
MySQL主从复制原理、半同步操作步骤及原理
MySQL主从复制原理、半同步操作步骤及原理
mysql
1.1 企业Linux运维场景数据同步方案
1.1.1 文件级别的异机同步方案
1、scp/sftp/nc 命令可以实现远程数据同步。
2、搭建ftp/http/svn/nfs 服务器,然后在客户端上也可以把数据同步到服务器。
3、搭建samba文件共享服务,然后在客户端上也可以把数据同步到服务器。
4、利用rsync/csync2/union等均可以实现数据同步 提示:union可实现双同步,csync2可实现多机同步。
以上文件同步方式如果结合定时任何或者inotify,sersync等功能,可以实现定时以及定时的数据同步。
5、文件级别也可以利用mysql,mongodb等软件作为容器实现。
6、程序向两个服务器同时写入数据,双写就是一个同步机制 特点:简单、方便、效率和文件系统级别要差一点,但是同步的节点可以提供访问。 软件的自身同步机制(mysql,oracle,mongdb,ttserver,redis....)文件放到数据库,同步到从库,再把文件拿出来。
7、DRBD文件系统级别(基于块设备复制,直接复制block)
1.1.2 文件系统级别的异机同步方案
1、drbd基于文件系统同步,相当于网络RAID1,可以同步几乎任何业务数据。mysql数据库的官方推荐drbd同步数据,所有单点服务例如:NFS、MFS(DRBD)MySQL等都可以用drbd做复制,效率很高,缺点:备机服务不可用
2、数据库同步方案:
a.自身同步机制: mysql replication,mysql主从复制(逻辑的SQL重写)物理复制方法<===drbd(从库不提供读写) oracle dataguard(物理的磁盘块,逻辑的SQL语句重写)9i从库不提供腹泻的,11g的从库实现了readonly
b.第三方drbd,参考URL Heartbeat+DRBD+MySQL高可用架构方案与实施过程细节
1.2 MySQL主从复制
MySQL的主从复制方案,和上述文件及文件系统级别同步是类似的,都输数据的传输。只不过MySQL无需借助第三方工具,而是其自带的同步复制功能,另外一点,MySQL的主从复制并不是从硬盘给上文件直接同步,而是逻辑的binlog日志同步到本地的应用执行的过程
提示:官方说主从不要超过9台,推荐不超过5台。
1、单向主从复制逻辑图

2、双向主主同步逻辑图,此架构可以在Master1端或Master2端进行数据写入

3、线性级联单向双主同步逻辑图,此架构只能在Master1端进行数据写入
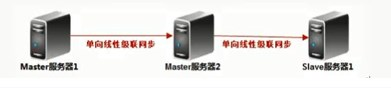
4、环状级联单向多主同步逻辑图,任何一个点都可以写入数据

5、环状级联单向多主多从同步逻辑图,此架构只能在任意一个Master端进行数据写入
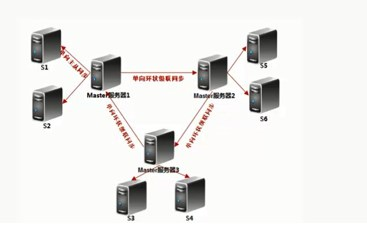
MySQL官方的同步架构图

工作中第一种方案和第二种方案最常用
1.3 MySQL主从复制原理介绍
MySQL的主从复制是一个异步的复制过程(虽然一般情况下感觉是实时的),数据将从一个Mysql数据库(我们称之为Master)复制到另一个Mysql数据库(我们称之为Slave),在Master与Slave之间实现整个主从复制的过程是由三个线程参与完成的。其中有两个线程(SQL线程和IO线程)在Slave端,另一个线程(I/O线程)在Master端。 要实现MySQL的主从复制,首先必须打开Master端的binlog记录功能,否则就无法实现。因为整个复制过程实际上就是Slave从aster端获取binlog日志,然后再在Slave上以相同顺序执行获取的binlog日志中的记录的各种SQL操作
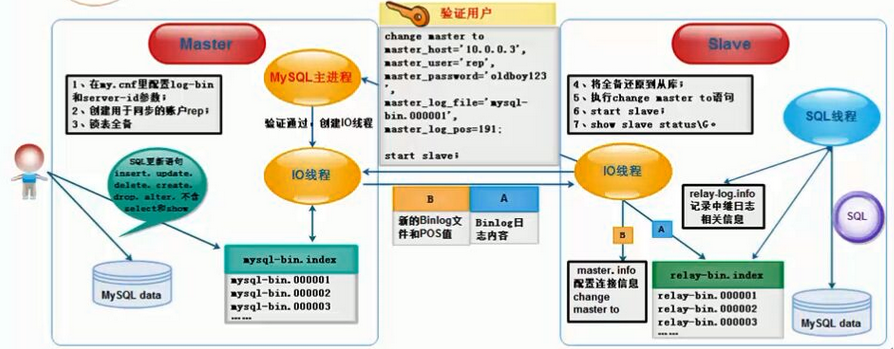

画图:
1)在Slave 服务器上执行sart slave命令开启主从复制开关,开始进行主从复制。
2)此时,Slave服务器的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change
master命令指定的)之后开始发送binlog日志内容
3)Master服务器接收到来自Slave服务器的IO线程的请求后,其上负责复制的IO线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在Master服务器端记录的IO线程。返回的信息中除了binlog中的下一个指定更新位置。
4)当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
5)Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点
主从复制条件
1、开启Binlog功能 2、主库要建立账号 3、从库要配置master.info(CHANGE MASTER to...相当于配置密码文件和Master的相关信息) 4、start slave 开启复制功能
知识点
1.3个线程,主库IO,从库IO和SQL及作用 2.master.info(从库)作用 3.relay-log 作用 4.异步复制 5.binlog作用(如果需要级联需要开启Binlog)
小结:
主从复制是异步的逻辑的SQL语句级的复制 复制时,主库有一个I/O线程,从库有两个线程,I/O和SQL线程 实现主从复制的必要条件是主库要开启记录binlog功能 作为复制的所有Mysql节点的server-id都不能相同 binlog文件只记录对数据库有更改的SQL语句(来自主库内容的变更),不记录任何查询(select,show)语句
1.4 环境搭建
我们准备的是多实例,一台服务器开启3个服务端口不同
环境准备:
[root@db02 3307]# netstat -lntup|grep 330
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 3074/mysqld
tcp 0 0 0.0.0.0:3307 0.0.0.0:* LISTEN 33364/mysqld
tcp 0 0 0.0.0.0:3308 0.0.0.0:* LISTEN 34084/mysqld
主库开启Binlog功能
[root@db02 3307]# grep log-bin /data/3306/my.cnf log-bin = /data/3306/mysql-bin
设置server-id,此处ID不可以相同否则最后出现IO错误
[root@db02 3307]# grep server-id /data/3306/my.cnf
server-id = 1
[root@db02 3307]# grep server-id /data/3307/my.cnf
server-id = 3
[root@db02 3307]# grep server-id /data/3308/my.cnf
server-id = 2
======== ================================================
[root@db02 3307]# grep server-id /data/{3306,3307,3308}/my.cnf
/data/3306/my.cnf:server-id = 1
/data/3307/my.cnf:server-id = 3
/data/3308/my.cnf:server-id = 2
主库需要授权slave访问的用户
mysql>grant replication slave on *.* to 'rep'@'10.0.0.%' identified by '123456'; mysql> flush privileges; mysql>show grants for rep@'172.16.1.%'; mysql>select user,host from mysql.user
提示:#replication slave 为mysql同步的必须权限,此处不要授权all权限
因为从库现在还没有数据,或者数据不统一我们需要导入数据
锁表、查看binlog文件及位置点,主库导出全备,需要锁表(-x --master-date=2)
flush table with read lock; 锁表,窗口不能退出,退出失效 root@oldboy 05:16:22->show master status; 临界点,将来恢复就从0025开始 +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000025 | 9155 | | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec)
备份
mysqldump -uroot -p123456 -S /data/3306/mysql.sock -A -B --events|gzip >/server/backup/rep_bak$(date +%F).sql.gz [root@db02 oldboy]# ls -lrt /server/backup/ total 308 -rw-r--r-- 1 root root 20 Dec 23 2015 bak_2015-12-23.sql.gz -rw-r--r-- 1 root root 152214 Dec 23 2015 bak.sql.gz -rw-r--r-- 1 root root 152238 Jun 29 17:20 rep_bak2016-06-29.sql.gz
解锁:unlock table;
root@oldboy 05:22:00->show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000025 | 9155 | | | +------------------+----------+--------------+------------------+
#如果解锁之后还是mysql-bin.000025 说明是正确的,如果动了说明没有锁住表
#如果mysqldump 加了-F 他就会更改刷新binlog
从库操作
1.确保server-id不同
2.把主库的备份导入到从库
[root@db02 backup]# gzip -d rep_bak2016-06-29.sql.gz
[root@db02 backup]# mysql -uroot -p123456 -S /data/3307/mysql.sock
3.查找位置点,配置master.info
mysql-bin.000025 | 9155
| 主库的位置点
Mysql从库连接主库的配置信息如下:
CHANGE MASTER TO
MASTER_HOST='172.16.1.52', #这是主库的IP(域名也可以需要做解析)
MASTER_PORT=3306, #主库的端口,从库端口和主库不可以相同
MASTER_USER='rep', #这是主库上创建用来复制的用户rep
MASTER_PASSWORD='123456' #rep的密码
MASTER_LOG_FILE='mysql-bin.000025', #这里是show master
status时看到的查询二进制日志文件名称,这里不能多空格
MASTER_LOG_POS=9155; #这里是show master status时看到的二进制日志偏移量,不能多空格
提示:3307操作此步:会在/data/3307/data下面产生master.info文件
开启从库复制开关
root@oldboy 07:47:44->show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: www.etiantian.org
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000025
Read_Master_Log_Pos: 9706
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 453
Relay_Master_Log_File: mysql-bin.000025
Slave_IO_Running: Yes IO线程代表IO正常
Slave_SQL_Running: Yes SQL线程
Replicate_Do_DB:
Replicate_Ignore_DB: mysql
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 9706
Relay_Log_Space: 603
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0 延迟
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
查看检查结果:在主库创建目录查看从库是否存在即可
提示: 如果出现show master status里面没有东西说明bin-log日志没有开启
Slave_IO_Running:Yes,这是I/O线程状态,I/O线程负载从从库去主库读取binlog日志,并写入从库的中继日志中,状态为Yes表示I/O线程工作正常。 Slave_SQL_Running:Yes 这个是SQL线程状态,SQL线程负载读取中继日志(relay-log)中的数据并转换为SQL语句应用到从库数据库中,状态为Yes表示I/O线程工作正常 Seconds_Behind_Master:0 这个是在复制过程中,从库比主库延迟的描述,这个参数很重要,但企业里更准确地判断主从延迟的方法为:在主库写时间戳,然后从库读取时间戳进行比较,从而认定是否延迟。
从库提升主库步骤
mysql主从复制中,需要将备库(从库)提升为主库,需要取消其从库角色,可以通过执行以下命令:
stop slave;
reset slave all;
RESET SLAVE ALL是清除从库的同步复制信息,包括连接信息和二进制文件名、位置
从库上执行这个命令后,使用show slave status将不会有输出
1.5 生产场景下轻松部署MySQL主从复制
快速步骤MySQL主从复制
1)安装好配置从库的数据库,配置好log-bin和server-id参数
2)无需配置主库my.cnf,主库的log-bin和server-id参数默认就是配置好的。
3)登录主库,增加从库连接同步的账户,例如:rep,并授权replication同步的权限
4)使用mysqldump命令带-x和--master-data=2的命令及参数全备数据,把它恢复到从库
5)从库执行CHANGE MASTER TO....语句,需要binlog文件及对应点(因为--master-data=2已经带了)
6)从库开启同步开关,start slave
7)从库show slave status\G,检查同步状态,并在主库更新测试
步骤:
主库:
shell>mysqldump -uroot -p123456 -S /data/3306/mysql.sock -B -F -R -x --master-data=1 -A --events|gzip >/server/backup/rep3307_(date +%F).sql.gz
因为添加了master-data=1 已经为我们写好了位置点
从库:
shell>mysql -uroot -p123456 -S /data/3307/mysql.sock <./repo3307_2016-07-03.sql
mysql>CHANGE MASTER TO
MASTER_HOST='www.abcdocker.com',
MASTER_PORT=3306,
MASTER_USER='rep',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000025',
MASTER_LOG_POS=9815;
mysql>start slave
mysql>show slave status\G
错误提示:
Slave_SQL_Running:NO 下面会有提示,如果提示这个库已经创建无法创建等是可以跳过的
解决办法
stop slave;
set global sql_slave_skip_counter =1; #将同步指针向下移动,如果多次不同步,可以添加移动的数量
start slave;
查看连接的线程,每一个线程代表一个从库
root@oldboy 08:51:37->show processlist;
+----+------+-------------------+------+-------------+------+-----------------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-------------------+------+-------------+------+-----------------------------------------------------------------------+------------------+
| 2 | rep | 172.16.1.52:51317 | NULL | Binlog Dump | 68 | Master has sent all binlog to slave; waiting for binlog to be updated | NULL |
| 3 | root | localhost | NULL | Query | 0 | NULL | show processlist |
+----+------+-------------------+------+-------------+------+-----------------------------------------------------------------------+------------------+
2 rows in set (0.00 sec)
1.6 MySQL主从复制更多应用技巧实践
1. 工作中MySQL从库停止复制的故障案例
模拟重现故障的鞥能力是运维人员最重要的能力。下面就进行模拟操作。先在从库创建一个库,然后去主库创建同名的库来模拟数据冲突
mysql>show slave status;报错:且show slave status\G;
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB: mysql
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1007
Last_Error: Error 'Can't create database 'cyh'; database exists' on query. Default database: 'cyh'. Query: 'create database cyh'
对于该冲突,解决方法为:
stop slave; #临时停止同步开关
set global sql_slave_skip_counter =1; #将同步指针向下移动一个
start slave;
或可以根据错误号事先在配置文件中配置,跳过指定的不影响业务的数据的错误,例如:
[root@db02 oldboy]# grep slave-skip /data/3306/my.cnf
slave-skip-errors = 1032,1062
提示:类似由于入库重复导致的失败可以忽略,其他情况是不可以忽略需要根据公司不同业务来评估。
错误2
MYSQL ERROR 139 (HY000) 错误的解决办法
标签:mysql error 1396 it
创建用户的时候报这个错误,原因是MYSQL中已经有了这个用户,可以用mysql.user中直接删除,然后刷新权限,在创建用户就不会有这个问题了。如果是drop user先,那么mysql内部应该会自动刷新一下,那么在创建就不会这个问题看
其他可能引起复制故障的问题:
MySQL自身的原因以及人为重复插入数据
不同的数据版本会引起不同步,低版本到高版本可以,但是高版本不能往低版本同步
MySQL的运行错误或者程序BUG
binlog记录模式,例如:row level模式就比默认的语句要好
让MySQL从库记录binlog日志方法 从库需要记录binlog的场景为:当前从库还要作为其他从库的主库,例如:级联复制或者双主互为主从场景的情况下。 在从库的my.cnf中加入如下参数,然后重启服务生效 log-slave-updates #必须要有这个参数 log-bin = /data/3307/mysql-bin expire_logs_days = 7 #相当于删除7天之后的日志 1.7 Mysql主从复制延迟问题原因及解决方法 问题一: 一个主库的从库太多,导致复制延迟。 建议从库数量3-5 为宜,要复制的从节点数量过多,会导致复制延迟 问题二: 从库硬件比主库差,导致复制延迟 查看master和slave的系统配置,可能会因为机器配置的问题,包括磁盘IO、CPU、内存等各方面因素造成复制的延迟,一般发生在高并发大数据量写入场景。 问题三: 慢SQL语句过多 假如一条SQL语句,执行时间是20秒,那么从库执行完毕,到从库上能查到数据也至少是20秒,这样就延迟20秒了 SQL语句的优化一般要作为常规工作不断的监控和优化,如果是单个SQL的写入时间长,可以修改后分多次写入,通过查看慢查询日志或show full processlist 命令找出执行时间长的查询语句或者打的事务。 问题四: 主从复制的设计问题 例如,主从复制单线程,因为主库写并发太大,来不及传送到从库就会导致延迟。 更高版本的MySQL可以支持多线程复制,门户网站会开发自己多线程同步功能。 问题五: 主从库之间的网络延迟。 主库的网卡、网线、连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延迟,另外,跨公网主从复制很容易导致主库复制延迟 问题六: 主库读写压力大,导致复制延迟 主库硬件要搞好一点,架构的前端要加buffer以及缓存层。 通过read-only参数让从库只读访问 read-only参数选项可以让从服务器只允许来自服务器线程或具有SUPER权限的数据库用户进行更新,可以确保从服务器不接受来自用户端的非法用户更新。 read-only参数具有允许数据库更新的条件为: 具有SUPER权限的用户可以更新,不受read-only参数影响,例如:管理员root。 来自从服务器线程可以更新,不受read-only参数影响,例如:rep用户 在生产环境中,可以在从库Slave中使用read-only参数,确保从库数据不被非法更新。
read-only参数的配置如下: 方法一:启动数据库时直接带--read-only参数启动或重启,使用 mysqladmin -uroot -p123456 -S /data/3307/mysql.sock shutdown mysql_safe --defaults-file=/data/3307/my.cnf --read-only & 方法二:在my.cnf里[mysqld]模块下加read-only参数,然后重启数据库 [mysqld] read-only 1.8 Web用户专业设置方案:MySQL主从复制读写分离集群 专业的运维人员提供给开发人员的读写分离的账户设置如下: 1)访问主库和从库时使用一套用户密码,例如,用户名:web,密码:123456 2)即使访问IP不同,端口也尽量相同(3306)。例如:写库VIP为10.0.0.1 ,读库VIP为10.0.0.2 除了IP没办法修改之外,要尽量为开发人员提供方便,如果数据库前端有DAL层(DBPROXY代理)还可以只给开发人员一套用户、密码、IP、端口,这样就更专业了,剩下的都是由运维搞定。 如果给开发授权权限 方法1:主库和从库使用不同的用户,授权不同的权限。 主库上对web_w用户授权如下: 用户:web_w 密码:123456 端口3306 主库VIP:10.0.0.1 权限:SELECT,INSERT,UPDATE,DELETE 命令:GRANT SELECT,INSERT,UPDATE,DELETE ON wen.* to 'web_w'@10.0.0.% identified by '123456'; 从库对web_r用户授权如下: 用户:web_r 密码:123456 端口:3306 从库VIP:10.0.0.2 权限:SELECT 命令:GRANT SELECT ON web.* TO web@10.0.0.% identfied by '123456'; 提示:此方法显得不够专业,但是可以满发开发需求。 方法2:主库和从库使用相同的用户,但授予不同的权限。(由于主从同步 有一些可能无法同步) 主库上对web用户授权如下: 用户:web 密码:123456 端口:3306 主库VIP:10.0.0.1 权限:SELECT,INSERT,UPDATE,DELETE 命令:GRANT SELECT,INSERT,UPDATE,DELETE ON web.* TO web@10.0.0.% identified by '123456'; 从库上对web用户授权如下: 用户:web 密码:123456 端口:3306 从库VIP:10.0.0.2 权限:SELECT #由于主库和从库是同步复制的,所以从库上的Web用户会自动和主库一直,既无法实现只读select的权限。 方法3:在从库上设置read-only参数,让从库只读 主库和从库:主库和从库使用相同的用户,授予相同的权限(非ALL权限) 用户:web 密码:123546 端口:3306 主库VIP:10.0.0.8 权限:SELECT,INSERT,UPDATE,DELETE 命令:GRANT SELECT,INSERT,UPDATE,DELETE ON web.* to web_w@10.0.0.% identified by '123546'; 由于从库设置了read-only,非super权限是无法写入的,因为通过read-only参数就可以 忽略授权库Mysql同步,主库配置参数如下: binlog-ignore-db = mysql replicate-ignore-db = mysql
1.9 MySQL主从复制集群架构的数据备份策略 有了主从复制,还需要做定时全量备份 因为,如果主库有语句误操作(例如:drop database oldboy;)从库也会执行drop,这样MySQL从库就都删除了该数据。 把从库作为数据备份服务器时,备份策略如下: 高并发业务场景备份时,可以选择在一台从库上备份(Slave)把从库作为数据备份服务器时需要在从库binlog功能。 1)选择一个不对外提供服务的从库,这样可以确保和主库更新最接近,专门做数据备份用 2)开启从库的binlog功能。 备份时可以选择只停止SQL线程,停止应用SQL语句到数据库,I/O线程保留工作状态,执行命令为stop slave sql_thread;备份方式可以采取mysqldump逻辑备份或者直接物理备份,例如使用cp、tar(针对目录)工具,或xtrabackup(第三方的物理备份软件)进行备份,逻辑备份和物理备份的选择,一般是根据总的备份数据量的多少进行选择,数据库低于20G,建议选择mysqldump逻辑备份方法,安全稳定,最后把全量和binlog数据发送到备份服务器上留存
1.9 MySQL半同步
M --S1
--S2
--S3
--S4
是否事先选择好从库,从库如何选择
1)半同步从库(谷歌半同步插件 5.5自带)
---S1作为备库
第一:主库插入数据后,同时写入到S1,成功返回。
优点:两台库会同时写入数据。
缺点:写入会慢,网络不稳定,主库持续等待。
解决措施:
1.连不上S1的时候会自动转为异步
2.设置10秒超时,超时10秒转为异步
3.S1网络,硬件要好,不提供服务,只能接管。
总结:
半同步就是就是用户向mysql写入数据,先写入到主库,然后生成binlog日志。主库等待从库来取binlog日志,如果从库超过10秒没有来获取binlog日志。主库自动转换为异步,以后用户写入数据生成binlog日志,等待用户自己来取,没有取到主库也不在管理。
查看的位置在数据里的安装目录下可以找到
[root@db02 oldboy]# ll /application/mysql-5.5.49/lib/plugin/
-rwxr-xr-x 1 root root 173428 Jun 16 12:57 semisync_master.so
-rwxr-xr-x 1 root root 94098 Jun 16 12:57 semisync_slave.so
2) 从库什么也不操作,只同步主库
优点:可以立即接管主库
缺点:浪费资源 不推荐使用
3)临时选择从库
当主库宕机后,mysql 临时选择一个最接近主库的slave
确定主之后,角色切换S1提升为新主M1
主库宕机有两种情况
1、如果主库可以SSH连接,bin-log数据没丢,要把主库的bin-log补全到所有库
a.提升S1为M1的操作
1)调配置read-only,授权用户select,变成增删改查,开启binlog
2)rm -rf master.info relay-log*
3)登录数据库reset master
4)重启数据库,提升S1为M1完毕
b.所有从库:CHANGE MASTER TO,MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107
2、如果数据库连接不上
a.半同步从库提升主库,半同步数据,补全到所有从库
半同步从库提升主库的操作1-a,所有从库执行同1-b
b.S1 只当做备库的方法
提升S1为主库,操作见1-a步骤,所有从库CHANGE MASTER 同1-b
c.主库宕机实现没有指定从库为主库
选主的过程:
1.登录国有从库show processlist;里面有2个线程,查看2个线程状态
登录所有从库,分别查看master.info
[root@db02 data]# cat master.info
18
mysql-bin.000028
188
www.etiantian.org
rep
123456
3306
60
0
确保更新完毕,查看4个从库那个更快,经过测试没有延迟的情况POS差距很小,甚至一直的
选择文件及位置点最大的为主库,补全所有其他从库,和当前准备为主的数据一直。
从库提升主库的操作步骤(简单说明)
提升的主库操作
1.确保所有relay log全部更新完毕
在每个库执行seop slave in_thread(sql线程);show processlit
直到看到Has read all relay log;表示从库更新都执行完毕;
2.登录从库提升为主库
登录:mysql -uroot -p123456 -S /data/3306/mysql.sock
stop slave;
retset master;
quit;
3.进到数据库数据目录,删除master.info relay-log.info
cd /data/3306/data
rm -rf master.info relay-log.info
检查mysql授权表(web用户权限以及从库同步的权限)是不是正确的
read-only等参数
确认bin-log是否开启
4.开启binlog
vim /data/3306/my.cnf
log-bin = /data/3306/mysql-bin
//如果存在log-slave-updates read-only等一定要注释掉它。
/data/3306/mysql restart
到此为止,提升主库完毕
其他从库操作
登录从库
stop slave;
CHANGE MASTER TO MASTER_HOST ='192.168.1.1'; #如果不同步,就指定位置点。
start slave;
show slave status\G
==========================主库宕机切换成功
修改程序配置文件从主数据库32指定32
平时访问数据库用域名,则直接可以修改hosts解析。
HMA高可用根据就是利用以上原理实现的
以上是mysql主库意外宕机。
假如:我们有计划切换,如何从操作?
1.主库锁表
2.登录所有的库查看同步状态,是否完成
步骤和前面相同
2.1 MySQL常用高可用方案
mysql+HA+DRBD高可用场景
mysql+MMM mysql+MHA(日本人开发)
实现原理:把所有服务器之间做了一个SSH免密钥登录,控制台登录到主库分发binlog到所有从库,在上从库比对哪一个更快更全
PXC
mysql+cluster (企业很少使用)
很多企业常用M-S


你的博客写得太详细啊,牛牛牛!!!!