关来使用
[root@ceph-01 ~]# cd /root/ceph-deploy
[root@ceph-01 ceph-deploy]# ceph-deploy rgw create ceph-01创建完毕后我们可以查看一下,这里rgw只有一个服务器,那就是ceph-01
[root@ceph-01 ceph-deploy]# ceph -s|grep rgw
rgw: 1 daemon active (ceph-01)并且radosgw监听7480端口
[root@ceph-01 ceph-deploy]# netstat -lntup|grep 7480
tcp 0 0 0.0.0.0:7480 0.0.0.0:* LISTEN 21851/radosgw
tcp6 0 0 :::7480 :::* LISTEN 21851/radosgw到这里我们已经安装完毕
接下来我们进行修改一下端口,默认是7480;这里我们将端口修改为80端口
vim /root/ceph-deploy/ceph.conf
[client.rgw.ceph-01]
rgw_frontends = "civetweb port=80"
#client.rgw.[主机名] 这里需要注意修改的主机名
#还需要注意修改的目录 (这里修改的目录是/root/ceph.conf)修改完毕后,我们将配置分发下去;要让集群的主机都生效
[root@ceph-01 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-01 ceph-02 ceph-03
#这里其实只需要复制到rgw网关节点就行,但是为了配置统一,我们将配置文件分发到集群的各个节点push到各个机器后并没有生效,push相当于scp。文件没有生效,所以还需要重启rgw
[root@ceph-01 ceph-deploy]# systemctl restart ceph-radosgw.target检查配置
这里我们可以看到80端口对应的服务是radosgw
[root@ceph-01 ceph-deploy]# netstat -lntup|grep 80
tcp 0 0 10.4.81.120:6806 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6807 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6808 0.0.0.0:* LISTEN 878/ceph-mgr
tcp 0 0 10.4.81.120:6809 0.0.0.0:* LISTEN 878/ceph-mgr
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 22673/radosgw
tcp 0 0 10.4.81.120:6800 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6801 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6802 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6803 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6804 0.0.0.0:* LISTEN 1335/ceph-osd
tcp 0 0 10.4.81.120:6805 0.0.0.0:* LISTEN 1335/ceph-osd如果你想让http支持https也是在ceph配置文件中添加参数
#例子如下 (这里我没有测试,这里是官方文档的参数)
[client.rgw.ceph-01]
rgw_frontends = civetweb port=443s ssl_certificate=/etc/ceph/keyandcert.pem5.2 调用对象存储网关
我们先创建一个s3的用户,获取到key之后访问对象存储
[root@ceph-01 ~]# cd /root/ceph-deploy/
[root@ceph-01 ceph-deploy]# radosgw-admin user create --uid ceph-s3-user --display-name "Ceph S3 User Demo abcdocker"
{
"user_id": "ceph-s3-user", #uid名称
"display_name": "Ceph S3 User Demo abcdocker", #名称
"email": "",
"suspended": 0,
"max_buckets": 1000, #默认创建有1000个backets配额
"subusers": [],
"keys": [
{
"user": "ceph-s3-user",
"access_key": "35T0JSZ0CXMX646CW7LD", #这里的key是我们后期访问radosgw的认证,如果忘记了可以通过radosgw-admin user info --uid ceph-s3-user查看
"secret_key": "bbRpqDC2VlDko8nCD5JBgg4o0HBCeIbvTb1CziFc"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
--uid 指定一个uid名称
--display-name 指定一个全名这里的key我们已经获取到了,接下来我们使用s3的接口进行访问
首先安装python-bot包
yum install python-boto编写Python sdk脚本
import boto
import boto.s3.connection
access_key = '35T0JSZ0CXMX646CW7LD' #这里需要替换我们创建的key
secret_key = 'bbRpqDC2VlDko8nCD5JBgg4o0HBCeIbvTb1CziFc' #这里也需要替换
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = '192.168.31.20', port = 80,
is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('ceph-s3-bucket')
for bucket in conn.get_all_buckets():
print "{name}".format(
name = bucket.name,
created = bucket.creation_date,
)
#执行脚本
[root@ceph-01 ~]# python s3.py
ceph-s3-bucket执行完Python脚本,我们可以看到在pool创建了一个default.rgw.backets.index的索引
[root@ceph-01 ~]# ceph osd lspools
1 abcdocker
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index命令行调用
SDK调用方式不太适合运维操作,运维更倾向于命令行操作。下面我们进行命令行操作调用
这里使用
s3cmd工具来进行配置
# 首先我们yum 安装s3cmd
[root@ceph-01 ~]# yum install -y s3cmd
# 针对s3cmd我们需要修改一些配置参数
[root@ceph-01 ~]# s3cmd --configure
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
Access Key: 35T0JSZ0CXMX646CW7LD #这里填写我们的key
Secret Key: bbRpqDC2VlDko8nCD5JBgg4o0HBCeIbvTb1CziFc #secret key填写
Default Region [US]:
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
S3 Endpoint [s3.amazonaws.com]: 192.168.31.20:80 #s3地址
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 192.168.31.20:80/%(bucket)s #s3访问格式
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
Encryption password: #没有设置密码
Path to GPG program [/bin/gpg]:
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
Use HTTPS protocol [Yes]: no #不开启https
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name: #没有设置代理名称
New settings:
Access Key: 35T0JSZ0CXMX646CW7LD
Secret Key: bbRpqDC2VlDko8nCD5JBgg4o0HBCeIbvTb1CziFc
Default Region: US
S3 Endpoint: 192.168.31.20:80
DNS-style bucket+hostname:port template for accessing a bucket: 192.168.31.20:80/%(bucket)s
Encryption password:
Path to GPG program: /bin/gpg
Use HTTPS protocol: False
HTTP Proxy server name:
HTTP Proxy server port: 0
Test access with supplied credentials? [Y/n] Y #是否测试访问权限
Please wait, attempting to list all buckets...
Success. Your access key and secret key worked fine :-)
Now verifying that encryption works...
Not configured. Never mind.
Save settings? [y/N] Y #保存配置
Configuration saved to '/root/.s3cfg' #配置保存路径
# 需要将signature_v2 改成true
[root@ceph-01 ~]# sed -i 's/signature_v2 = False/signature_v2 = True/g' /root/.s3cfgs3cmd 目前支持两种认真的方式一种是 v2,一种是 v4,而 s3cmd 2.x 版本默认用的是 v4,而 1.x 版本默认用的是 v2,这两种认证方式是有区别的,简单来说就是 v4 除了像 v2,那样需要S3桶的 accesskey 和 secretkey,还需要如 date 等信息来签名,然后放到 http request 的 Header 上,而 s3cmd 2.x 版本支持通过在 .s3cfg 配置文件,增加选项 signature_v2 = True 来修改认证方式,所以说,如果想快速解决这个403的问题,让用户加上这个选项就可以了
s3cmd使用
[root@ceph-01 ~]# s3cmd ls #查看bucket
2022-01-27 07:31 s3://ceph-s3-bucket
[root@ceph-01 ~]# s3cmd mb s3://s3cmd-abcdocker-demo #创建bucket
Bucket 's3://s3cmd-abcdocker-demo/' created
[root@ceph-01 ~]# s3cmd ls #查看bucket
2022-01-27 07:31 s3://ceph-s3-bucket
2022-01-27 10:07 s3://s3cmd-abcdocker-demo
查看s3cmd-abcdocker-demo内容
[root@ceph-01 ~]# s3cmd ls s3://ceph-s3-bucket
#目前是空文件s3cmd 上传
[root@ceph-01 ~]# s3cmd put /etc/ s3://ceph-s3-bucket/etc/ --recursive
#上传/etc目录到s3中的/etc目录
#--recursive 递归上传
#查看
[root@ceph-01 ~]# s3cmd ls s3://ceph-s3-bucket
DIR s3://ceph-s3-bucket/etc/
[root@ceph-01 ~]# s3cmd ls s3://ceph-s3-bucket/etc/
DIR s3://ceph-s3-bucket/etc/NetworkManager/
DIR s3://ceph-s3-bucket/etc/X11/
DIR s3://ceph-s3-bucket/etc/audisp/
DIR s3://ceph-s3-bucket/etc/audit/
DIR s3://ceph-s3-bucket/etc/bash_completion.d/
DIR s3://ceph-s3-bucket/etc/ceph/
DIR s3://ceph-s3-bucket/etc/cron.d/如果
put提示ERROR: S3 error: 416 (InvalidRange)
需要将ceph.conf配置文件进行修改,添加mon_max_pg_per_osd = 1000
重启ceph-mon (systemctl restart ceph-mon@ceph-01 -->ceph-03)
s3cmd 下载
[root@ceph-01 ~]# s3cmd get s3://ceph-s3-bucket/etc/profile proxy-s3
download: 's3://ceph-s3-bucket/etc/profile' -> 'proxy-s3' [1 of 1]
1795 of 1795 100% in 0s 21.78 KB/s done
[root@ceph-01 ~]# head proxy-s3
# /etc/profile
...
#s3cmd下载的命令和上传的一样,只需要把put改成get即可s3cmd 删除
[root@ceph-01 ~]# s3cmd del s3://ceph-s3-bucket/etc/profile
delete: 's3://ceph-s3-bucket/etc/profile'
[root@ceph-01 ~]# s3cmd ls s3://ceph-s3-bucket/etc/profile
DIR s3://ceph-s3-bucket/etc/profile.d/
#删除整个目录,需要添加--recursive递归
[root@ceph-01 ~]# s3cmd del s3://ceph-s3-bucket/etc/ --recursive
[root@ceph-01 ~]# s3cmd ls s3://ceph-s3-bucket最终我们数据会在pools里面生成
[root@ceph-01 ~]# ceph osd lspools
1 abcdocker
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
[root@ceph-01 ~]# rados -p default.rgw.buckets.data ls
3ce98ebd-9642-4c30-bc3d-4dc972cb9081.4704.1__shadow_.m3QCkEFEsSz-i-AeUgua4FkwMGCmcRx_1
[root@ceph-01 ~]# rados -p default.rgw.buckets.index ls
.dir.3ce98ebd-9642-4c30-bc3d-4dc972cb9081.4704.1
.dir.3ce98ebd-9642-4c30-bc3d-4dc972cb9081.4704.3
#index为索引,data为数据六、CephFS 文件系统
6.1 CephFS介绍
6.2 CephFS安装
为什么需要使用CephFS
由于RBD不可以多个主机共享同一块磁盘,出现很多客户端需要写入数据的问题,这时就需要CephFS文件系统
我们使用高可用安装mds
[root@ceph-01 ceph-deploy]# ceph-deploy mds create ceph-01 ceph-02 ceph-03
#这里我们将ceph-01 ceph-02 ceph-03都加入到集群中来接下来我们可以看到,已经有mds了,数量为3个,状态为启动等待的状态
[root@ceph-01 ceph-deploy]# ceph -s|grep mds
mds: 3 up:standby因为没有文件系统,所以3个节点状态是启动,但是后面为等待的状态
6.3 创建pool
一个Ceph文件系统至少需要连个RADOS池,一个用于数据,一个用于元数据。
- 对元数据池使用更好的复制级别,因为此池中的任何数据丢失都可能导致整个文件系统无法访问
- 对元数据池使用SSD等低延迟存储,因为这将直接影响观察到的客户端文件系统操作的延迟。
- 用于创建文件的数据池是
默认数据池,是存储所有inode回溯信息的位置,用于硬链接管理和灾难恢复。因此,在CephFS中创建的所有inode在默认数据池中至少有一个对象。
创建存储池,数据data,元数据metadata
[root@ceph-01 ~]# ceph osd pool create cephfs_data 64 64 #创建名称为cephfs_data 的pool, pg数量为64
pool 'cephfs_data' created
[root@ceph-01 ~]# ceph osd pool create cephfs_metadata 64 64
pool 'cephfs_metadata' created
[root@ceph-01 ~]#
[root@ceph-01 ~]# ceph osd pool ls
..
cephfs_data
cephfs_metadata通常,元数据池最多有几GB的数据,建议使用比较小的PG数,64或者128常用于大型集群
6.4 创建文件系统
接下来需要创建文件系统,将刚刚创建的pool关联起来
[root@ceph-01 ~]# ceph fs new cephfs-abcdocker cephfs_metadata cephfs_data
new fs with metadata pool 9 and data pool 8
#cephfs-abcdocker为文件系统名称
#cephfs_metadata 为元数据的pool
#cephfs_data 为数据pool创建完毕后可以通过下面的命令进行查看
[root@ceph-01 ~]# ceph fs ls
name: cephfs-abcdocker, metadata pool: cephfs_metadata, data pools: [cephfs_data ]此时,我们查看mds状态,已经有一个状态为active,另外2个为standb状态
[root@ceph-01 ~]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 34h)
mgr: ceph-03(active, since 7d), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 {0=ceph-02=up:active} 2 up:standby ##ceph-02的状态为active,选举出一个当做工作节点
osd: 3 osds: 3 up (since 7d), 3 in (since 5w)
rgw: 1 daemon active (ceph-01)
task status:
data:
pools: 9 pools, 384 pgs
objects: 318 objects, 141 MiB
usage: 3.4 GiB used, 147 GiB / 150 GiB avail
pgs: 384 active+clean6.5 使用cephfs
内核驱动挂载
创建挂载点
mkdir /abcdocker执行挂载命令
[root@ceph-01 ~]# mount -t ceph ceph-01:6789:/ /abcdocker -o name=admin #ceph-01为mon节点ip,/为挂载/目录 /abcdocker 挂载点地址,name=admin,使用admin用户的权限
[root@ceph-01 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 50G 2.3G 48G 5% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 8.6M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 1.9G 24K 1.9G 1% /var/lib/ceph/osd/ceph-0
tmpfs 380M 0 380M 0% /run/user/0
tmpfs 380M 0 380M 0% /run/user/1000
192.168.31.20:6789:/ 150G 3.5G 147G 3% /abcdocker
#这里分配的空间是整个ceph的空间大小我们可以看到,挂载完linux内核会自动加载ceph模块
[root@ceph-01 abcdocker]# lsmod |grep ceph
ceph 335973 1
libceph 282661 1 ceph
dns_resolver 13140 1 libceph
libcrc32c 12644 2 xfs,libceph在内核中挂载性能会比较高一点,但是有一些场景内核可能不太支持,所以可以使用用户FUSE挂载
用户空间FUSE挂载
用户空间挂载主要使用的是ceph-fuse客户端,我们需要单独安装这个客户端
[root@ceph-01 abcdocker]# yum install ceph-fuse -y接下来创建本地的挂载点
[root@ceph-01 abcdocker]# mkdir /mnt/abcdocker使用ceph-fuse进行挂载
[root@ceph-01 abcdocker]# ceph-fuse -n client.admin -m 192.168.31.20:6789 /mnt/abcdocker/
2022-02-15 14:46:52.094 7f3d4b7bdf80 -1 init, newargv = 0x5588e55bb6f0 newargc=9
ceph-fuse[13140]: starting ceph client
ceph-fuse[13140]: starting fuse- client.admin 默认有一个client.admin的用户
- 192.168.31.20:6789 mon地址 (也可以写多个,逗号分隔)
如果我们不指定mon,默认找的是/etc/ceph/ceph.conf里面的配置文件
挂在完成后我们就可以使用df -h看一下挂载点的状态
[root@ceph-01 abcdocker]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 50G 2.3G 48G 5% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 8.6M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 1.9G 24K 1.9G 1% /var/lib/ceph/osd/ceph-0
tmpfs 380M 0 380M 0% /run/user/0
tmpfs 380M 0 380M 0% /run/user/1000
192.168.31.20:6789:/ 150G 3.5G 147G 3% /abcdocker
ceph-fuse 47G 0 47G 0% /mnt/abcdocker #用户空间的配置
[root@ceph-01 abcdocker]# cat /mnt/abcdocker/123

[…] […]
大神,我安装你这篇文章来部署,使用cephfs,在本地挂载提示mount error 113 = No route to host。端口是通的,这是为啥?
1.1排查网络
1.检查防火墙
systemctl status firewalld
systemctl stop firewalld
2.检查selinux
getenforce //如果为disabled 就是已经关闭,如果enforce 就是强制的模式
setenforce 0 //临时关闭
//开始以为是网络的问题,但是经排查,所有服务器上都没有开防火墙,并且
telnet ceph01:6789//没有问题 (yum install telnet -y)
二、解决方法
2.1 ceph状态查看
//查看ceph状态
ceph status 显示 HEALTH_OK,
2.2 mds状态查看
查看mds状态
ceph mds stat
显示:
cephfs-0/0/1 up
再查看ceph-mds状态,
systemctl status ceph-mds@ceph01
//不同节点hostname不一样 发现mds不是running,状态有问题
2.3 mds重启
重启(失败)
systemctl start ceph-mds@ceph01
报错keyring文件不存在,为了避免不必要的麻烦,决定重装mds
2.4 mds重装
1、停止mds进程。
ceph stop mds
2、将mds服务标识成失效。
ceph mds fail 0
3、删除cephfs文件系统。
ceph fs rm cephfs –yes-i-really-mean-it
4、查看ceph集群状态。
#ceph -s
//显示mds已经不存在了
5、创建MDS
ceph-deploy admin ceph01 ceph02 ceph03
ceph-deploy mds create ceph01 ceph02 ceph03
ceph mds stat
//显示cephfs-1/1/1 up {0=ceph01=up:active}, 2 up:standby
2.4 重新挂载文件系统
//mount 和 umount
//挂载
mount -t ceph ceph-01:6789:/ /mnt/cephfs/ -o name=admin
//卸载
umount /mnt/cephfs
按照你的提示排查了一遍,全部状态都正常。现在就能正常挂载了👍,感谢大神指导
不客气😏