
RabbitMQ 基础概念
RabbitMQ 工作原理
-
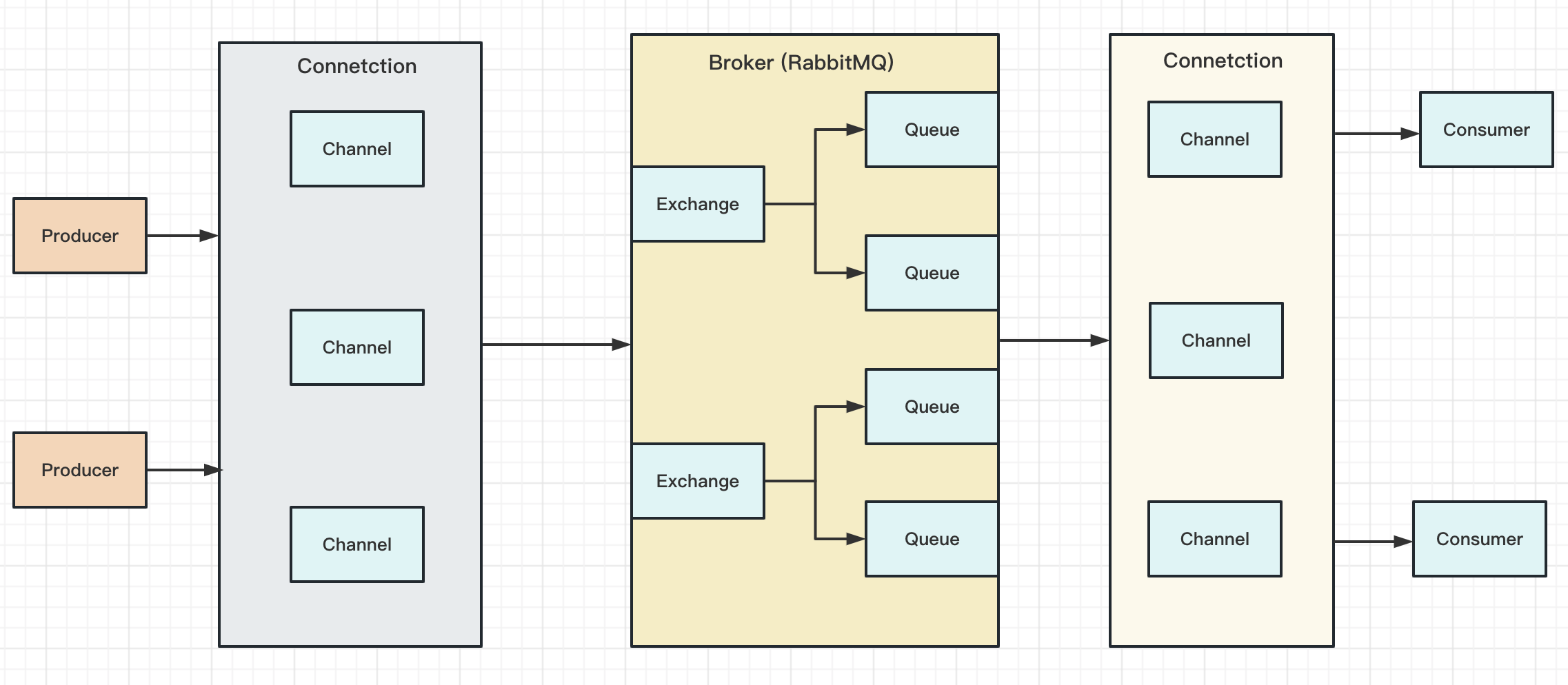
Broker: 接收和分发消息的应用,RabbitMQ Server就是Message Broker
-
Virtual host: 处于多租户和安全因素设计,把AMQP的基本组件划分到一个虚拟分组中,类似于网络中的namespace概念。当多个不同的用户使用同一个RabbitMQ 提供服务时,可以划分为多个vhost,每个用户在自己的vhost创建
exchange(交换机) /queue(队列)。 其中一个exchange(交换机)可以有多个queue(队列) -
Connection: publisher(发布) / consumer(接收)和Broker(RabbitMQ)之间的TCP连接
-
Channel: 信道,如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也比较低。Channel是在Connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通信,AMQP method包含了channel id帮助客户端和RabbitMQ识别channel,所以channel之间是完全隔离的
-
Exchange: message到达Broker的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。
-
Queue: 消息最终被送到这里等待consumer取走
-
RoutingKey: 绑定交换机和队列
RabbitMQ消息类型
direct: 路由模式是在使用交换机的同时,生产者指定路由发送数据,消费者绑定路由接受数据。与发布/订阅模式不同的是,发布/订阅模式只要是绑定了交换机的队列都会收到生产者向交换机推送过来的数据。而路由模式下加了一个路由设置,生产者向交换机发送数据时,会声明发送给交换机下的那个路由,并且只有当消费者的队列绑定了交换机并且声明了路由,才会收到数据
fanout: 广播模式其实就是将交换机(Exchange)里的消息发送给所有绑定该交换机的队列,忽略routingKey
headers: 头路由模型它不关心路由key是否匹配,而只关心header中的key-value对是否匹配(这里的匹配为精确匹配,包含键和值都必须匹配), 有点类似于http中的请求头。headers头路由模型中,消息是根据prop即请求头中key-value来匹配的。
topic: 主题模式主题模式可以简单的理解为可以动态路由,*代表一个单词,#可以代替零个或多个单词,单词最多 255 个字节,通过相关的匹配规则后就会将满足条件的消息放到对应的队列中,每个单词之间要用点隔开
临时队列没有D
环境安装
建议所有节点都安装规范安装相关服务
安装软件包
wget https://d.frps.cn/file/tools/rabbitmq/erlang-24.3.4.3-1.el8.x86_64.rpm
wget https://d.frps.cn/file/tools/rabbitmq/erlang-24.3.4.8-1.el9.x86_64.rpm
wget https://d.frps.cn/file/tools/rabbitmq/rabbitmq-server-generic-unix-3.9.29.tar.xz
rpm -ivh socat-1.7.3.2-5.el7.lux.x86_64.rpm
rpm -ivh erlang-23.3.4.7-1.el7.x86_64.rpm
rpm -ivh rabbitmq-server-3.9.7-1.el7.noarch.rpm 设置host以及修改主机名
cat >> /etc/hosts<<EOF
192.168.31.70 web01
192.168.31.71 web02
192.168.31.72 web03
EOF
hostnamectl set-hostname web01 #自行修改
hostnamectl set-hostname web02
hostnamectl set-hostname web03开启web管理接口
systemctl start rabbitmq-server
systemctl enable rabbitmq-server
rabbitmq-plugins enable rabbitmq_management # web管理接口检查端口
[root@web-03 rabbitmq]# lsof -i:15672
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
beam.smp 5868 rabbitmq 35u IPv4 1566500 0t0 TCP *:15672 (LISTEN)
[root@web-03 rabbitmq]# lsof -i:5672
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
beam.smp 5868 rabbitmq 33u IPv6 1573056 0t0 TCP *:amqp (LISTEN)
删掉默认guest用户
rabbitmqctl delete_user guest添加管理用户并设置密码
rabbitmqctl add_user admin admin # 添加新用户
rabbitmqctl set_user_tags admin administrator # 设置用户tag
rabbitmqctl set_permissions -p / admin ".*" ".*" ".*" # 赋予用户默认vhost的全部操作权限创建普通用户
rabbitmqctl add_vhost /abc #创建名称为/abc的虚拟空间
rabbitmqctl add_user user01 user01_p #创建用户名为user01,密码为user01_p
rabbitmqctl set_user_tags user01 management #授权用户为普通管理者(management)
rabbitmqctl set_permissions -p /abc user01 '.*' '.*' '.*' #授权用户归属于/abc虚拟主机,权限为所有RabbitMQ用户权限分为以下几类
(1) 超级管理员(administrator)
可登陆管理控制台(启用management plugin的情况下),可查看所有的信息,并且可以对用户,策略(policy)进行操作。
(2) 监控者(monitoring)
可登陆管理控制台(启用management plugin的情况下),同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
(3) 策略制定者(policymaker)
可登陆管理控制台(启用management plugin的情况下), 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。
(4) 普通管理者(management)
仅可登陆管理控制台(启用management plugin的情况下),无法看到节点信息,也无法对策略进行管理。
(5) 其他(none)
无法登陆管理控制台,通常就是普通的生产者和消费者。
访问控制台
使用admin用户访问控制台测试权限是否正常
用户名密码admin admin
控制台中可以看到之前创建的vhost以及对应的用户名密码,还可以看到连接信息(我这里新安装什么都没有)
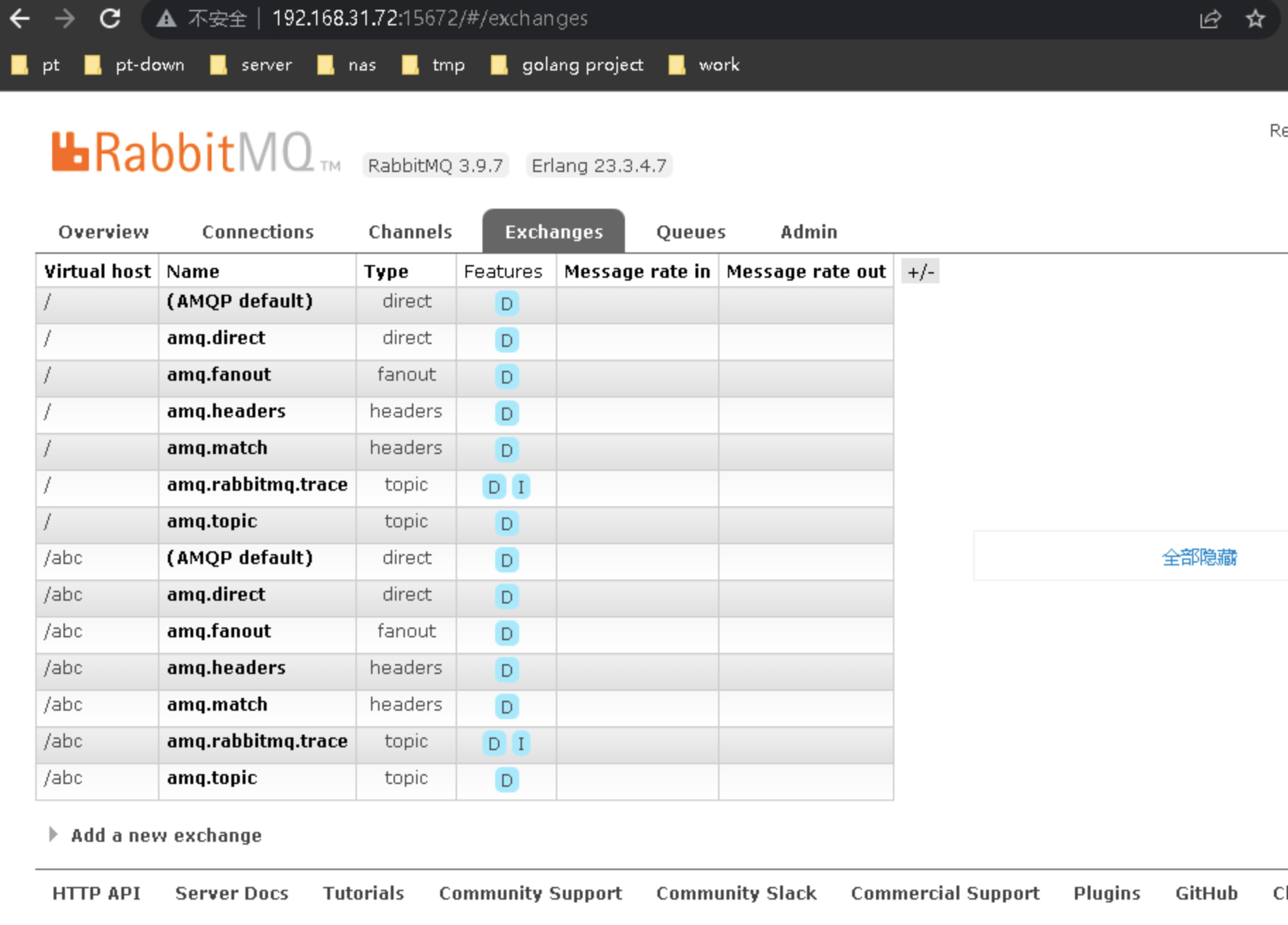
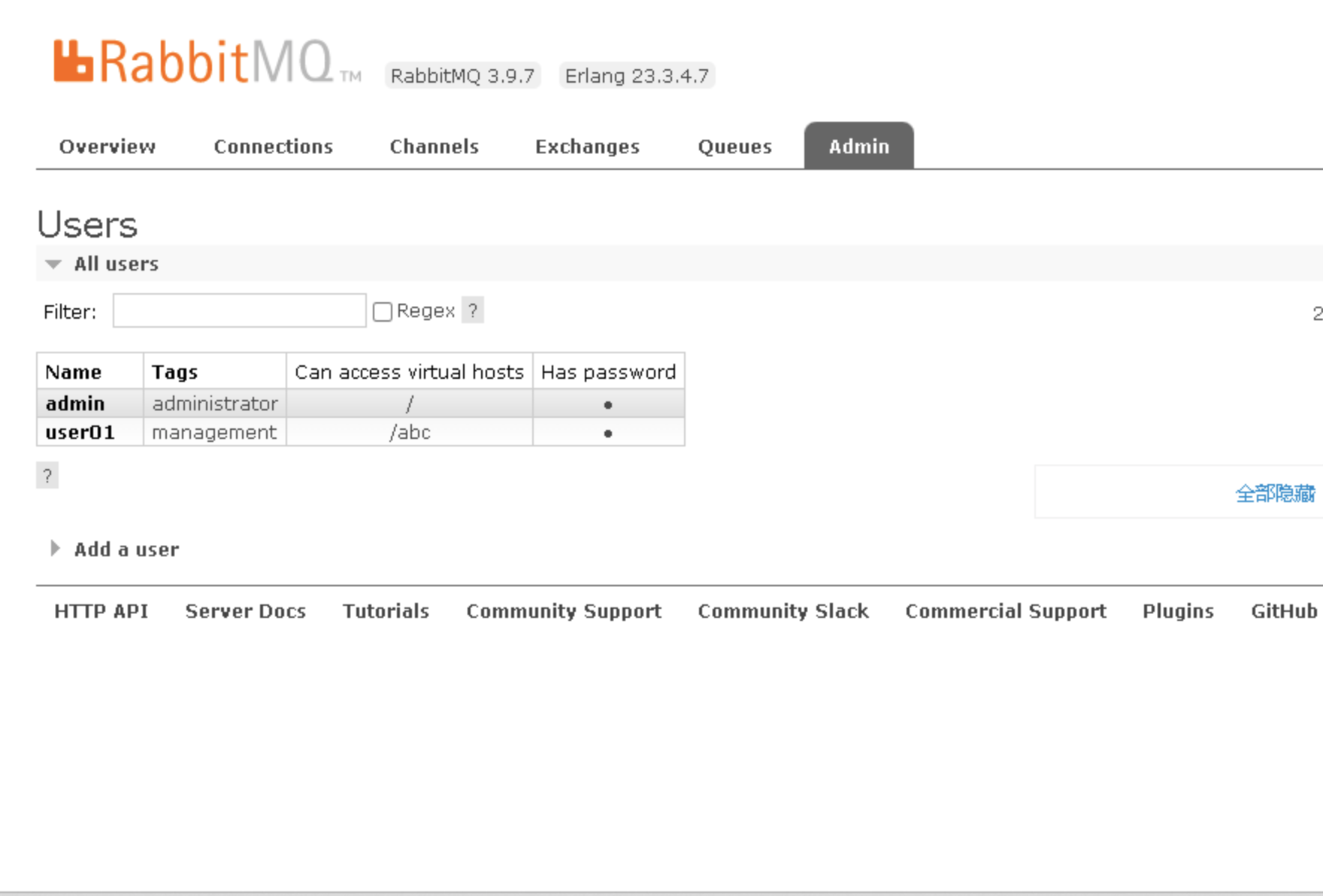
RabbitMQ 集群架构
普通扩容
横向添加集群,如果集群主节点挂掉,其它节点将无法提供服务
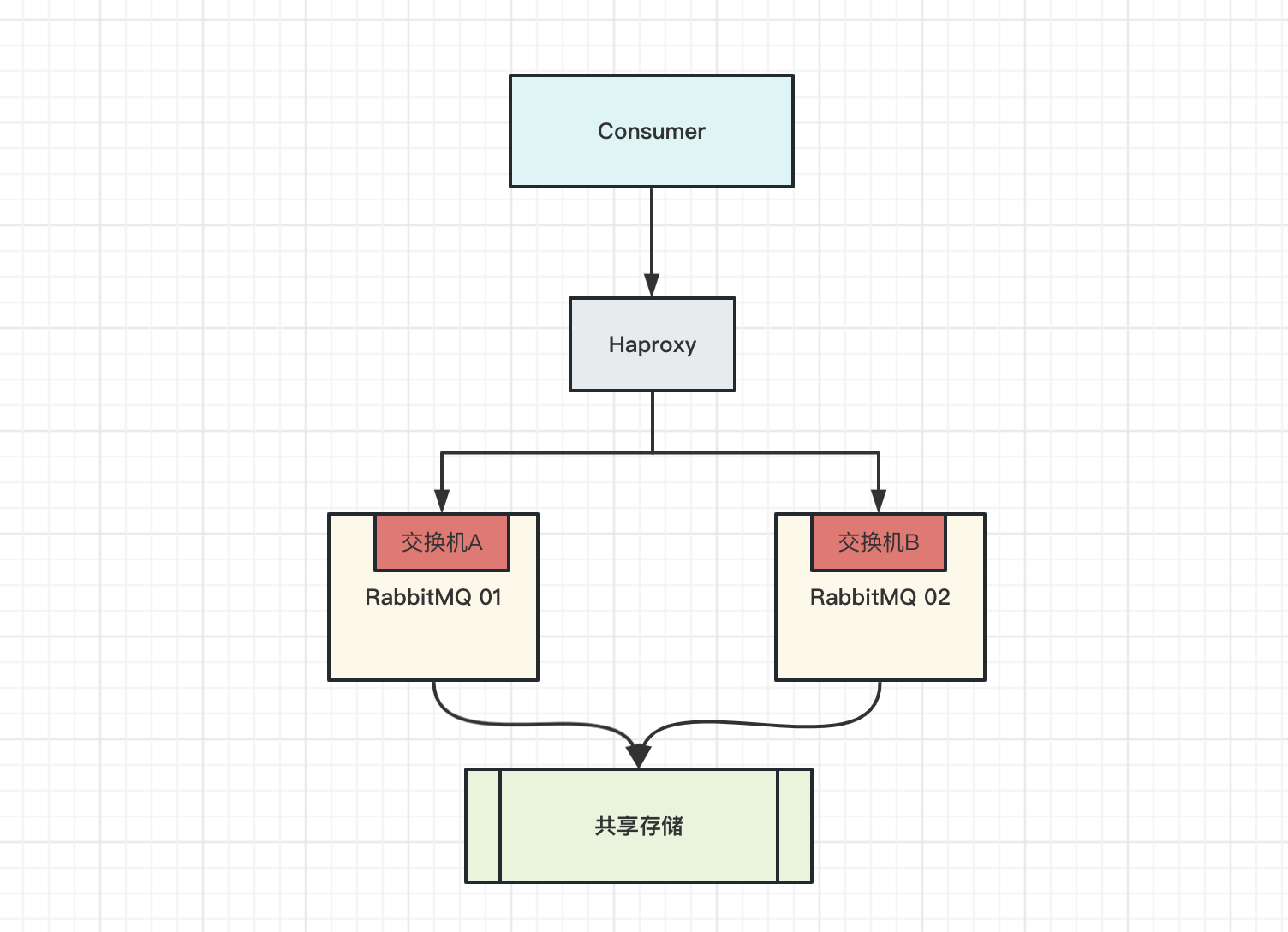
主备模式 Warren (兔子窝)
主备模式,也称之为 Warren 模式,即主节点如果挂了,切换到从节点继续提供服务
主备模式的简单架构模型,主要是利用 HaProxy 去做的主备切换,当主节点挂掉时,HaProxy 会自动进行切换,把备份节点升级为主节点
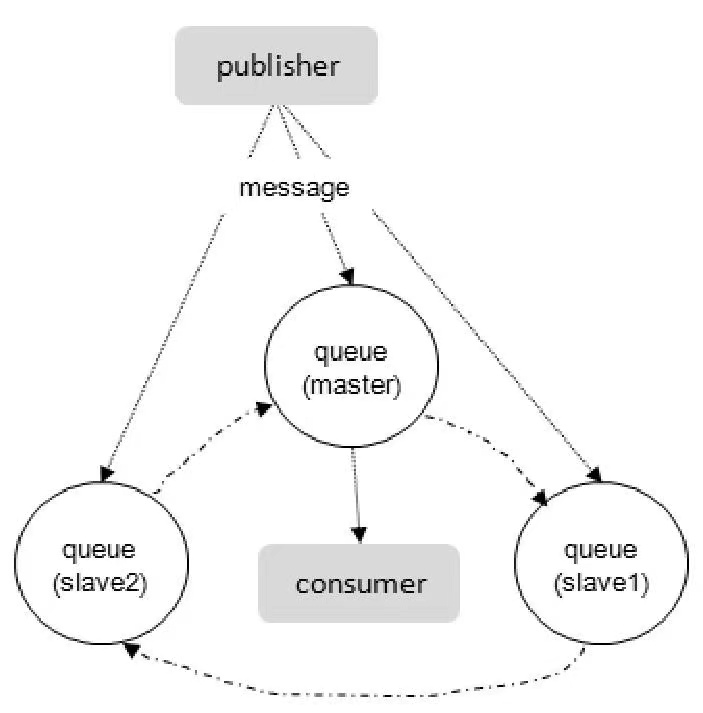
镜像模式
非常经典的 mirror 镜像模式,保证 100% 数据不丢失。在实际工作中也是用得最多的,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群模式。
mirror 镜像队列,目的是为了保证 rabbitMQ 数据的高可靠性解决方案,主要就是实现数据的同步,一般来讲是 2 - 3 个节点实现数据同步。对于 100% 数据可靠性解决方案,一般是采用 3 个节点
远程模式 Shovel
远程模式可以实现双活的一共模式,所谓shovel就是将消息进行不同数据的复制工作。当生产者提供的消息发送给RabbitMQ集群,RabbitMQ 已经超过设定的阈值和负载,这条消息就会被传输到RabbitMQ 另外一个集群节点中。
-
多活模式(Federation插件)
-
负载均衡模式
参考:https://www.cnblogs.com/wujuntian/p/16785105.html
RabbitMQ 集群搭建
本次搭建采用RabbitMQ主备模式进行演示,当主节点若宕机,从节点提供服务。我这里采用Nginx upsteam的方式进行演示
- RabbitMQ
- Keepalived
所有软件包采用二进制安装
| 节点 | IP | 主机名 |
|---|---|---|
| Master | 192.168.31.70 | web01 |
| Node | 192.168.31.71 | web02 |
| Node | 192.168.31.72 | web03 |
| Haproxy | 192.168.31.101 | RabbitMQ入口 |
Haproxy只在192.168.31.101中安装,Haproxy代理web01、web02、web03
所有节点安装RabbitMQ,包括web01 web02 web03
#安装软件包
rpm -ivh socat-1.7.3.2-5.el7.lux.x86_64.rpm
rpm -ivh erlang-23.3.4.7-1.el7.x86_64.rpm
rpm -ivh rabbitmq-server-3.9.7-1.el7.noarch.rpm
#开启web管理接口
systemctl start rabbitmq-server
systemctl enable rabbitmq-server
rabbitmq-plugins enable rabbitmq_management # web管理接口
#检查端口
[root@web-03 rabbitmq]# lsof -i:15672
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
beam.smp 5868 rabbitmq 35u IPv4 1566500 0t0 TCP *:15672 (LISTEN)
[root@web-03 rabbitmq]# lsof -i:5672
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
beam.smp 5868 rabbitmq 33u IPv6 1573056 0t0 TCP *:amqp (LISTEN)
#删掉默认guest用户
rabbitmqctl delete_user guest
#添加管理用户并设置密码
rabbitmqctl add_user admin admin # 添加新用户
rabbitmqctl set_user_tags admin administrator # 设置用户tag
rabbitmqctl set_permissions -p / admin ".*" ".*" ".*" # 赋予用户默认vhost的全部操作权限接下来手动给所有节点创建配置文件touch /etc/rabbitmq/rabbitmq.conf
主要用于定义端口,修改存储目录
#第一种: 下载官方example文件,自行修改
wget https://github.com/rabbitmq/rabbitmq-server/blob/v3.9.x/deps/rabbit/docs/rabbitmq.conf.example
#第二种: 直接复制我这里修改好的
cat >>/etc/rabbitmq/rabbitmq.conf<<EOF
#设置rabbimq的监听端口,默认为[5672]
listeners.tcp.default = 5672
#客户端与服务端心跳间隔,用来检测通信的对端是否存活,rabbitmq使用心跳机制来保持连接,设置为0则关闭心跳,默认是600秒,600S发一次心跳包
heartbeat = 60
#包大小,若包小则低延迟,若包则高吞吐,默认131072=128K
frame_max = 131072
#连接客户端数量
channel_max = 128
#内存告警值设置(相对值)
vm_memory_high_watermark.relative = 0.4
#内存阈值,该值为默认为0.5,该值为vm_memory_high_watermark的20%时,将把内存数据写到磁盘。如机器内存16G,当RABBITMQ占用内存1.28G(160.40.2)时把内存数据放到磁盘
vm_memory_high_watermark_paging_ratio = 0.5
#磁盘可用空间设置(绝对值)
disk_free_limit.absolute = 50000
#日志是否在控制台输出
log.console = false
#控制台输出的日志级别
log.console.level = info
log.exchange = false
log.exchange.level = info
#rabbitmq管理页面端口
management.tcp.port = 15672
#rabbitmq管理页面IP地址
management.tcp.ip = 0.0.0.0
#开启guest用户的远程链接
loopback_users.guest = none
log.dir = /data/rabbitmq/log
EOF接下来创建数据存储目录以及对应的log
mkdir -p /data/rabbitmq/{data,log}
#目录授权,此步骤在rabbitmq安装成功后操作
chown -R rabbitmq:rabbitmq /data/rabbitmq重启服务
[root@web01 rabbitmq]# systemctl restart rabbitmq-server三台节点都需要执行上面初始化步骤
Master web01节点操作
拷贝主节点 /var/lib/rabbitmq/.erlang.cookie到其它web02、web03中
[root@web01 ~]# for i in web02 web03 ;do scp /var/lib/rabbitmq/.erlang.cookie root@$i:/var/lib/rabbitmq/.erlang.cookie;done保证3个节点都相同,配置使用master节点
添加集群
在所有的node节点,将自己添加到web01节点中
rabbitmqctl stop_app
rabbitmqctl join_cluster --ram rabbit@web01 #第一台节点的主机名,可以在控制台看一下
#1、默认rabbitmq启动后是磁盘节点,在cluster命令下,添加--ram为内存节点,不添加则是磁盘节点
#2、更改节点类型:先停止rabbitmq应用,rabbitmqctl change_cluster_node_type disc(ram)
#3、在rabbitmq集群中,必须有至少一个磁盘节点,否则队列元数据无法写入集群,当磁盘节点宕掉时,将无法写入新的队列元数据信息
rabbitmqctl start_app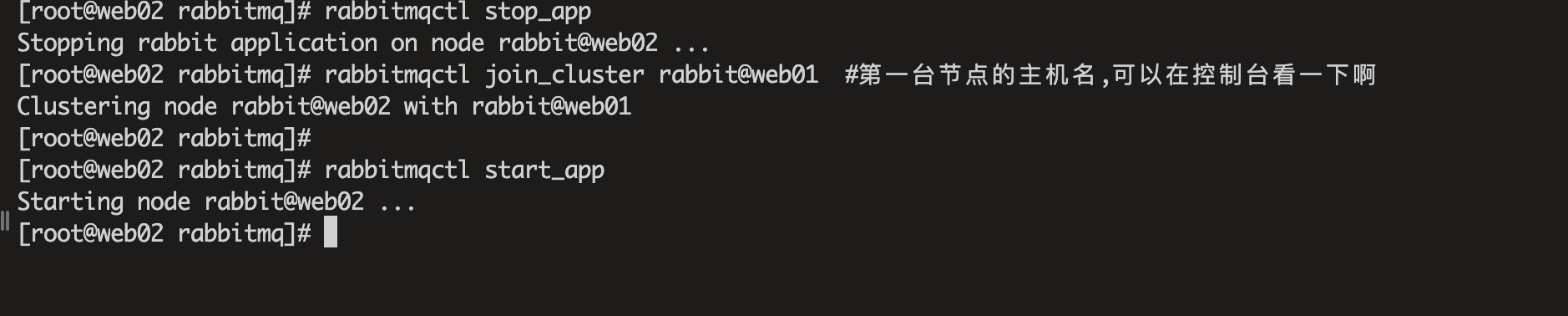
主机名如何查看?
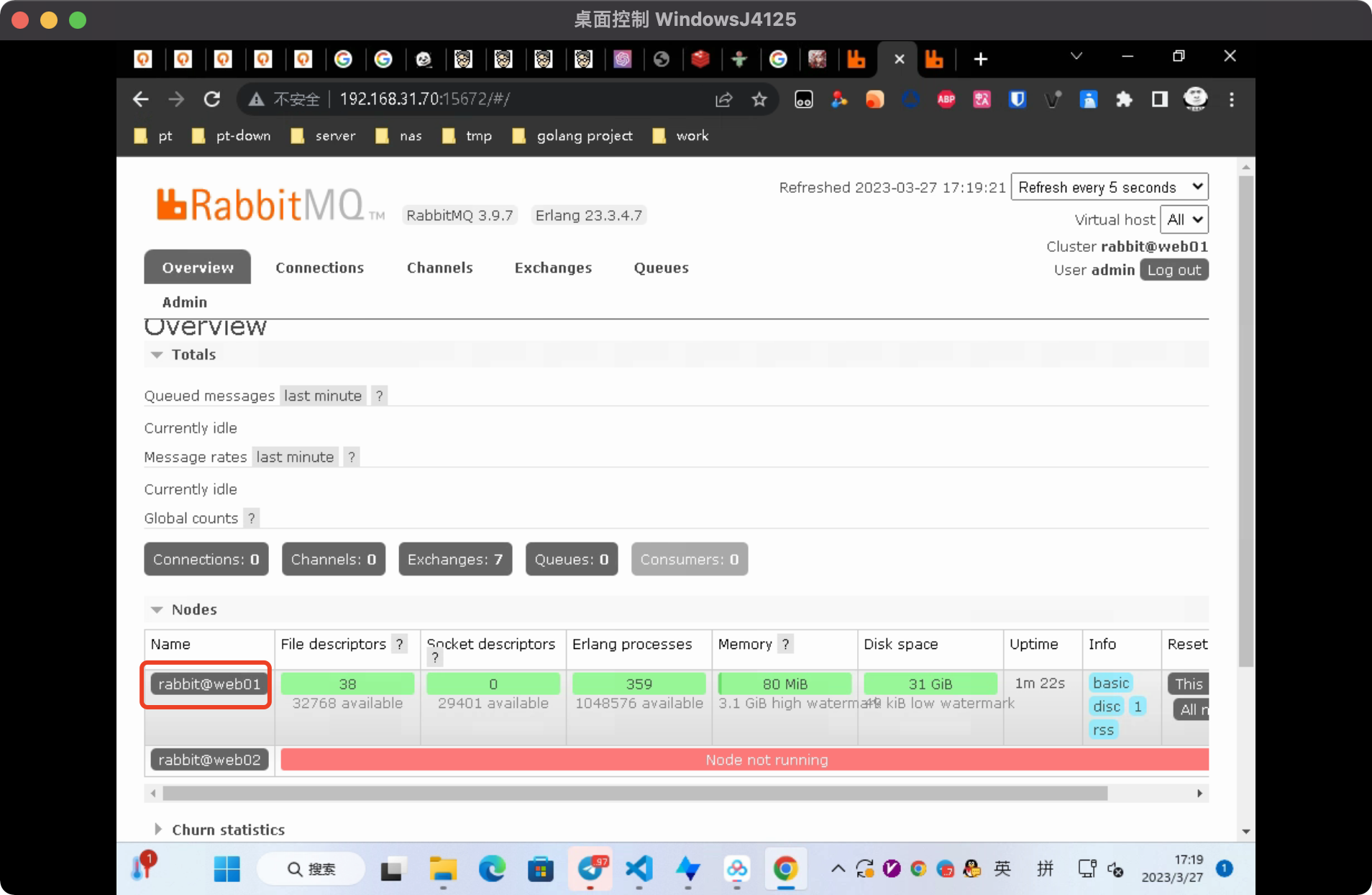
节点添加完毕后
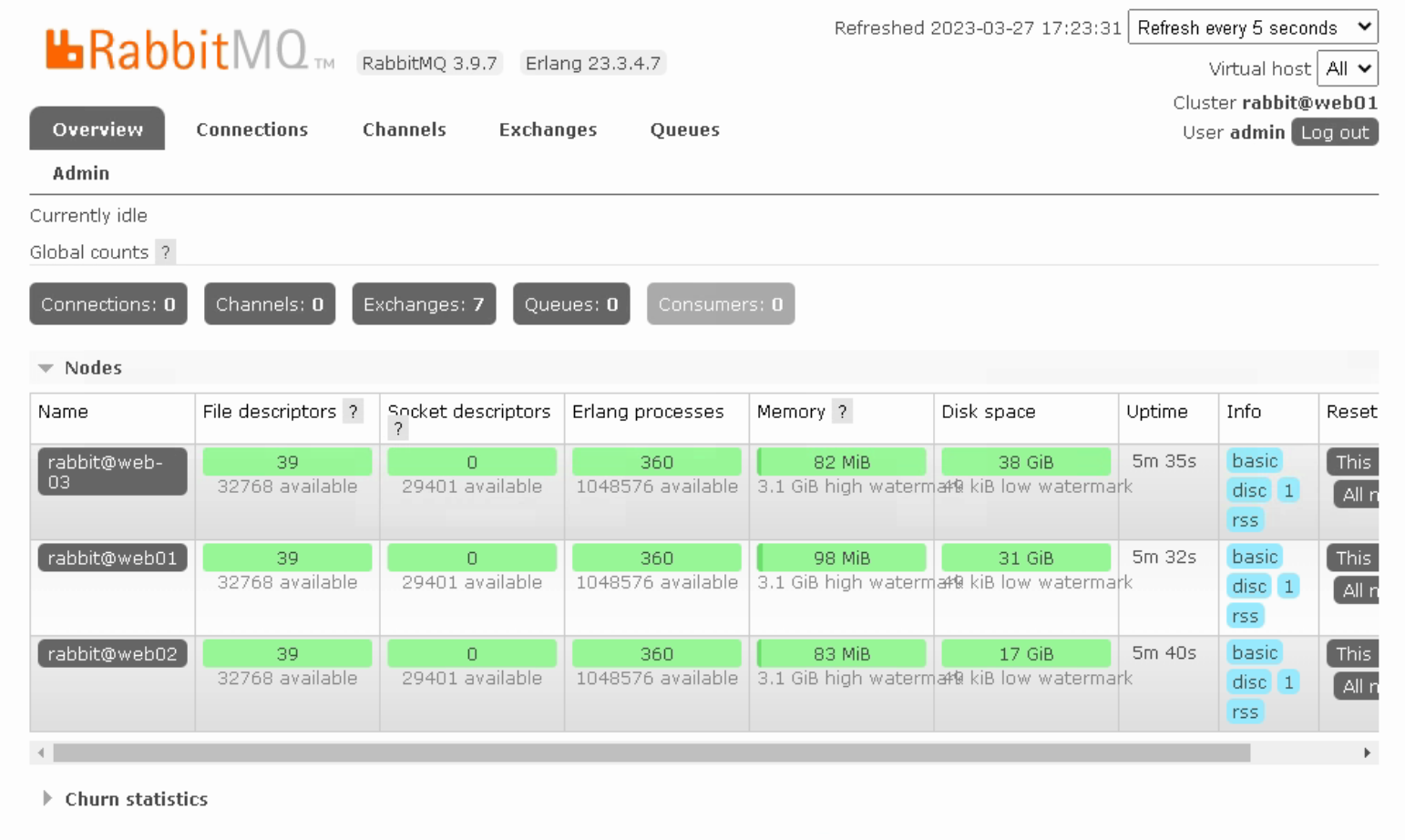
如何删除节点?
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app安装Haproxy 并修改配置文件
需要在VIP 192.168.31.101节点安装
yum install -y haproxy修改配置文件,我这边使用一主一备进行演示,另外一台节点作为备份节点,不参与集群主备变更
- 修改Haproxy ip
- 修改RabbitMQ 节点ip
[root@ops ~]# cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local0 info
# 服务器最大并发连接数;如果请求的连接数高于此值,将其放入请求队列,等待其它连接被释放;
maxconn 5120
# chroot /tmp
# 指定用户
uid 149
# 指定组
gid 149
# 让haproxy以守护进程的方式工作于后台,其等同于“-D”选项的功能
# 当然,也可以在命令行中以“-db”选项将其禁用;
daemon
# debug参数
quiet
# 指定启动的haproxy进程的个数,只能用于守护进程模式的haproxy;
# 默认只启动一个进程,
# 鉴于调试困难等多方面的原因,在单进程仅能打开少数文件描述符的场景中才使用多进程模式;
# nbproc 20
nbproc 1
pidfile /var/run/haproxy.pid
defaults
log global
# tcp:实例运行于纯TCP模式,第4层代理模式,在客户端和服务器端之间将建立一个全双工的连接,
# 且不会对7层报文做任何类型的检查;
# 通常用于SSL、SSH、SMTP等应用;
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
# contimeout 5s
timeout connect 5s
# 客户端空闲超时时间为60秒则HA 发起重连机制
timeout client 60000
# 服务器端链接超时时间为15秒则HA 发起重连机制
timeout server 15000
listen rabbitmq_cluster
# VIP,反向代理到下面定义的三台Real Server
bind 192.168.31.101:25672
# 配置TCP模式
mode tcp
# 简单的轮询
balance roundrobin
# rabbitmq集群节点配置
# inter 每隔五秒对mq集群做健康检查,2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制
server rabbitmqNode1 192.168.31.70:5672 check inter 5000 rise 2 fall 2
server rabbitmqNode2 192.168.31.71:5672 check inter 5000 rise 2 fall 2
server rabbitmqNode3 192.168.31.72:5672 check inter 5000 rise 2 fall 2
# 新增代理RabbitMQ_web
listen rabbitmq_cluster_web
bind 192.168.31.101:15673
mode tcp
balance roundrobin
server rabbitmqNode1 192.168.31.70:15672 check inter 5000 rise 2 fall 2
server rabbitmqNode2 192.168.31.71:15672 check inter 5000 rise 2 fall 2
server rabbitmqNode3 192.168.31.72:15672 check inter 5000 rise 2 fall 2
# 配置haproxy web监控,查看统计信息
listen stats
bind 192.168.31.101:9000
mode http
option httplog
# 启用基于程序编译时默认设置的统计报告
stats enable
# 设置haproxy监控地址为http://node1:9000/rabbitmq-stats
stats uri /rabbitmq-stats
# 每5s刷新一次页面
stats refresh 5s启动服务
[root@ops ~]# systemctl start haproxy
[root@ops ~]# systemctl status haproxy
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2023-03-30 16:25:49 CST; 2s ago
Main PID: 24705 (haproxy-systemd)
CGroup: /system.slice/haproxy.service
├─24705 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid
├─24706 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
└─24707 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
Mar 30 16:25:49 ops systemd[1]: Started HAProxy Load Balancer.
Mar 30 16:25:49 ops systemd[1]: Starting HAProxy Load Balancer...
Mar 30 16:25:49 ops haproxy-systemd-wrapper[24705]: haproxy-systemd-wrapper: executing /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds访问9000监控页面
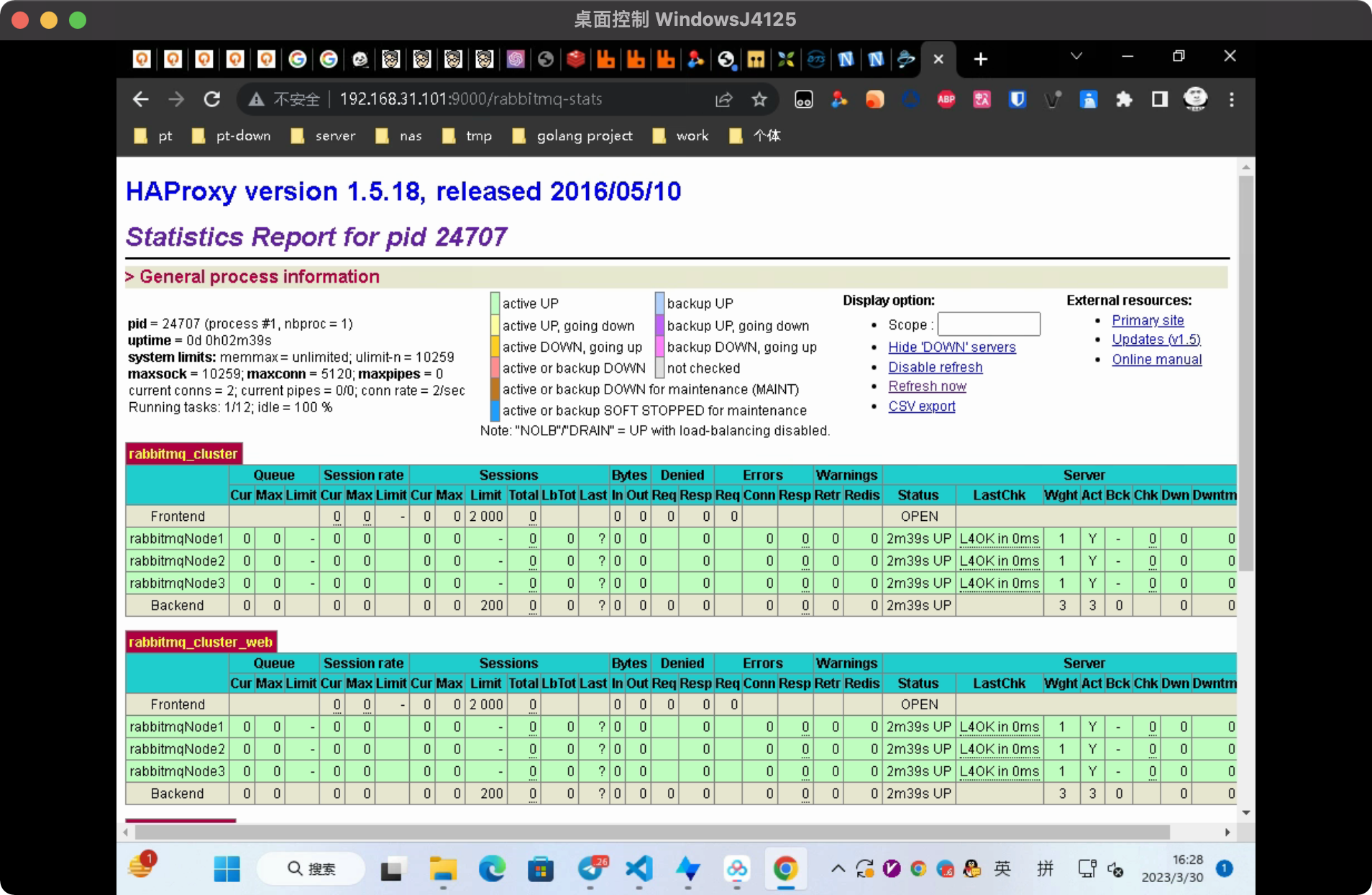
访问VIP:15673 查看RabbitMQ web节点ip是否正常
测试高可用
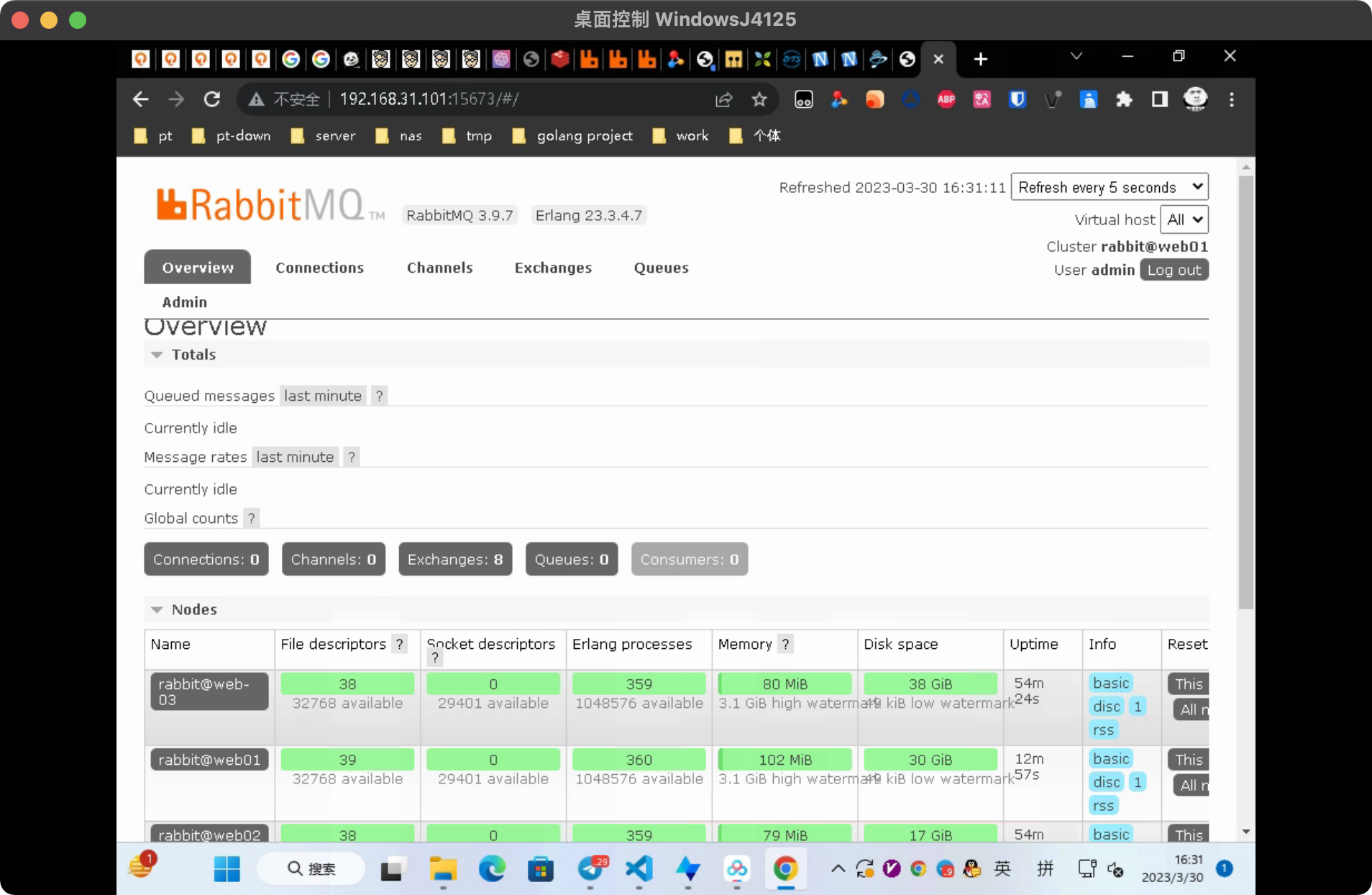
目前我们可以看到集群主节点是web-02
[root@web02 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@web02 ...
Basics
Cluster name: rabbit@web02
Disk Nodes #磁盘节点,没有磁盘节点无法写入数据
rabbit@web-03
rabbit@web02
RAM Nodes #内存节点
rabbit@web01
Running Nodes
rabbit@web-03
rabbit@web01
rabbit@web02
Versions
rabbit@web-03: RabbitMQ 3.9.7 on Erlang 23.3.4.7
rabbit@web01: RabbitMQ 3.9.7 on Erlang 23.3.4.7
rabbit@web02: RabbitMQ 3.9.7 on Erlang 23.3.4.7
Maintenance status
Node: rabbit@web-03, status: not under maintenance
Node: rabbit@web01, status: not under maintenance
Node: rabbit@web02, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners创建信道测试
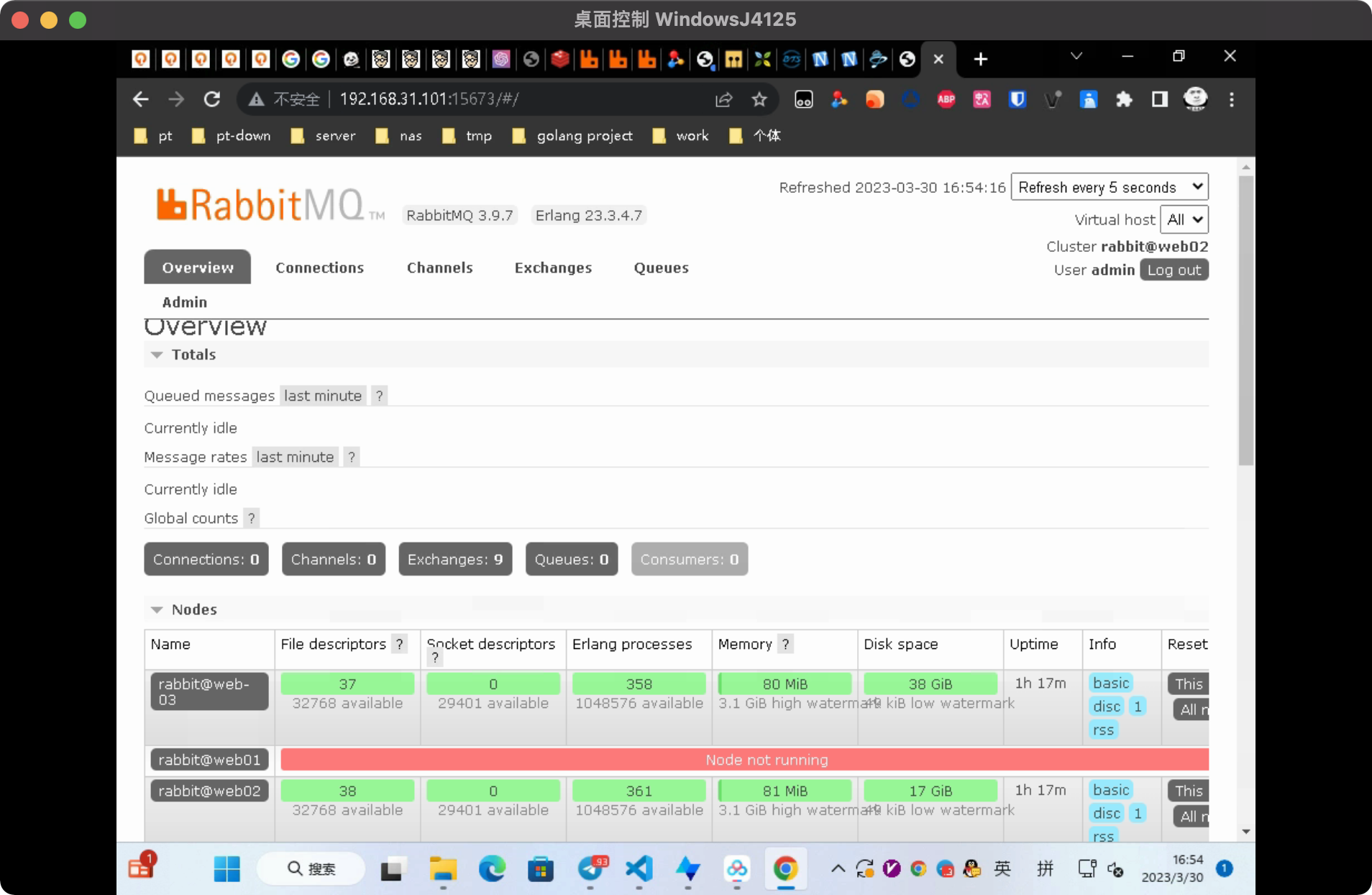
停止一台内存节点
[root@web01 ~]# systemctl stop rabbitmq-server
数据并不受影响
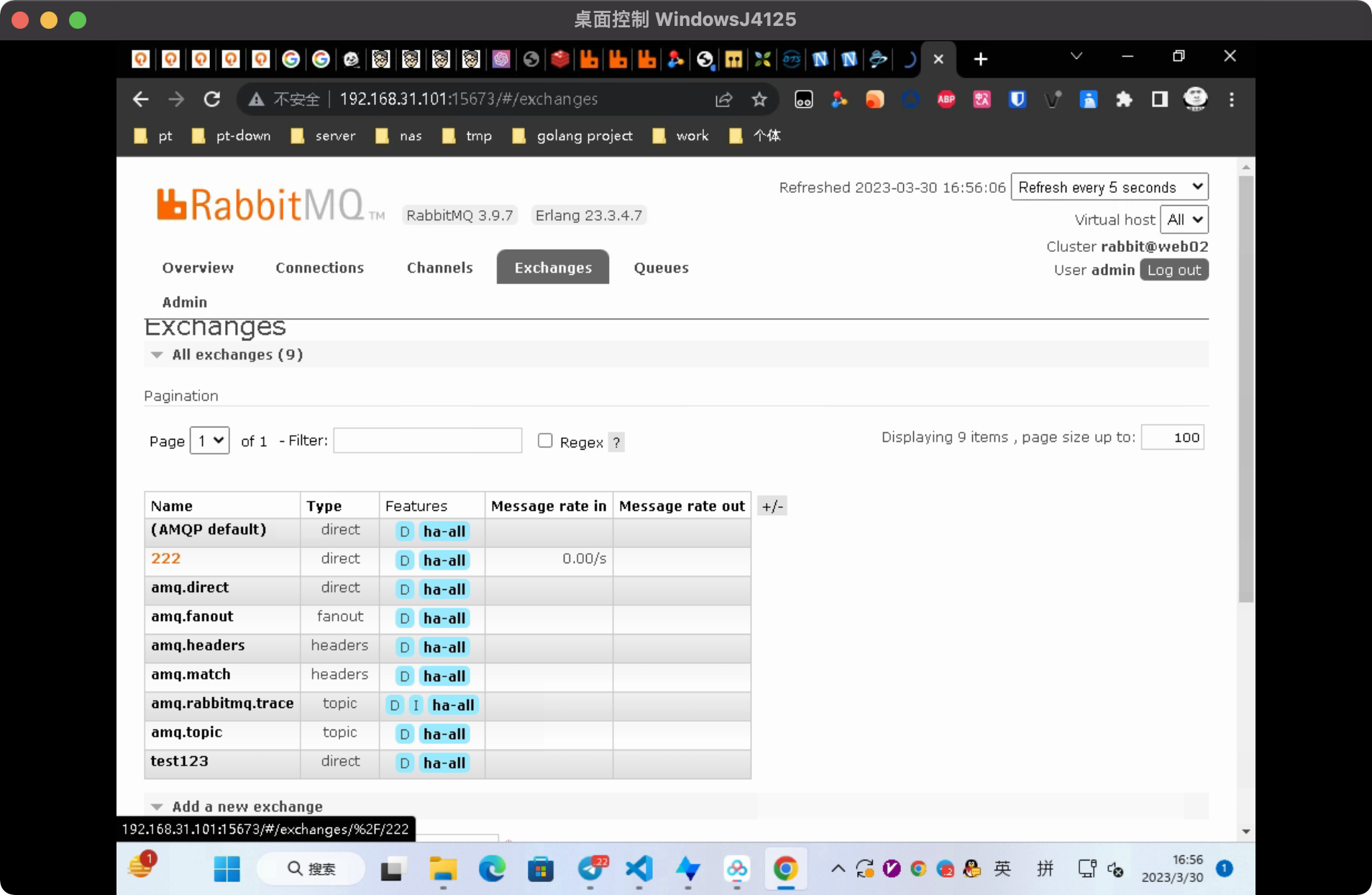
集群镜像
队列高可用,镜像集群配置
-
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
-
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。保证各个节点之间数据同步;
Policy(各节点均会同步)
RabbitMQ提供ha-mode和ha-params(可选),组合情况如下:
| ha-mode | Ha-params | 结果 |
|---|---|---|
| all | absent | 队列镜像到集群内所有节点,新节点加入集群时,队列将被镜像到那个节点 |
| exactly | count | 队列镜像到集群内指定数量的节点,如果集群内节点数少于此数,而且一个包含镜像的 |
| nodes | node names | 队列镜像到指定节点,如果任何指定节点不在集群中,都不会产生错误,当队列声明 |
三台rabbitmq相同操作
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
